Библия Nutanix

Авторские права (c) 2018: Библия Nutanix и NutanixBible.com, 2018. Несанкционированное использование и/или копирование этого материала без письменного разрешения автора и / или владельца этого блога строго запрещено. Выдержки и Ссылки могут быть использованы при условии, что Стивену Пойтрасу и NutanixBible.com будет предоставлена вся информация о факте, целях и назначении их использования с обязательной отсылкой к оригинальному содержимому сайта.
От переводчика: С тех пор, как я перевел первую версию Библии Nutanix прошло немало времени и старый перевод устарел. Я принял решение освежить его. В этот раз я постараюсь поддерживать его в актуальном состоянии и своевременно исправлять недочеты перевода.
Отзывы, предложения и опечатки отправляйте на адрес: avarlamov@protonmail.com
Локализованные версии:




Версия в формате PDF доступна на английском языке (В данной версии могут отсутствовать последние изменения):

Предисловие

Дирай Пандей, CEO, Nutanix
Для меня большая честь писать предисловие к этой книге, которую мы зовем Библия Nutanix. В первую очередь, я хотел бы обратиться к названию этой книги, которое может показаться некоторым людям не вполне уместным по отношению к их вероисповеданию, а также к агностикам и атеистам. Согласно словарю Мериам Вебстер значение слова "библия" не подразумевает по собой Писание как таковое: "выдающаяся публикация, имеющая авторитет у широкой читательской аудитории". Именно так и следует интерпретировать его корни. Данный материал был написан одним их самых скромных и сведущих сотрудников компании Nutanix - Стивеном Пойтрасом, нашим первым Архитектором решений, который является очень авторитетным, при этом, не кичась статусом одного из первых сотрудников компании. Знания не были для него его собственной прерогативой, наоборот - постоянный обмен и распространение знаний делает его чрезвычайно влиятельным в этой компании. Стив олицетворяет культуру этой компании, помогает сотрудникам делясь своей глубокой компетенцией, помогая автоматизировать задачи коллег при помощи Power Shell или Python, создавая прекрасное описание архитектуры (тут важно отметить прекрасный баланс между формой и содержанием), а так же помогая всем, кто нуждается в его помощи в реальном времени в Yammer и Twitter, сохраняя прозрачность перед инженерами, говоря о необходимости самокритики и самосовершенствования, о необходимости быть амбициозным.
Когда Стив решил написать этот блог его мечтой было стать лидером, со всей прозрачностью, создать сторонников в отрасли, кто будет помогать приходить к компромиссным решениям в дизайне продукта. Открытие таких подробностей огромная редкость для компаний, никто не рассказывал столько сколько Стив в своем блоге. Даже Open Source компании, которые выглядят прозрачно на первый взгляд, никогда не раскрывают подробности о том, как их продукт работает. Мы же считаем, что, когда наши конкуренты знают о слабостях нашего продукта и архитектуры — это делает нас сильнее, не остается секретов. Публичная критика или обсуждение слабых мест архитектуры в кратчайшее время приводит в Yammer всю компанию, где мы пытаемся понять - является ли отмеченный недостаток недостатком, так наш продукт становится лучше. В этом сила честного общения с партнерами и клиентами.
Этот постоянно совершенствующийся артефакт, помимо авторитета, имеет широчайшую читательскую аудиторию во всем мире. Архитекторы, менеджеры и ИТ-директора, останавливали меня в конференц-залах, чтобы поговорить о том, насколько прозрачен стиль письма, с подробными иллюстрациями, фигурами для visio и схемами. Стив потратил много времени, чтобы рассказать историю web-scale архитектуры, не навешивая ярлыков. Популяризировать нашу распределенную архитектуру было непросто, в мире, где ИТ-специалисты завалены решением "неотложных" задач и проблем. Библия позволяет сократить разрыв между ИТ и DevOps, она объясняет самые сложные вещи из глубин ИТ простыми словами. Мы надеемся, что в ближайшие 3-5 лет ИТ станет использовать простые термины, и приблизится к Web-Scale DevOps.
С первым изданием мы превращаем блог Стивена в книгу. День, когда мы перестанем обновлять этот материал, станет началом конца этой компании. Я ожидаю, что каждый из вас будет продолжать напоминать нам о том, что привело нас к сюда: правда, только правда и ничего кроме правды освободит вас (от самодовольства и гордыни).
Будьте честными.
--Дирай Пандей, CEO, Nutanix

Стюарт Минимэн, Главный Научный Сотрудник, Wikibon
Сегодня пользователи каждый день сталкиваются с новыми технологиями. У сферы ИТ нет пределов для совершенствования, однако принятие обществом новых технологий, и тем более - изменение каких-либо привычных процессов и операций дело сложное и непростое. Быстрый рост технологий с открытым исходным кодом, например, сдерживается отсутствием полноценной документации. В качестве попытки борьбы с этой проблемой был реализован проект Wikibon. Библия Nutanix, начинавшаяся как блог Стивена Пойтраса со временем стала ценным источником информации для ИТ-специалистов, которые хотят узнать о принципах гиперконвергентной и web-scale архитектуры, поглубже погрузиться в особенности архитектуры гипервизора и платформы Nutanix. Концепции, о которых пишет Стив — это передовые технологии и решения, которые создаются одними из лучших инженеров отрасли. В этой книге сложные понятия описаны доступным языком, понятным широкому кругу читателей, и при этом без ущерба техническим подробностям.
Концепция распределенных систем и программно-определяемой инфраструктуры являются самой передовой на текущий момент, это очень важно донести до всех ИТ-специалистов. Я призываю прочитать эту книгу всех, кто хочет понять, что скрывается под этой концепцией. Технологии описанные здесь являются основой самых крупных центров обработки данных в Мире.
--Стюарт Минимэн, Главный Научный Сотрудник, Wikibon
Введение

Стивен Пойтрас, Главный архитектор решений, Nutanix
Добро пожаловать в Библию Nutanix! Я работаю с платформой Nutanix на постоянной основе – пытаюсь выявить проблемы, увеличить допустимые максимумы, а также администрирую платформу в своей лаборатории. Этот материал я задумывал, как документ, который будет содержать советы и приемы по работе с решениями компании от меня и инженеров, которые работают с платформой каждый день.
Примечание: Данный материал позволяет взглянуть на платформу изнутри и получить представление как все устроено. Для успешной работы с Nutanix Вам не потребуется глубоких знаний по всем упомянутым в данном материале темам.
Наслаждайтесь!
--Стивен Пойтрас, Главный архитектор решений, Nutanix
Часть I. Краткий экскурс в историю
Краткий обзор истории ИТ-инфраструктуры и предпосылок которые привели нас туда, где мы находимся сейчас.
Эволюция центров обработки данных
Центры обработки данных очень изменились за последние несколько десятков лет. В следующих разделах мы рассмотрим каждую эру.
Эра мейнфреймов
Мейнфремы правили в ЦОД в течение многих лет и заложили основу большинства современных технологий. Мейнфремы обеспечивали:
- Встроенный конвергентный процессор, оперативную память, и хранилище
- Резервирование на аппаратном уровне
Однако, имели следующие недостатки:
- Высокая стоимость инфраструктуры
- Чрезмерная сложность
- Недостаточная гибкость
Переход на классические серверы
Использование мейнфреймов было слишком дорогим и сложным для бизнеса, и это стало причиной появления классических серверов шириной 19". Их основные особенности:
- Центральный процессор, оперативная память, локальные диски
- Большая гибкость, чем у мейнфреймов
- Сетевые интерфейсы и доступ по сети
Такие серверные решения несли за собой следующие минусы:
- Увеличение количества оборудования
- Низкий уровень утилизации оборудования
- Каждый сервер становился единой точкой отказа, как для хранилища так и для вычислений
Централизованное хранилище
Основная задача бизнеса - заработок денег, и данные являются одним из ключевых инструментов. Когда организации используют классические хранилища - им всегда требуется больше емкости и обеспечении высокой доступности данных, чтобы выход из строя сервера не приводил к их потере.
Так классические СХД заменили локальные емкости серверного оборудования и мейнфреймов, обеспечив сохранность данных. Их основные характеристики:
- Объединенные ресурсы хранения и их эффективное использование
- Централизованная защита данных при помощи технологии RAID
- Доступ к данным по сети
Вот некоторые недостатки, которые привнесли классические выделенные хранилища:
- Классические СХД являются дорогостоящими, однако данные дороже
- Выросла сложность инфраструктуры (Фабрики SAN, адресация WWPN, RAID-группы, тома, количество шпинделей и так далее)
- Требуется использовать специальное ПО и команду
Внедрение виртуализации
Виртуализация позволила увеличить плотность вычислений запуская несколько разнородных задач в рамках одного классического сервера. Виртуализация помогла Бизнесу утилизировать их оборудование, но увеличила последствия выхода оборудования из строя.
Основные характеристики виртуализации:
- Позволяет перенести вычисления на уровень выше от оборудования - создать виртуальные машины
- Очень эффективное использование вычислительных ресурсов и консолидация нагрузок
Виртуализация привнесла следующие вопросы:
- Количество оборудования выросло, управление ими усложнилось
- Без технологий HA отказ сервера приводил к влиянию на большее количество сервисов
- Отсутствие общих ресурсов
- Снова требовалась отдельная команда и специальное ПО
Развитие виртуализации
Гипервизоры стали функциональным и эффективным решением. С появлением технологий VMware vMotion, HA, и DRS, пользователи получили возможность обеспечивать HA для ВМ и динамически распределять нагрузку на оборудование. Однако централизованное хранилище все еще являлось проблемой - конкуренция ВМ за ресурсы увеличивало нагрузку на хранилища.
Ключевые характеристики:
- Кластеризация привела к объединению вычислительных ресурсов
- Появилась возможность динамического перераспределения нагрузки (DRS / vMotion)
- Высокая доступность ВМ позволяла сохранить работоспособность ПО при выходе из строя аппаратного сервера
- Требовалось использовать централизованное хранилище
Вопросы:
- Увеличились требования к производительности централизованного хранилища
- Требования к хранилищу снова увеличивали количество оборудования
- Вместе с производительностью хранилища выросла и стоимость хранения
- Конкуренция за ресурсы хранения влияла на производительность
- Все это делало конфигурацию хранилища еще сложнее, требовалось следить за:
- количеством ВМ использующих хранилище и томов созданных на СХД
- количеством шпинделей, чтобы обеспечивать приемлемую производительность
Твердотельные накопители
SSD помогли устранить узкое место в I/O, обеспечивая гораздо более высокую производительность без необходимости добавлять и добавлять шпиндели. Однако, контроллеры и сеть все еще не были готовы к такой производительности.
Ключевые характеристики:
- Гораздо более высокие характеристики I/O, чем у HDD
- Время отклика сильно сократилось
Вопросы:
- Узкое место переместилось с уровня хранилища на уровень контроллеров и сетей
- Количество оборудования все еще было велико
- Сложность конфигурации СХД сохранялась
Пришествие облаков
Термин Облако можно трактовать по-разному. Одним словом — это возможность предоставлять расположенный где-то сервис пользователям, которые расположены где-то еще.
С появлением облаков изменились перспективы ИТ, Бизнеса и конечных пользователей.
Бизнес требует от ИТ, чтобы ресурсы предоставлялись по облачной модели - как можно быстрее. Если это не происходит - Бизнес уходит непосредственно в облака и сталкивается там с проблемами безопасности.
Основные столпы любого облачного сервиса:
-
Самообслуживание / Получение ресурсов по требованию
- Быстрая окупаемость / низкий порог входа
-
Фокус на сервисе и SLA
- Гарантии времени работы, уровня доступности, производительности
-
Гранулярная модель потребления
- Плати за то, что используешь. При этом некоторые сервисы могут быть бесплатными
Классификация облаков
Облака могут быть разделены на три основных типа:
-
ПО как сервис (SaaS)
- Любое ПО или услуга доступные через url
- Примеры: Workday, Salesforce.com, Google search, etc.
-
Платформа как сервис (PaaS)
- Платформа для разработки и размещения приложений
- Примеры: Amazon Elastic Beanstalk / Relational Database Services (RDS), Google App Engine, и так далее
-
Инфраструктура как сервис (IaaS)
- Виртуальные машины/Контейнеры/Вируализация сетевых функций
- Примеры: Amazon EC2/ECS, Microsoft Azure, Google Compute Engine (GCE), и так далее
Сдвиг фокуса в области ИТ
Облака ставят перед ИТ интересный вопрос - ответом на который может стать использование внешних облачных платформ/провайдеров или же обеспечение какой-то альтернативы им. При этом, все хотят сохранить свои бизнес-данные внутри компании, предложить пользователям удобный портал самообслуживания и высокую скорость развертывания сервисов.
То есть, сдвиг фокуса в сторону облачных сервисов толкает ИТ к тому, чтобы стать "облачным" сервис-провайдером для собственных конечных пользователей (сотрудников компании).
Важность задержек при работе с данными
В таблице ниже приведены задержки для разных типов I/O:
| Операция | Задержка | Комментарии |
|---|---|---|
| Доступ к кэшу первого уровня | 0.5 ns | |
| Доступ к кэшу второго уровня | 7 ns | 14x L1 cache |
| Доступ к DRAM | 100 ns | 20x L2 cache, 200x L1 cache |
| 3D XPoint на основе чтения NVMe SSD | 10,000 of ns (ожидаемо) | 10 us or 0.01 ms |
| NAND NVMe SSD R/W | 20,000 ns | 20 us or 0.02 ms |
| NAND SATA SSD R/W | 50,000-60,000 ns | 50-60 us or 0.05-0.06 ms |
| Случайное чтение блоков 4K с SSD | 150,000 ns | 150 us or 0.15 ms |
| Задержка P2P TCP/IP (физика на физику) | 150,000 ns | 150 us or 0.15 ms |
| Задержка P2P TCP/IP (ВМ на ВМ) | 250,000 ns | 250 us or 0.25 ms |
| Последовательное чтение 1MB из памяти | 250,000 ns | 250 us or 0.25 ms |
| В среднем по ЦОД | 500,000 ns | 500 us or 0.5 ms |
| Последовательное чтение 1MB с SSD | 1,000,000 ns | 1 ms, 4x memory |
| Поиск диска | 10,000,000 ns или 10,000 us | 10 ms, 20x от среднего по ЦОД |
| Последовательное чтение 1MB с диска | 20,000,000 ns or 20,000 us | 20 ms, 80x memory, 20x SSD |
| Отправлка пакетов Калифорния -> Нидерланды -> Калифорния | 150,000,000 ns | 150 ms |
(автор: Джефф Дин, https://gist.github.com/jboner/2841832)
Таблица показывает, что ЦПУ может получить доступ к КЭШ в среднем за ~0.5-7ns (L1 vs. L2). Для основной памяти ~100ns, когда локальное чтение 4K SSD ~150,000ns или же 0.15ms.
Если мы возьмем для примера стандартные SSD уровня предприятия (в нашем случае Intel S3700 - SPEC), то сможем получить:
- Производительность случайных операций I/O:
- Случайное чтение, блоки по 4K: до 75,000 IOPS
- Случайная запись, блоки по 4K: до 36,000 IOPS
- Пропускная способность при последовательных операциях I/O:
- Последовательное чтение: до 500MB/s
- Последовательная запись: до to 460MB/s
- Задержки:
- Чтение: 50us
- Запись: 65us
Поговорим о пропускной способности
Классические СХД используют две пары основных видов транспорта I/O:
- SAN (FC)
- 4-, 8-, 16- и 32-Gb
- LAN (включая FCoE)
- 1-, 10-Gb, (40-Gb IB), и т.д.
Для расчетов, приведенных ниже мы используем пропускную способность 500MB/s для чтения и 460MB/s для записи на базе Intel S3700.
Расчет производится следующим образом:
numSSD = ROUNDUP((numConnections * connBW (in GB/s))/ ssdBW (R or W))
Примечание: Полученные значения были округлены. А также мы не берем в расчет ЦПУ, предполагая что у него нет ограничений
| Пропускная способность сети | Количество SSD необходимых для утилизации канала | ||
|---|---|---|---|
| Тип подключения контроллера | Доступная пропускная способность | I/O чтения | I/O записи |
| Двойной 4Gb FC | 8Gb == 1GB | 2 | 3 |
| Двойной 8Gb FC | 16Gb == 2GB | 4 | 5 |
| Двойной 16Gb FC | 32Gb == 4GB | 8 | 9 |
| Двойной 32Gb FC | 64Gb == 8GB | 16 | 19 |
| Двойной 1Gb ETH | 2Gb == 0.25GB | 1 | 1 |
| Двойной 10Gb ETH | 20Gb == 2.5GB | 5 | 6 |
Из таблицы видно, что если вы хотите использовать SSD на максимум, то сеть может быть узким местом при появлении 1-9 таких дисков, в зависимости от типа сети
Задержки при работе с памятью
Стандартная задержка при работе с памятью ~100ns, значит можно выполнить следующие расчеты:
- Задержка при доступе к локальной памяти = 100ns + [накладные расходы на ОС / гипервизор]
- Задержка при чтении из памяти по сети = 100ns + задержки RTT + [2 x накладные расходы на ОС / гипервизор]
Если принять, что RTT для стандартной сети равен ~0.5ms (может отличаться в зависимости от производителя оборудования) т.е. ~500,000ns, то:
- Задержка при чтении из памяти по сети = 100ns + 500,000ns + [2 x накладные расходы на ОС / гипервизор]
Если мы предположим, что имеем очень быструю сеть с RTT = 10,000ns, то:
- Задержка при чтении из памяти по сети = 100ns + 10,000ns + [2 x накладные расходы на ОС / гипервизор]
Т.е. даже при наличии сверхбыстрой сети мы имеем 10,000% накладных расходов по сравнению с локальной памятью. Если сеть медленная то, накладные расходы могут увеличится до 500,000%.
Чтобы эти накладные расходы как-то нивелировать, используется кэширование данных
Пространство пользователей и ядра
Одной из самых жарких и часто обсуждаемых тем является обсуждение плюсов и минусов использования пользовательского пространства и пространства ядра операционной системы. Тут я остановлюсь на плюсах и минусах этих подходов.
Все операции ОС выполняются в двух основных пространствах:
-
Пространство ядра
- Наиболее привилегированная часть ОС
- Управление задачами, памятью и так далее
- Работают драйверы и происходит управление оборудованием
-
Пространство пользователя
- Стандартное пространство для запуска пользовательских процессов
- Тут функционируют почти все процессы
- Память на этом уровне защищена, происходит выполнение процессов
Оба этих пространства позволяют ОС функционировать.Теперь давайте определим несколько ключевых элементов:
-
Системный вызов
- Или же - вызов ядра, который осуществляется через прерывание из активного процесса
-
Переключение контекста
- Перенос выполнения между ядром и процессом
Например рассмотрим, как осуществляеся запись данных приложением на диск:
- Приложение хочет записать данные на диск
- Осуществляется вызов системного вызова
- Контекст переключается на ядро
- Ядро осуществляет копирование
- Осуществляется запись на диск с использованием драйвера
Схема взаимодействия:
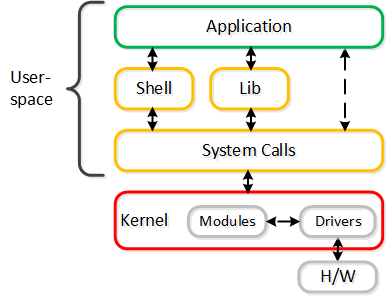
Одно пространство лучше другого? В реальности есть следующие плюсы и минусы:
-
Пространство пользователя
- Очень гибкое
- Изолированные домены (сервисы)
- Может быть неэффективным
- Переключение контекстов требует времени(~1,000ns)
-
Пространство ядра
- Очень жесткое
- Один большой домен
- Может быть эффективным
- Меньше переключений контекста
Опрос против прерываний
Еще одним ключевым моментом является тип взаимодействия между пространствами:
-
Опрос
- Постоянный опрос - непрерывный запрос какой-то информации
- Пример: движение мышки, частота обновления монитора и так далее
- Постоянный расход процессорного времени
- Исключает использование обработчика прерываний ядра, низкие задержки
- Исключает контекстный переключатель
- Прерывания
- Периодические запросы ресурсов
- Пример: Студент поднимает руку, чтобы задать вопрос
- Может быть более эффективным, но не всегда
- Обычно задержка намного выше, чем при опросе
Пространство пользователя
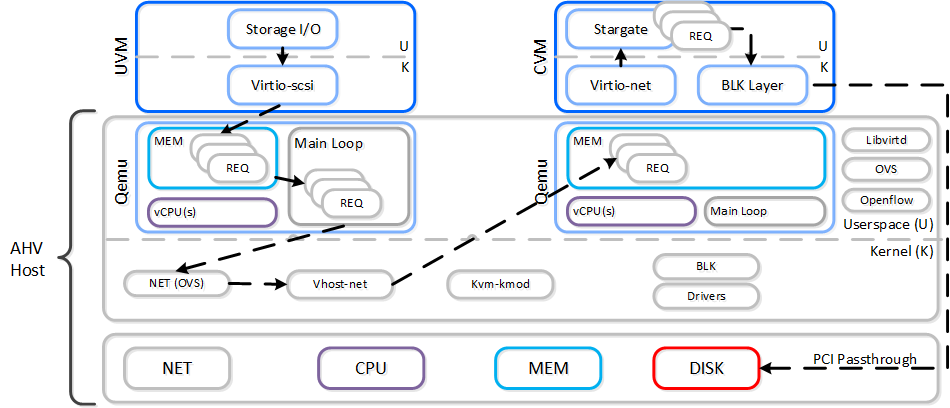
Чем быстрее устройство (например: NVMe, Intel Optane, pMEM), тем более узким местом становится процесс взаимодействия ядра и устройства. Чтобы как-то решить эту проблему, многие производители переносят задачи из пространства ядра в пользовательское пространство и используют механизм опроса, для получения лучших результатов производительности.
Прекрасный пример - Intel Storage Performance Development Kit (SPDK) и Data Plane Development Kit (DPDK). Оба проекта направлены на получение максимальной производительности и сокращение задержек.
Такое перемещение ПО включает следующие изменения:
- Перенос драйверов устройств в пользовательское пространство (вместо пространства ядра)
- Использование механизма опроса (вместо прерываний)
Это обеспечивает большую производительность, потому что устраняет
- Дорогие системные вызовы и управление прерываниями
- Копии данных
- Переключение контекстов
Ниже показан пример взаимодействия устройств с помощью драйверов в пользовательском пространстве:
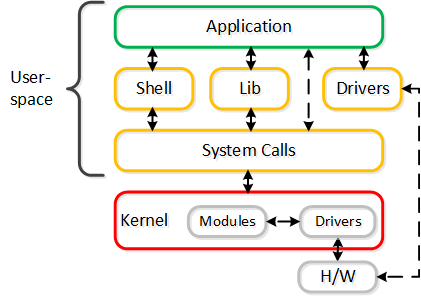
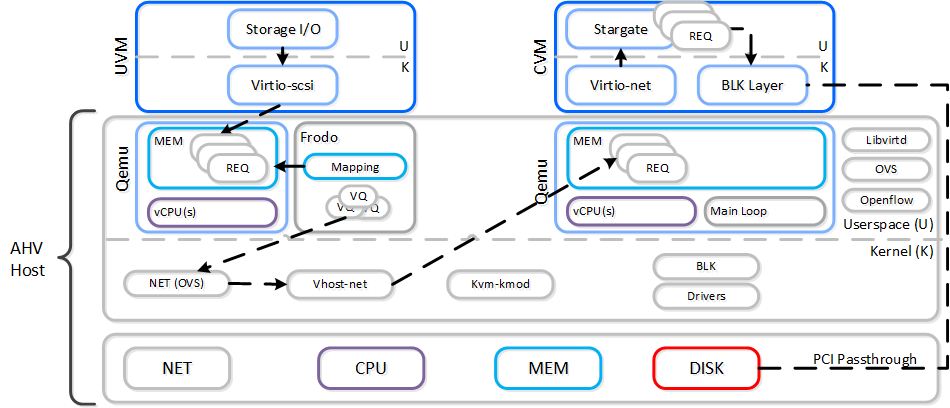
Можно отметить, что часть решений компании Nutanix разработанных для AHV (vhost-user-scsi), используется компанией Intel для проекта SPDK.
Книга Web-Scale
web·scale - /web ' skãl/ - noun - горизонтально масштабируемая архитектура
новый архитектурный подход к реализации инфраструктуры и вычислениям
В этой главе будут представлены основные понятия “Web-scale” инфраструктуры и почему мы используем их. Важно прояснить - использование такой архитектуры не обязывает вас быть размером с Google или Amazon, такая архитектура полезна при любом масштабе инфраструктуры (начиная с трех узлов).
Исторические вызовы:
- Сложность, сложность, сложность
- Стремление к постепенному росту
- Необходимось быть более гибким
Вот основные фишки Web-scale
- Гиперконвергентность
- Программно-определяемые решения
- Распределенные автономные системы
- Постепенное, линейное масштабирование
И еще:
- Автоматизация на базе API, встроенная система аналитики
- Безопасность как основной элемент интегрированный в платформу
- Механизмы автоматического восстановления неисправностей
Эти фишки будут раскрыты более детально чуть ниже по тексту
Гиперконвергентность
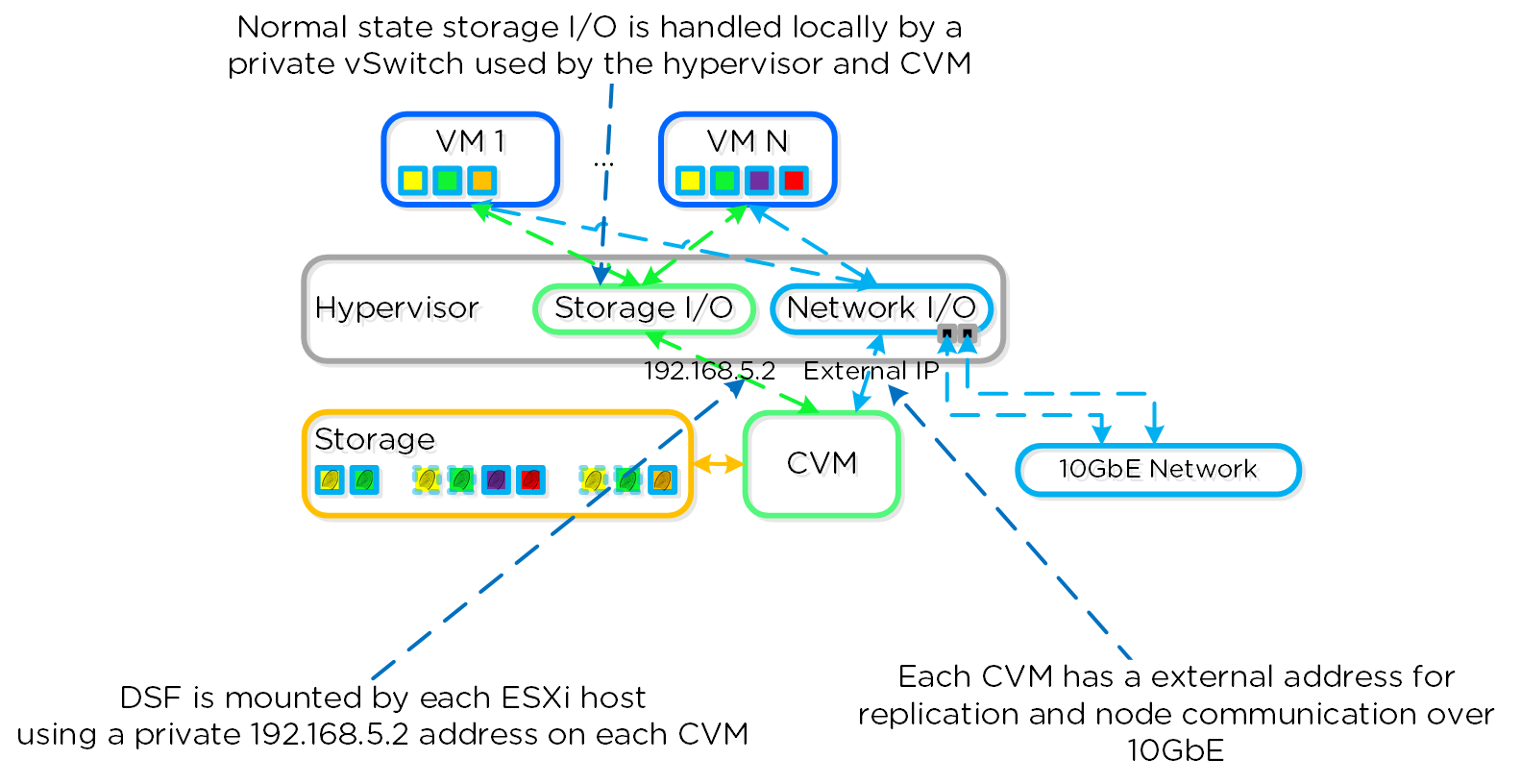
Существует несколько мнений, что же такое Гиперконвергентность Чаще всего это зависит от компонентов, о которых идет речь (например виртуализация, сеть и т.д.). Основная концепция: максимальная интеграция нескольких компонентов в единое решение. Чтобы достичь максимальной интеграции компоненты должны быть доработаны или разработаны именно так, чтобы идеально подходить друг другу. В случае Nutanix мы интегрируем хранилище и вычислительные мощности в узлы, которые являются основой нашего решения. Для других это могут быть, например, хранилище и сеть и так далее.
Итого, гиперконвергентность это:
- Максимальная интеграция двух или более компонент в единое решение, которое может легко масштабироваться
Преимущества:
- Стандартная единица масштабирования
- Локализация операций ввода/вывода
- Исключение классических вычислительных узлов и СХД
Программно-определяемые решения
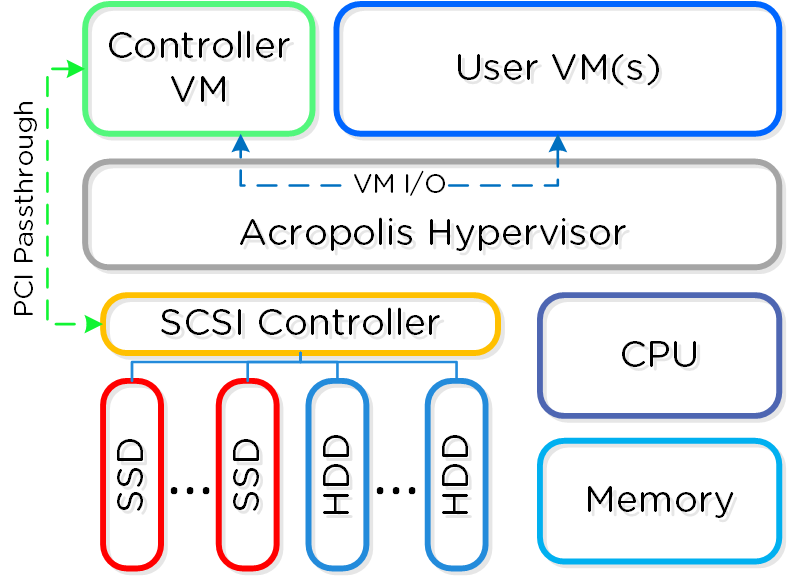
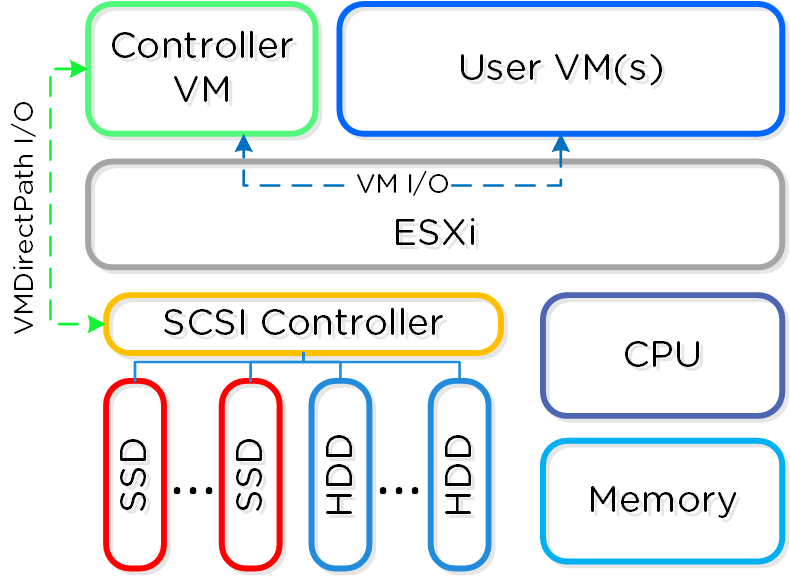
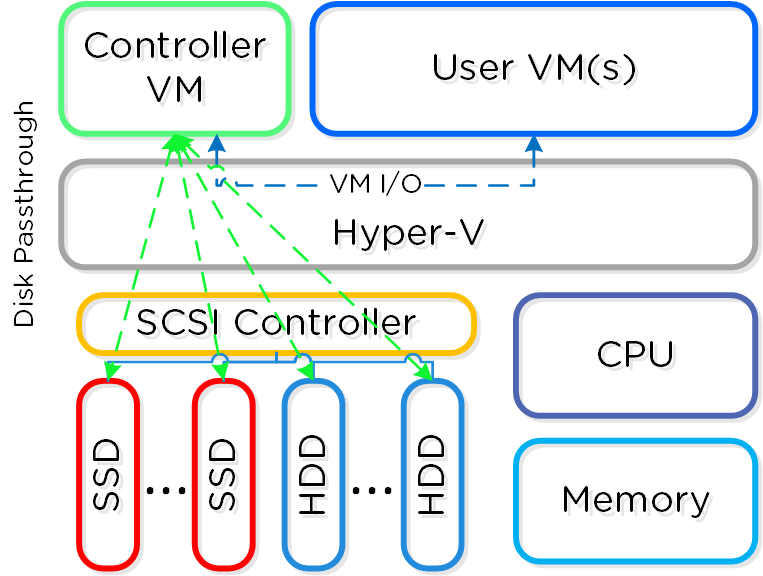
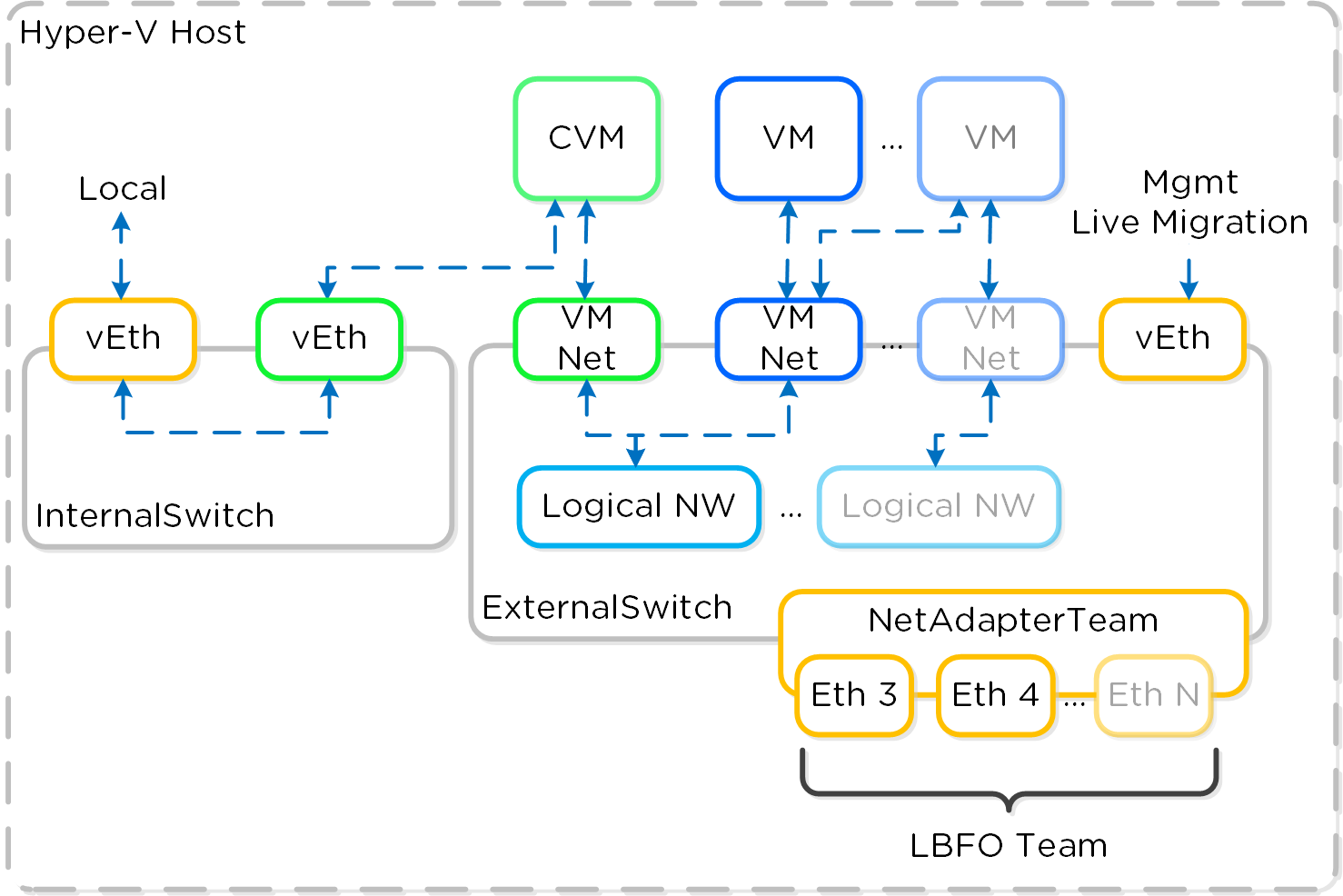
Программно-определяемые решения берут на себя задачи и основную логику, обычно присущую аппаратным компонентам и выполняются в рамках обычного серверного оборудования. В Nutanix мы взяли логику хранилища (RAID, дедупликацию, компрессию, и так далее) и перенесли ее в свое ПО, которое выполняется на каждой CVM - Nutanix Controller VMs
Примечание
Поддерживаемые архитектуры
Решение Nutanix поддерживает x86 и IBM POWER
Что все это означает:
- Мы перенесли ключевую логику с уровня аппаратного обеспечения на уровень ПО, которое может работать на любом серверном оборудовании
Преимущества:
- Быстрый релизный цикл
- Устранение зависимости от оборудования конкретного производителя
- Использование стандартного оборудования дешевле
- Длительный срок службы и защита инвестиций
Уточним последний пункт: старое оборудование может позволять новейшему и самому передовому ПО работать. Т.е. даже на оборудовании, срок службы которого ограничен, будут выходить и прекрасно работать обновления.
Распределенные автономные системы
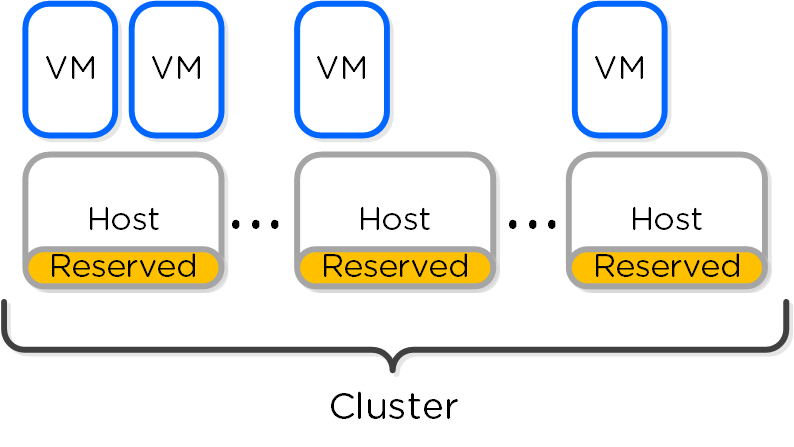
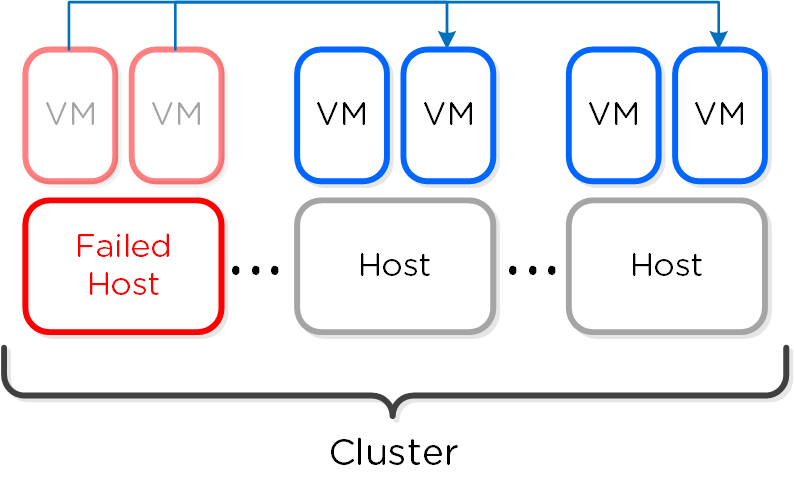
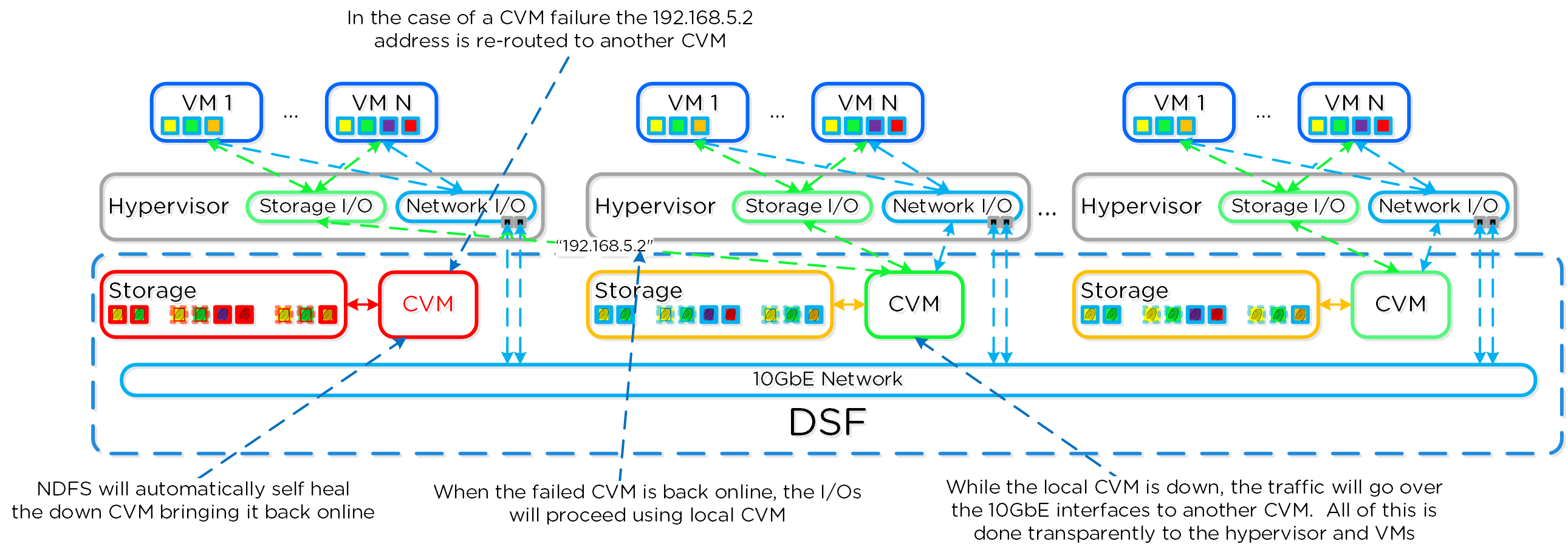
Распределенные автономные системы предполагают отказ от выделения каких-либо ролей и компонентов, вместо этого роль равномерно распределяется между всеми узлами и экземплярами ПО Вы можете представлять себе это, как простую распределенную систему. Классические производители предполагали, что оборудование будет достаточно надежным, и в большинстве случаев так оно и было. Однако, распределенная система по умолчанию предполагает, что оборудование рано или поздно придет в негодность, а ПО решит любую проблему без прерывания сервиса.
Распределённые системы были разработаны так, чтобы решать свои задачи локально на каждом узле, поддерживая при этом работоспособность остального кластера и сервисов функционирующих в его рамках Т.е. если ПО получит сообщение, что какой-то аппаратный или программный компонент сбоит то оно обработает ошибку и продолжит функционировать. Система оповещения сообщить пользователям о событии, и вместо остановки сервиса будет ожидать вмешательства администратора (например, ждать замены узла). При этом администратор, может осуществить переборку кластера без замены компонента. Если же речь идет о экземпляре ПО, которое являлось на данный момент "Мастером", то все еще проще - будет выбран новый мастер и все продолжит функционировать. Для распределения задач между экземплярами ПО используется концепция MapReduce.
Что все это означает:
- Распределение ролей и обязанностей между всеми узлами кластера
- Использование концепции MapReduce для равномерного распределения задач
- Запуск процессов выбора нового Мастера, если это необходимо
Преимущества:
- Исключение любых точек отказа (SPOF)
- Распределение нагрузки, для устранения узких мест
Постепенное, линейное масштабирование
Постепенное, линейное масштабирование предполагает возможность начать работу с минимально необходимым количеством ресурса, добавляя их по мере роста потребностей. Все конструкции, о которых говорилось раньше направлены на реализацию этой функциональности. Обычно существует три уровня компонент - вычислительная подсистема, хранилище и сеть. Все они масштабируются независимо друг от друга. Например, если вы добавляете новых серверов, вы не увеличиваете при этом производительность и емкость хранилища. А с платформой Nutanix вы одновременно масштабируете:
- Количество гипервизоров / вычислительных узлов
- Количество контроллеров хранилища
- Производительность вычислительных узлов / емкость хранилища
- Число узлов, участвующих в операциях в рамках кластера
Что все это означает:
- Возможность постепенно масштабирования хранилища и вычислительных мощностей, с линейным увеличением производительности и доступности.
Преимущества:
- Возможность начать с малого количества ресурсов и масштабироваться до требуемого
- Равномерное и последовательное увеличение производительности
Все это очень важно!
Итого:
- Неэффективное использование вычислительных ресурсов привело к переходу на виртуализацию
- Функции vMotion, HA и DRS привели к необходимости централизованного хранения
- Рост нагрузки на виртуальные машины привел к увеличению нагрузки и конкуренции на хранилище
- SSDs пришли, чтобы исправить ситуацию с производительностью, но сместили узкое место в сторону сети и контроллеров
- Доступ к кэшам и памяти по сети порождает большие накладные расходы, который сводят к минимуму плюсы
- Сложность конфигурации СХД остается прежней
- Кэширование на уровне серверов пришло, чтобы снять нагрузку на хранилище. Однако, это еще один компонент и точка отказа
- Локализация операций с данными позволяет избавится от узких мест и сгладить ситуацию с накладными расходами
- Сдвигается фокус от инфраструктуры к легкости управления, упрощается стек
- Рождается новый мир Web-Scale!
Part II. Книга веб-интерфейса Prism
prism - /'prizɘm/ - noun - панель управления
простой интерфейс для управления всей платформой Nutanix и центром обработки данных.
Методология проектирования
Важнейшей нашей целью является создание красивого, отзывчивого и интуитивного интерфейса. Данный интерфейс является одним из самых важных компонентов платформы Nutanix. Мы относимся к нему очень серьезно. В этом разделе будет рассказано о нашей методологии проектирования, о том, к чему мы движемся. Уже скоро этот раздел будет дополнен!
А пока - почитайте прекрасный пост от создателя этого интерфейса и руководителя направления промышленного дизайна Джереми Салли - http://salleedesign.com/stuff/sdwip/blog/nutanix-case-study/
Фигуры для редактора Visio доступны по ссылке: http://www.visiocafe.com/nutanix.htm
Архитектура
Prism - распределенная система управления, которая позволяет пользователям управлять объектами платформы Nutanix и следить за их состоянием.
Систему управления можно разделить на две основных части:
- Интерфейсы
- HTML5 UI, REST API, CLI, PowerShell CMDlets, и так далее.
- Управление
- Определение и соблюдение политик, разработка и статус услуг, аналитика и мониторинг
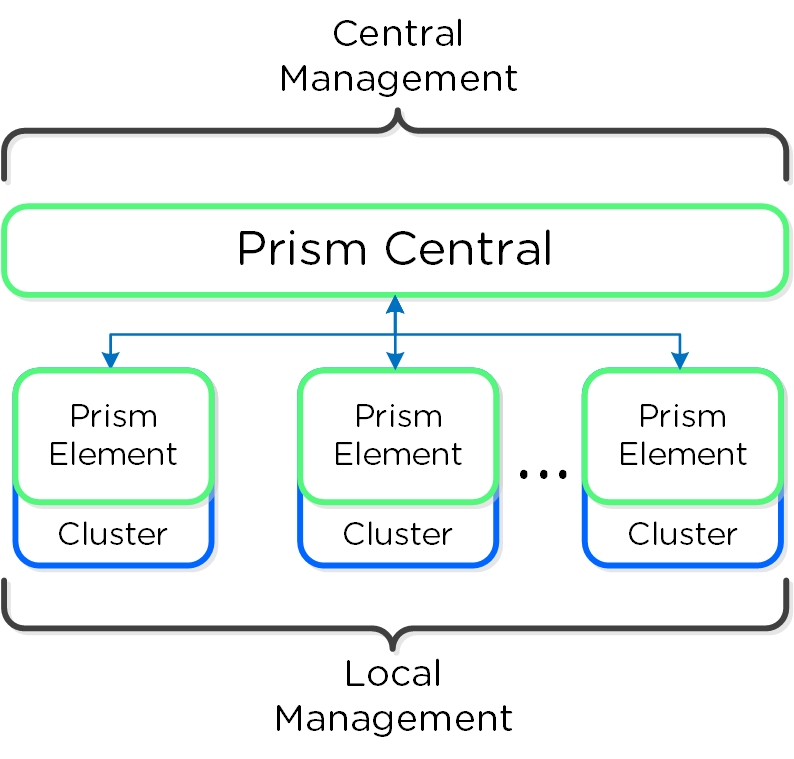
На рисунке изображена компонентная архитектура Prism как части платформы Nutanix:
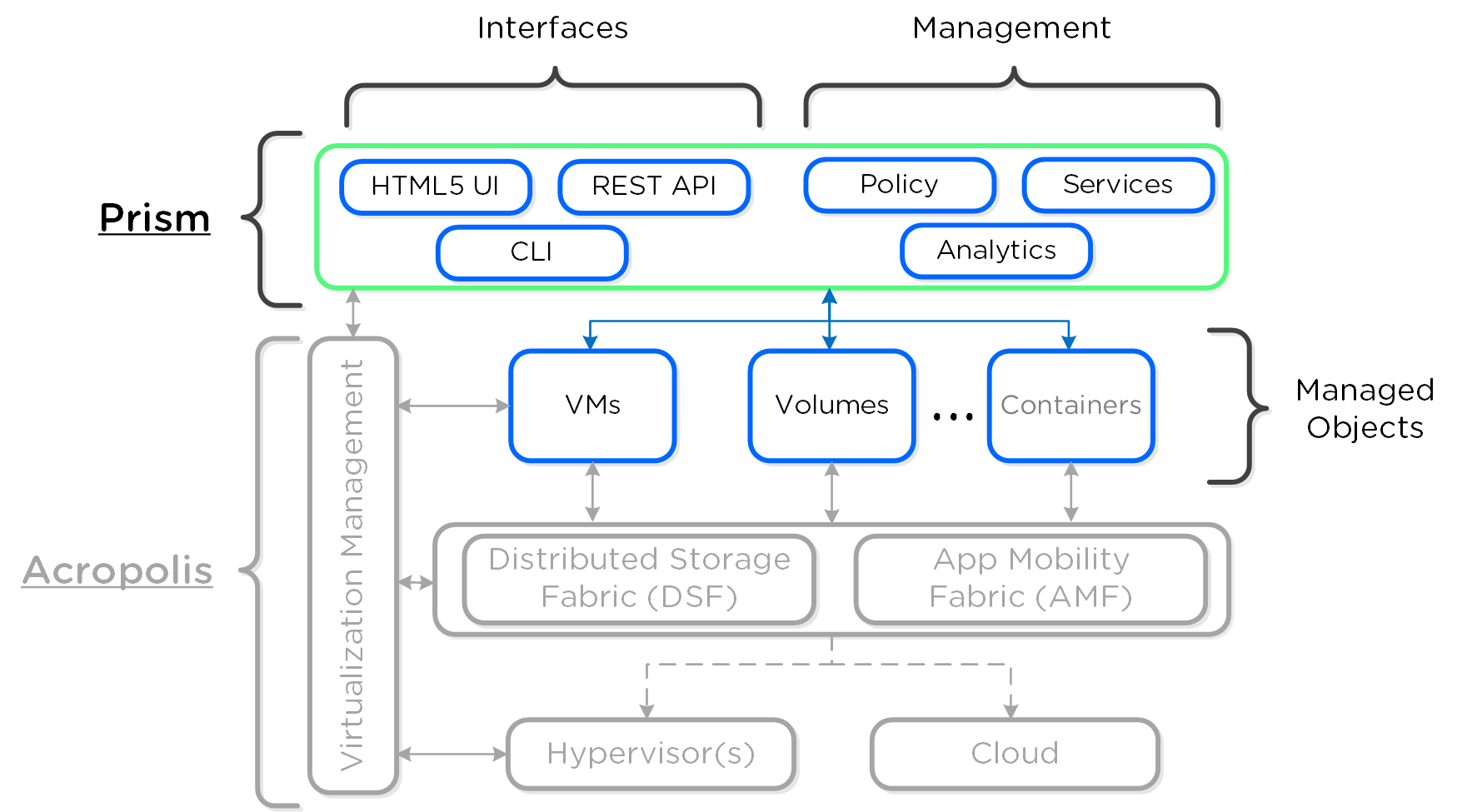
Prism делится на два продукта:
- Prism Central (PC)
- Система управления несколькими кластерами Acropolis посредством единого централизованного интерфейса. Это опциональное ПО поставляемое в виде ВМ
- Управление несколькими кластерами одновременно
- Prism Element (PE)
- Интерфейс для управления конкретным кластером. Данное ПО является частью любого кластера Nutanix.
- Управление одним, конкретным кластером
На рисунке изображена схема взаимодействия ПО Prism Central и Prism Element:
Примечание
Совет от создателей
Для больших, распределенных инсталляций рекомендуется использовать Prism Central для упрощения управления инфраструктурой через единую точку входа.
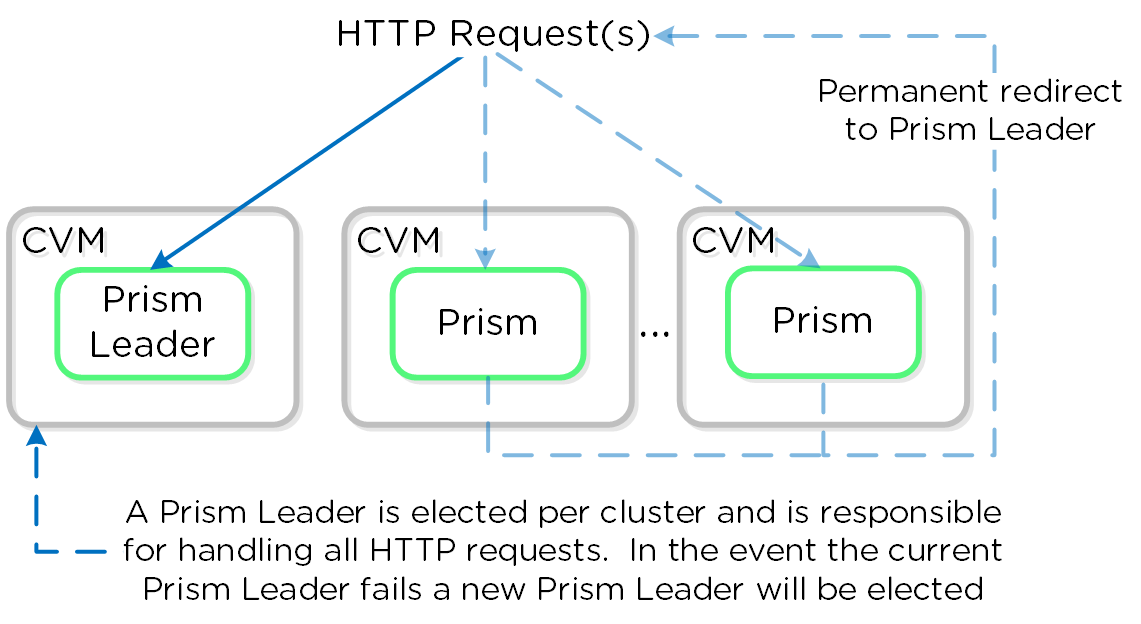
Сервисы Prism
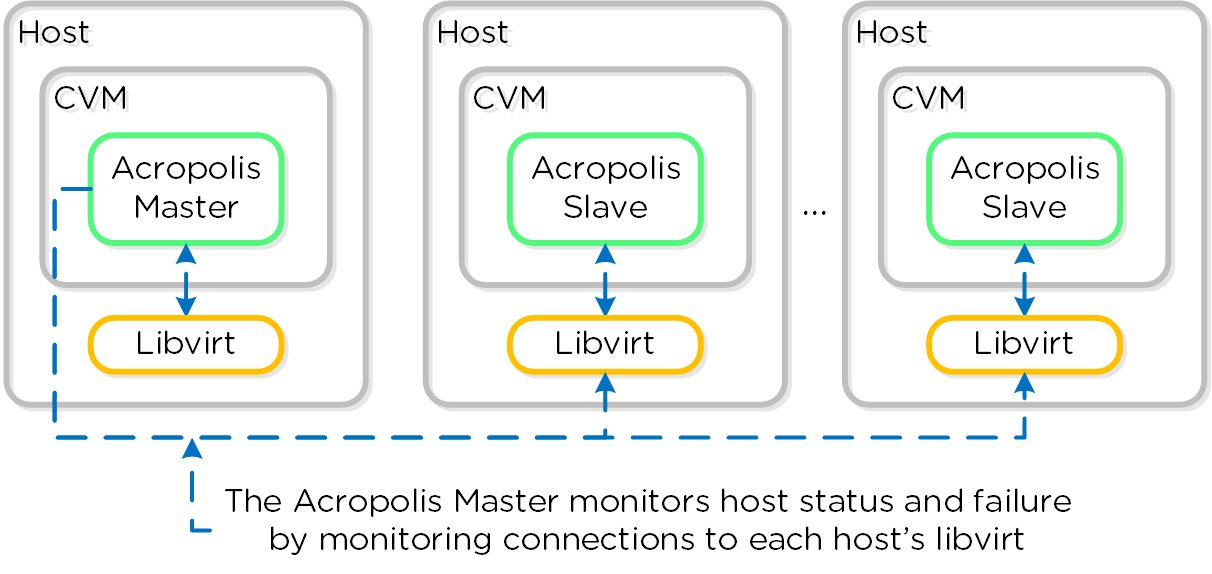
Сервисы Prism выполняются на всех CVM. Среди копий сервиса определяется Мастер, который отвечает за обработку HTTP запросов. В случае каких-либо проблем с текущим Мастер-сервисом данная роль будет передана другой копии сервиса в кластере. Это относится ко всем компонентам ПО Nutanix, имеющим такую архитектуру. Если пользовательский запрос приходит не на Мастер-сервис - он будет перенаправлен Мастеру, с использованием HTTP ответа с кодом 301.
Ниже показано, как сервисы Prism обрабатывают HTTP запросы:
Примечание
Порты Prism
Prism слушает порты 80 и 9440, если трафик HTTP приходит на порт 80 он будет автоматически перенаправлен на порт HTTPS - 9440.
Если используется выделенный внешний адрес для доступа к Prism (рекомендуется), он всегда будет на Мастер-сервисе. В случае выхода из строя текущего Мастер-сервиса, адрес переместится на нового Мастера, а встроенные механизмы работы с ARP (gARP) будут использованы для удаления старых записей о физическом адресе устройства. Проще говоря - кластер всегда будет доступен по одному и тому же адресу.
Примечание
Совет от создателей
Вы можете определить где сейчас находится Мастер-сервис путем выполнения команды 'curl localhost:2019/prism/leader' на любой из CVM кластера Nutanix.
Навигация
Prism довольно удобен и прост в использовании, однако мы рассмотрим основные страницы и их назначение.
Если используется Prism Central, то доступ к нему можно получить посредством IP-адреса указанного при конфигурации и соответствующей записи DNS. Prism Element будет доступен или через Prism Central, или же просто по адресу любой CVM кластера или VIP-адресу кластера.
Когда страница загрузится вы увидите страницу логина, где будут представлены поля для ввода данных учетной записи. Это может быть локальная УЗ или же запись в Active Directory.
После успешного входа вы будете перенаправлены на панель управления, где будет представлена общая информация по кластеру или кластерам, если вы подключились к Prism Central.
Prism Central и Prism Element будут более подробно описаны в следующих главах.
Prism Central
Prism Central состоит из следующих страниц:
- Home Page
- Информация по всей инфраструктуре, включая детальную информацию о статусах сервисов, доступных ресурсах, производительности, задачах и так далее. Для получения более подробной информации вы можете просто нажать на тот элемент, который Вас интересует.
- Explore Page
- Управление и мониторинг сервисами, кластерами, виртуальными машинами и узлами
- Analysis Page
- Детальная информация о производительности кластеров и других объектов с корреляцией событий
- Alerts
- Оповещения от инфраструктуры
На рисунке показан пример панели управления Prism Central:
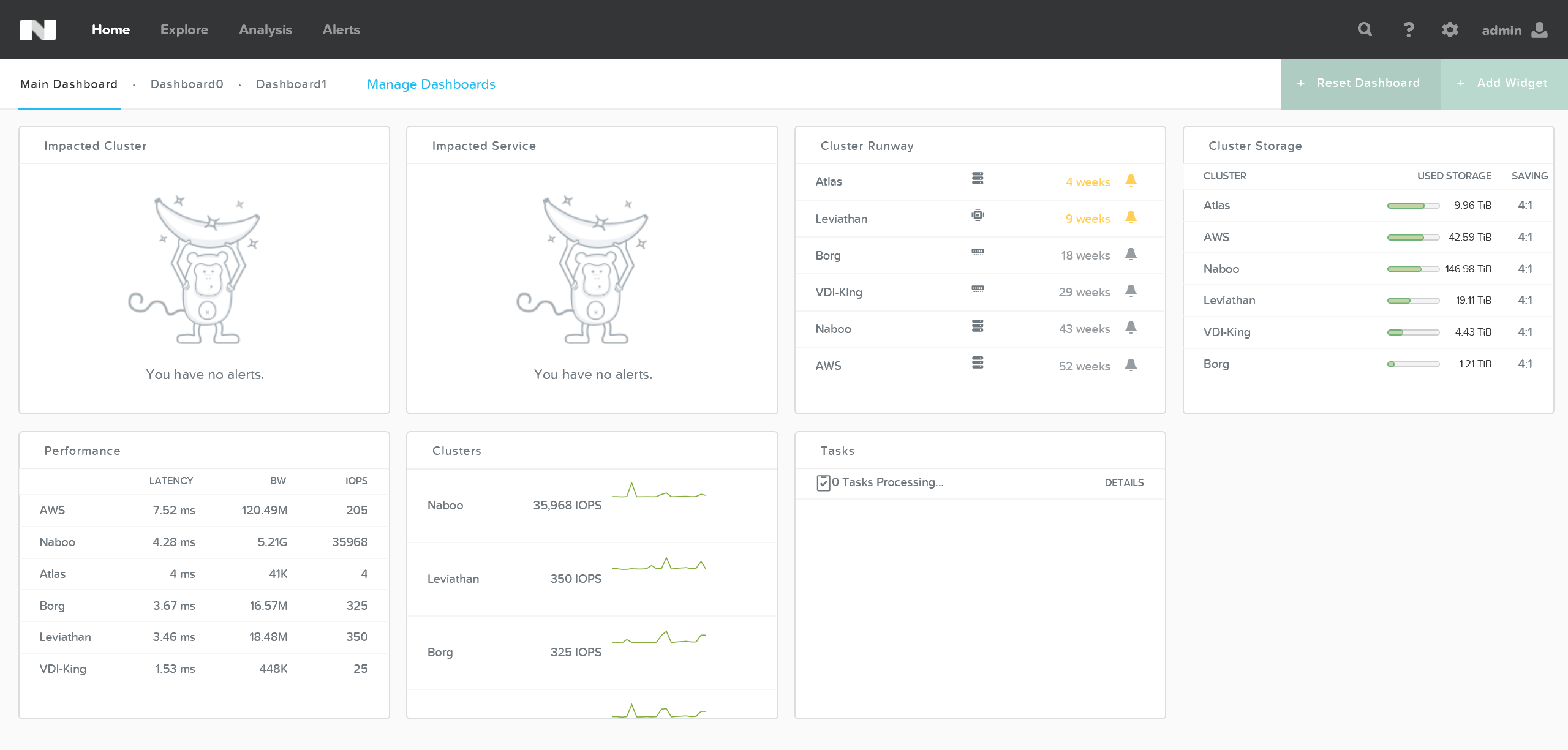
Тут можно увидеть статус мониторинга всей инфраструктуры. А так же получить расширенную информацию, если есть какие-то оповещения или вам нужна какая-то информация.
Примечание
Совет от создателей
Если все зеленое, можно закрыть окно и заняться чем-то еще :)
Prism Element
Prism Element включает в себя следующие основные страницы:
- Home Page
- Панель инструментов с детальной информацией о событиях, ресурсах, производительности, состоянии компонент, запущенных задачах и т.д. Для получения дополнительной информации о любом объекте - просто нажмите на него.
- Health Page
- Детальная информация о состоянии инфраструктуры и оборудования. Включает в себя результаты выполнения NCC.
- VM Page
- Страница управления виртуальными машинами, операции CRUD (Acropolis)
- Мониторинг ВМ (не-Acropolis)
- Storage Page
- Управление контейнерами, мониторинг, операции CRUD
- Hardware
- Мониторинг и управление физическими узлами, дисками, сетью. Включает в себя функции расширения кластера и управления дисками.
- Data Protection
- Катастрофоустойчивость, Управление подключением к облакам и настройка Метро-кластера. Управление объектами хранилища, снимками ВМ, репликацией и восстановлением.
- Analysis
- Подробный анализ событий кластера с возможностью корреляции данных
- Alerts
- Оповещения и ошибки от локального кластера
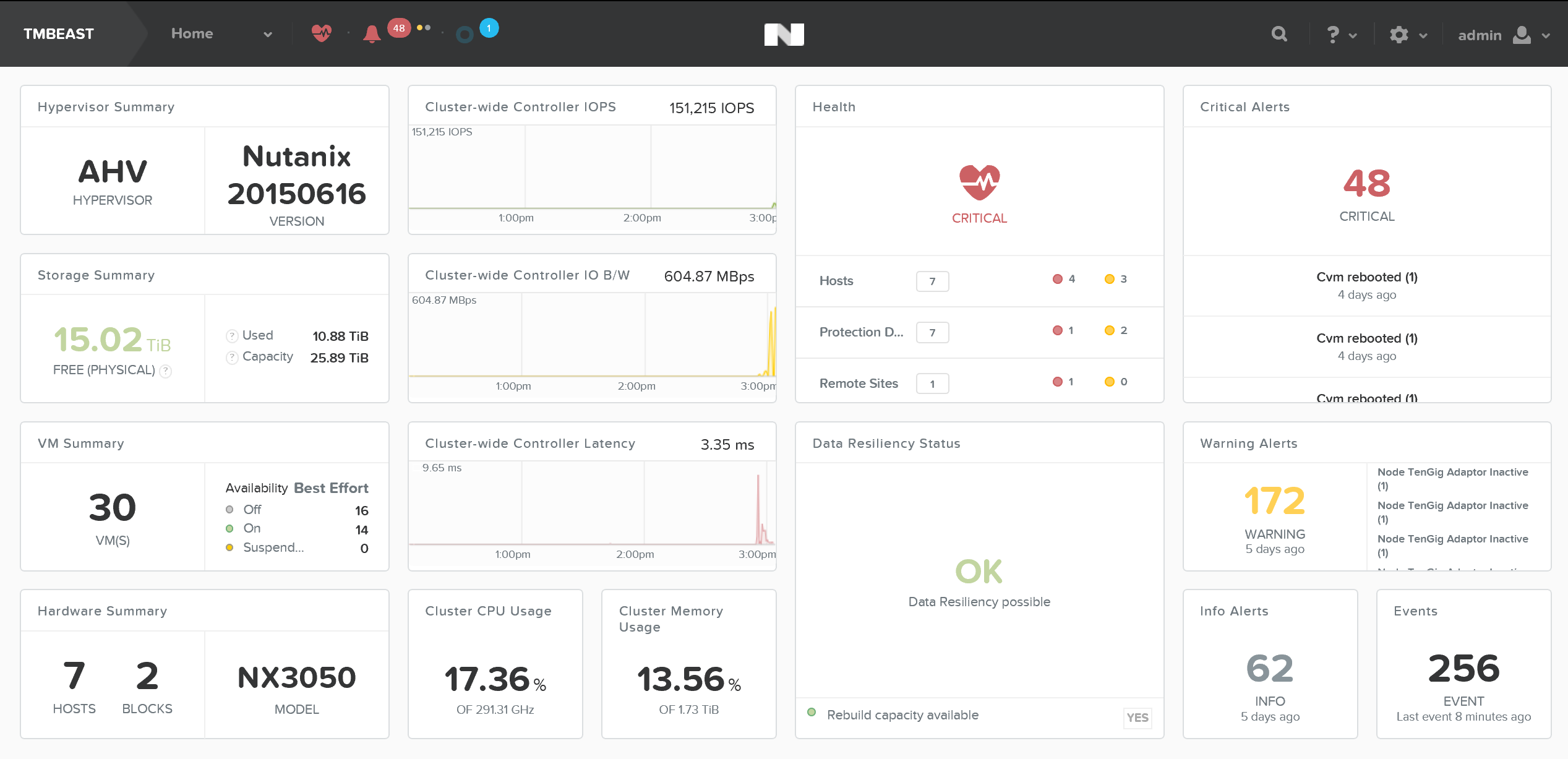
Домашняя страница предоставляет детальную информацию по оповещениям, статусам сервисов, емкости, производительности, задачам, и так далее. Для получения детальной информации - нажмите на интересующем Вас объекте
Ниже показан пример отображения информации по кластеру в Prism Element:
Примечание
Сочетания клавиш
Удобство и простота интерфейса - это ключевая особенность Prism. Для упрощения навигации мы добавили несколько комбинаций горячих клавиш
Ниже описаны некоторые сочетания клавиш:
Изменение типа представления информации в рамках страницы:
- O - Общая информация
- D - Диаграмма
- T - Таблица
События и задачи:
- A - Оповещения
- P - Задачи
Навигация по меню (Перемещаться между пунктами меню можно с помощью стрелок):
- M - Ниспадающее меню
- S - Настройки (иконка с шестеренкой)
- F - Панель поиска
- U - Пользовательское ниспадающее меню
- H - Помощь
Использование Prism
В следующих разделах мы рассмотрим некоторые пути использования интерфейса Prism, а так же сценарии устранения неполадок.
Обновление ПО Nutanix
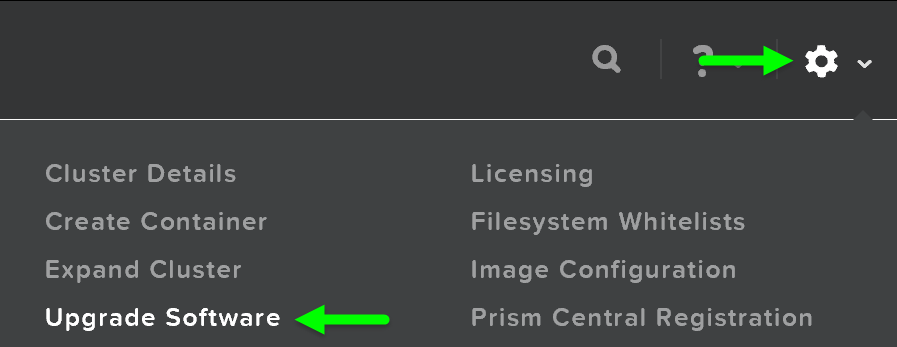
Обновление ПО Nutanix очень простой процесс.
Нужно зайти в Prism и нажать на иконку с шестеренкой в правом верхнем углу экрана, или же нажав клавишу 'S'. Затем выбрать пункт 'Upgrade Software':
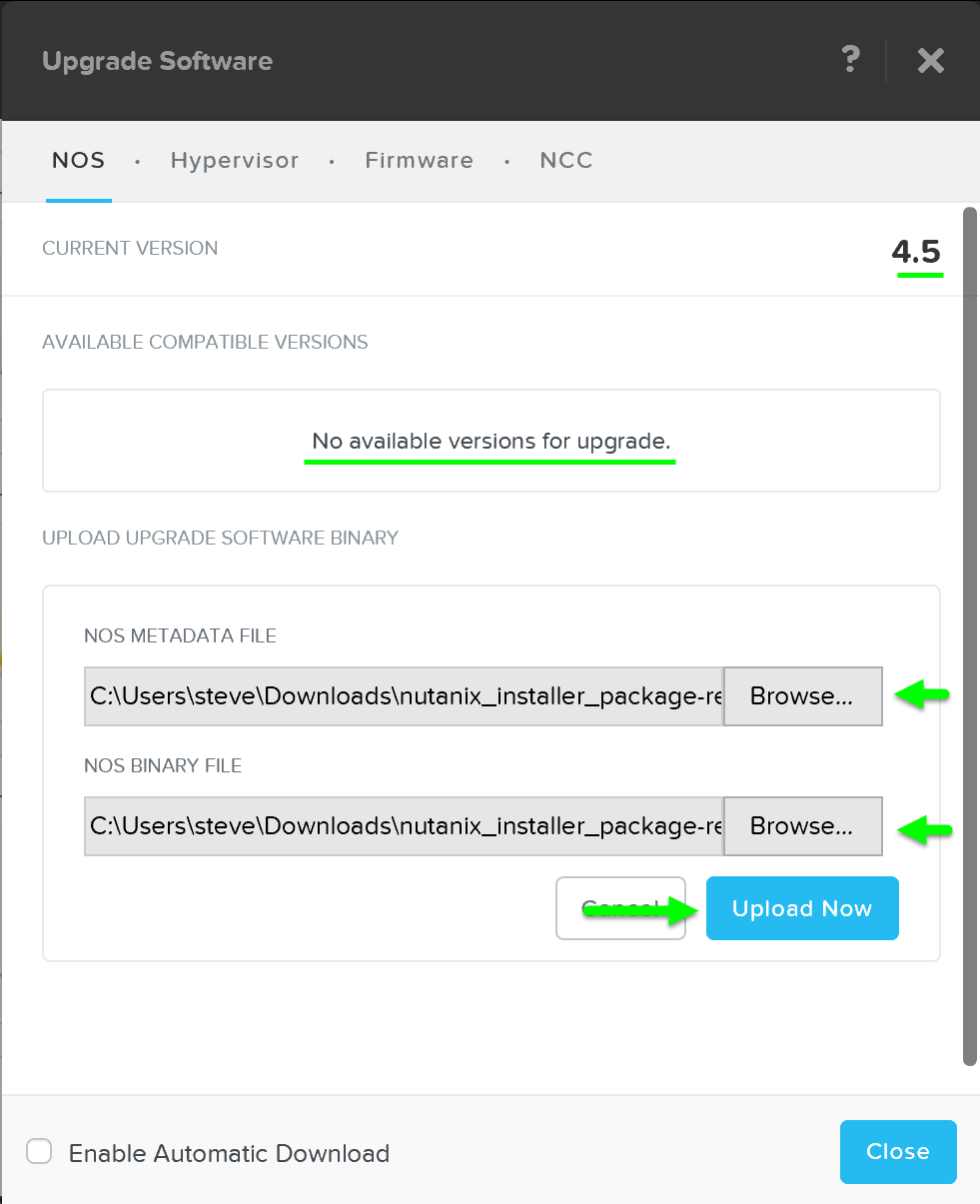
Эти действия запустят процесс обновления ПО, и Вы увидите окно 'Upgrade Software' где будет показана текущая версия ПО и новая версия, если она доступна. Также можно осуществить загрузку обновлений NOS вручную.
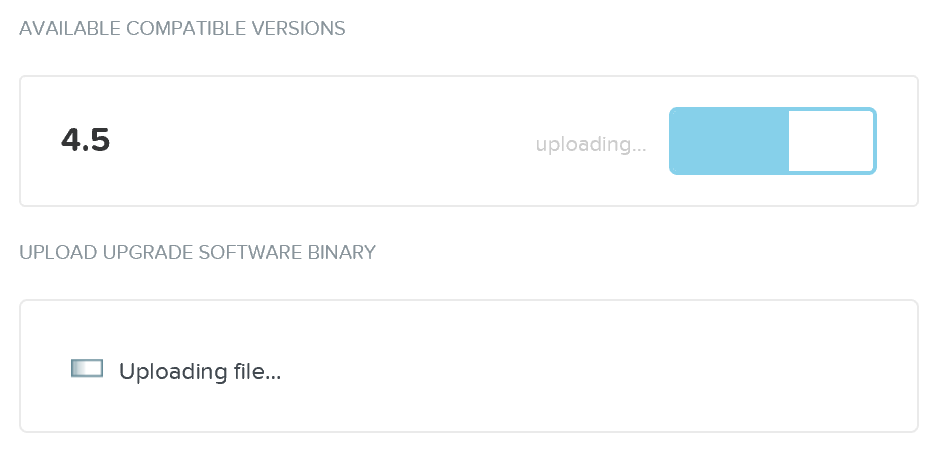
Затем можно получить обновление автоматически с ресурсов Nutanix или загрузить обновление вручную:
Обновление ПО будет загружено на служебные ВМ Nutanix (CVMs):
Когда ПО будет загружено - можно нажать на кнопку 'Upgrade' для начала процесса обновления:
Система покажет окно подтверждения действия:
Процесс установки новой версии начнется с проверки готовности платформы к обновлению:
Как только обновление буде завершено - статус процесса изменится соответствующим образом, Платформа получит доступ ко всем новым функциям свежей версии ПО:
Примечание
Примечание
Текущая пользовательская сессия Prism может быть прервана на короткое время, в момент обновления текущего Мастер-сервиса. Все пользовательские ВМ продолжат работать без прерывания.
Обновление гипервизора
Обновление гипервизора полностью автоматическое и выполняется через Prism.
Для начала обновления Вы должны выполнить такие же действия - перейти в меню 'Upgrade Software' и выбрать пункт 'Hypervisor'.
Обновление может быть загружено автоматически с ресурсов Nutanix или вручную:
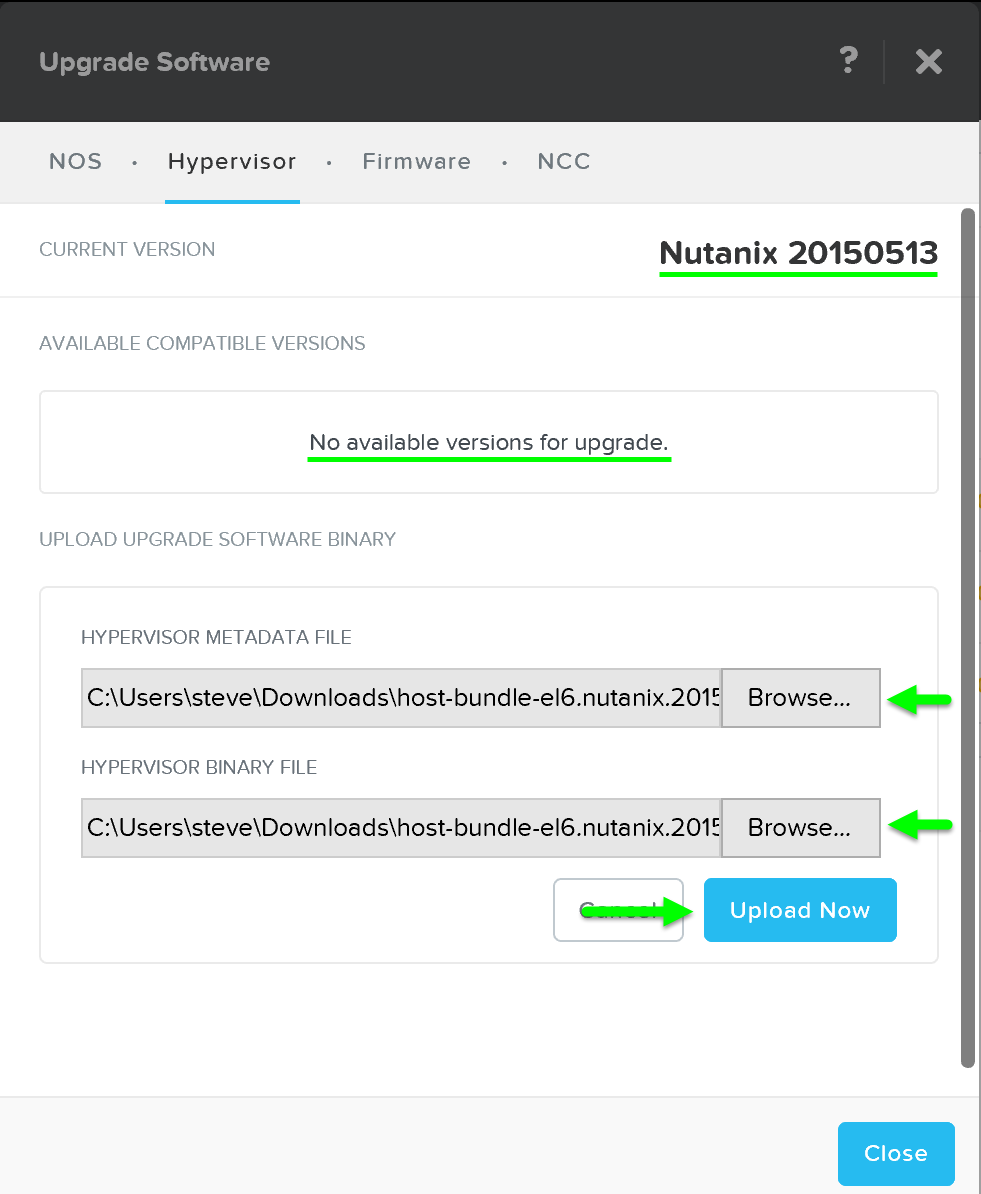
Начнется загрузка обновления ПО на Гипервизоры. Как только ПО будет загружено - нажмите 'Upgrade' для начала процесса обновления:
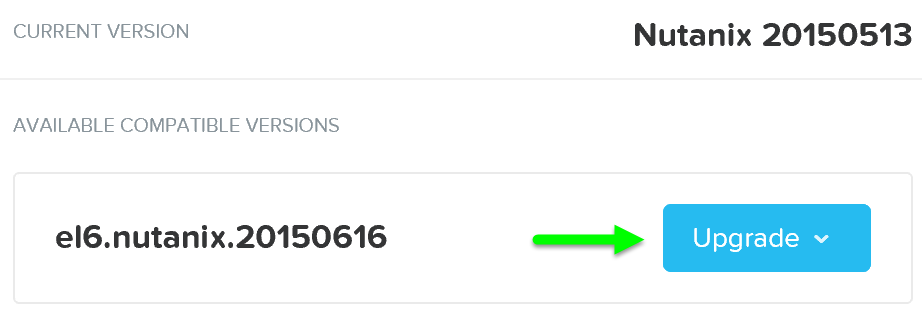
Затем будет показано следующее окно подтверждения:
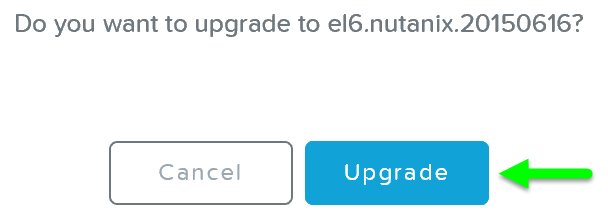
Платформа начнет проверять гипервизоры в составе кластера и размещать на узлах дистрибутив новой версии ПО:
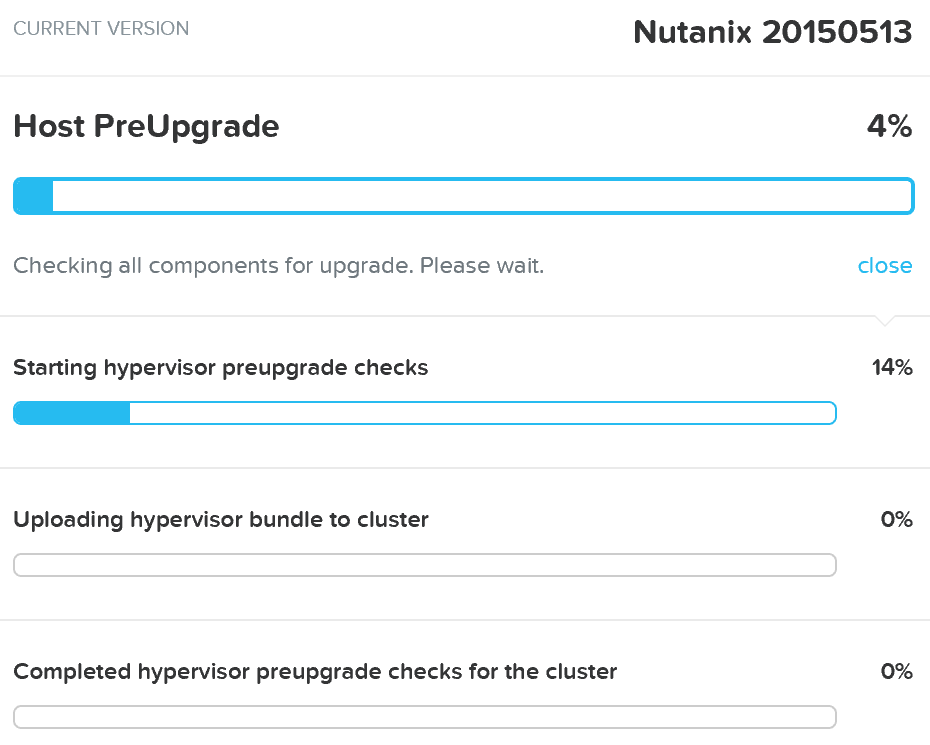
Когда проверки будут закончены и все служебные действия завершены начнется сам процесс обновления ПО:
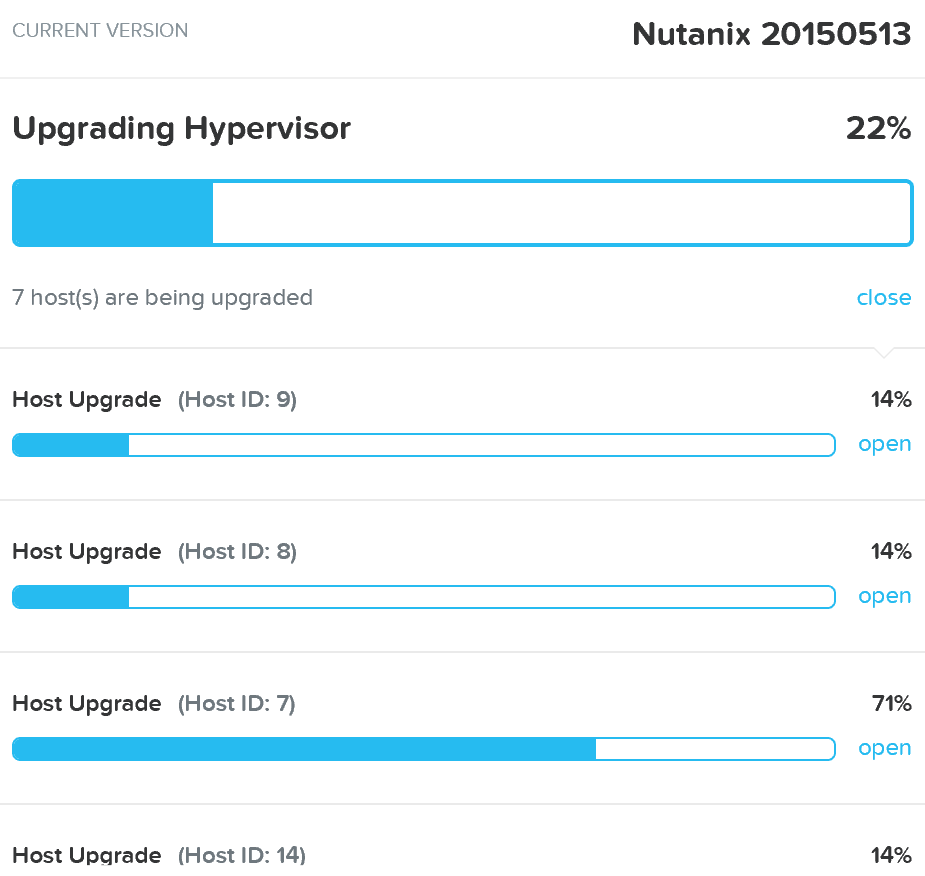
Гипервизоры обновляются по очереди, ВМ работают без прерываний. ВМ будут перемещаться между узлами, с использованием функции живой миграции. После обновления каждый узел будет перезагружен. Этот процесс будет выполнен для каждого узла в кластере.
Примечание
Совет от создателей
Вы можете проверить статус обновления ПО через командную строку CVM выполнив 'host_upgrade --status'. Детальная информация о обновлении конкретного узла расположена здесь ~/data/logs/host_upgrade.out
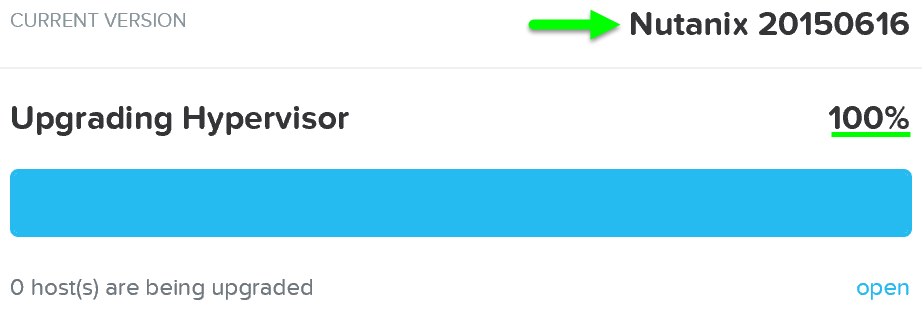
Как только обновление закончится - вы получите доступ ко всем новым возможностям новой версии гипервизора:
Масштабирование кластера
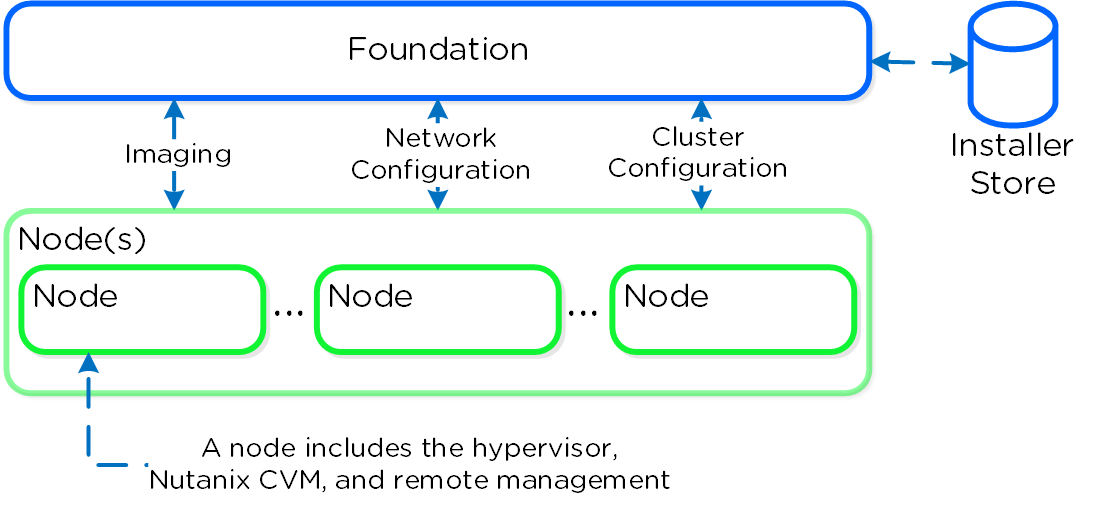
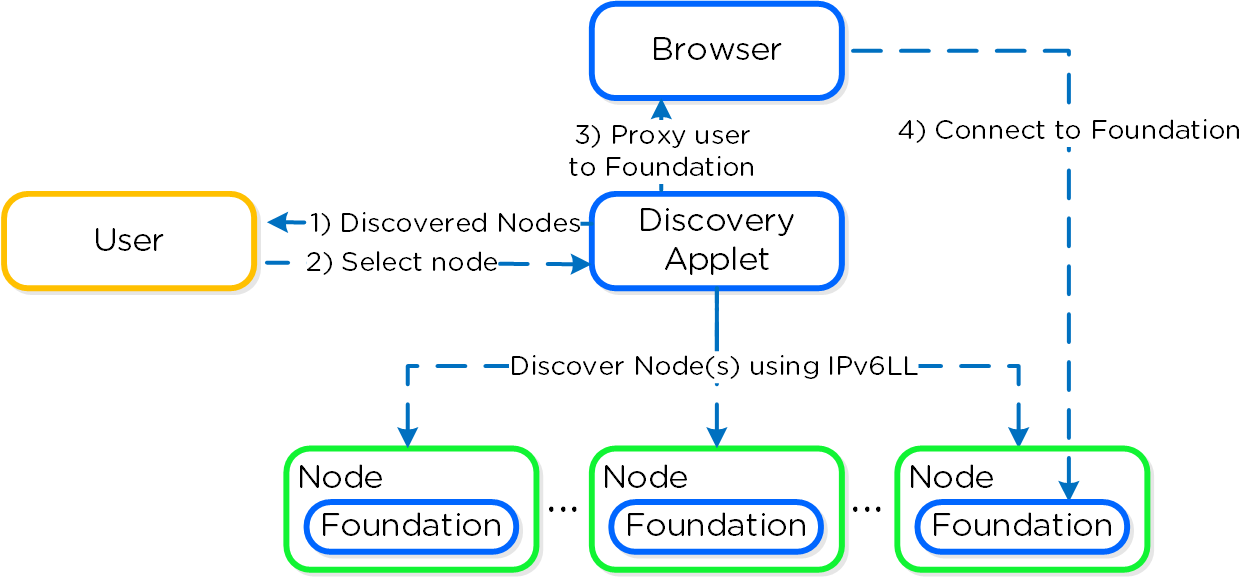
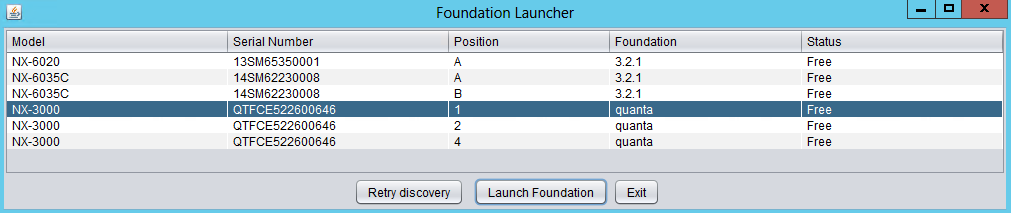
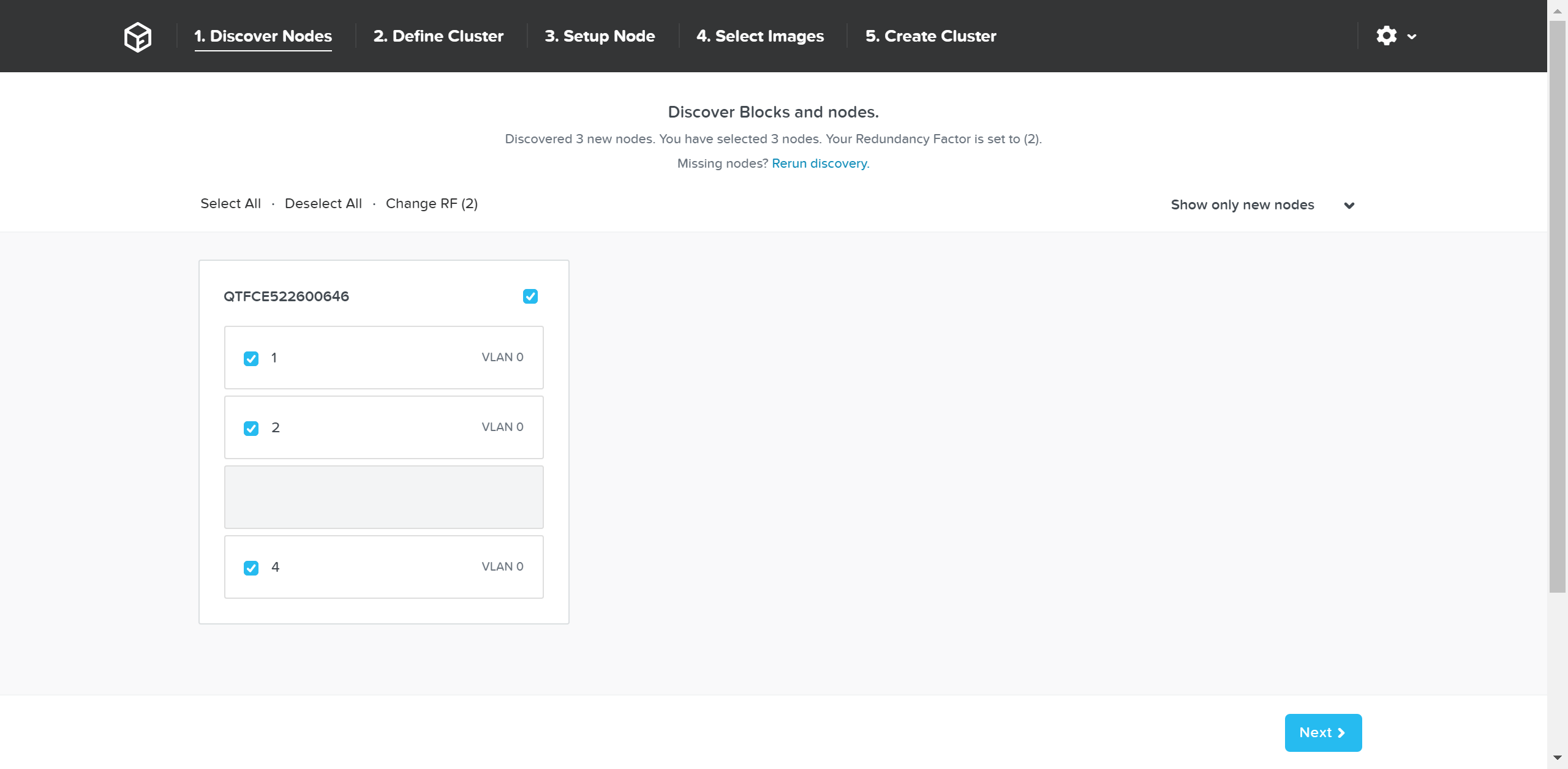
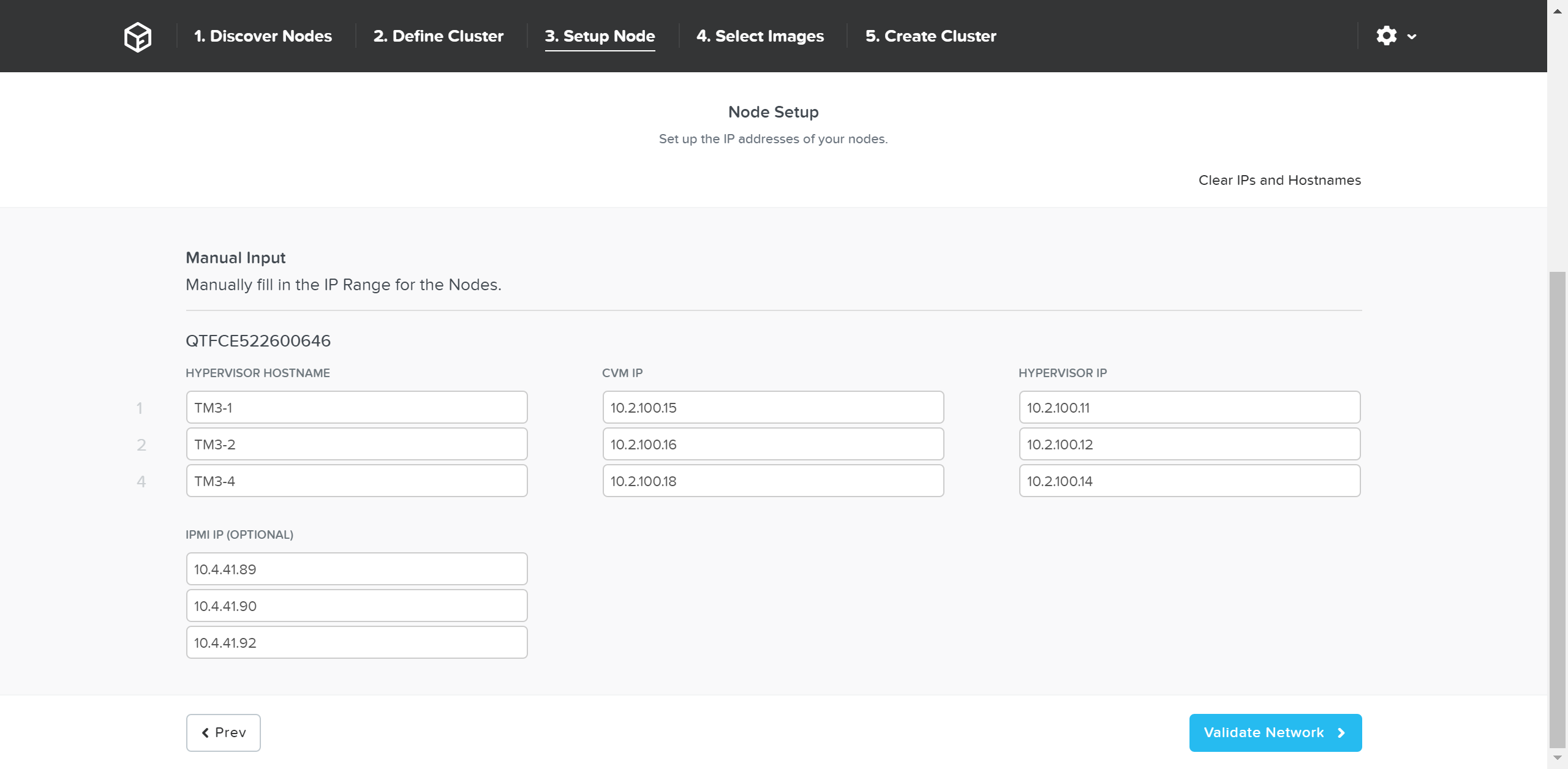
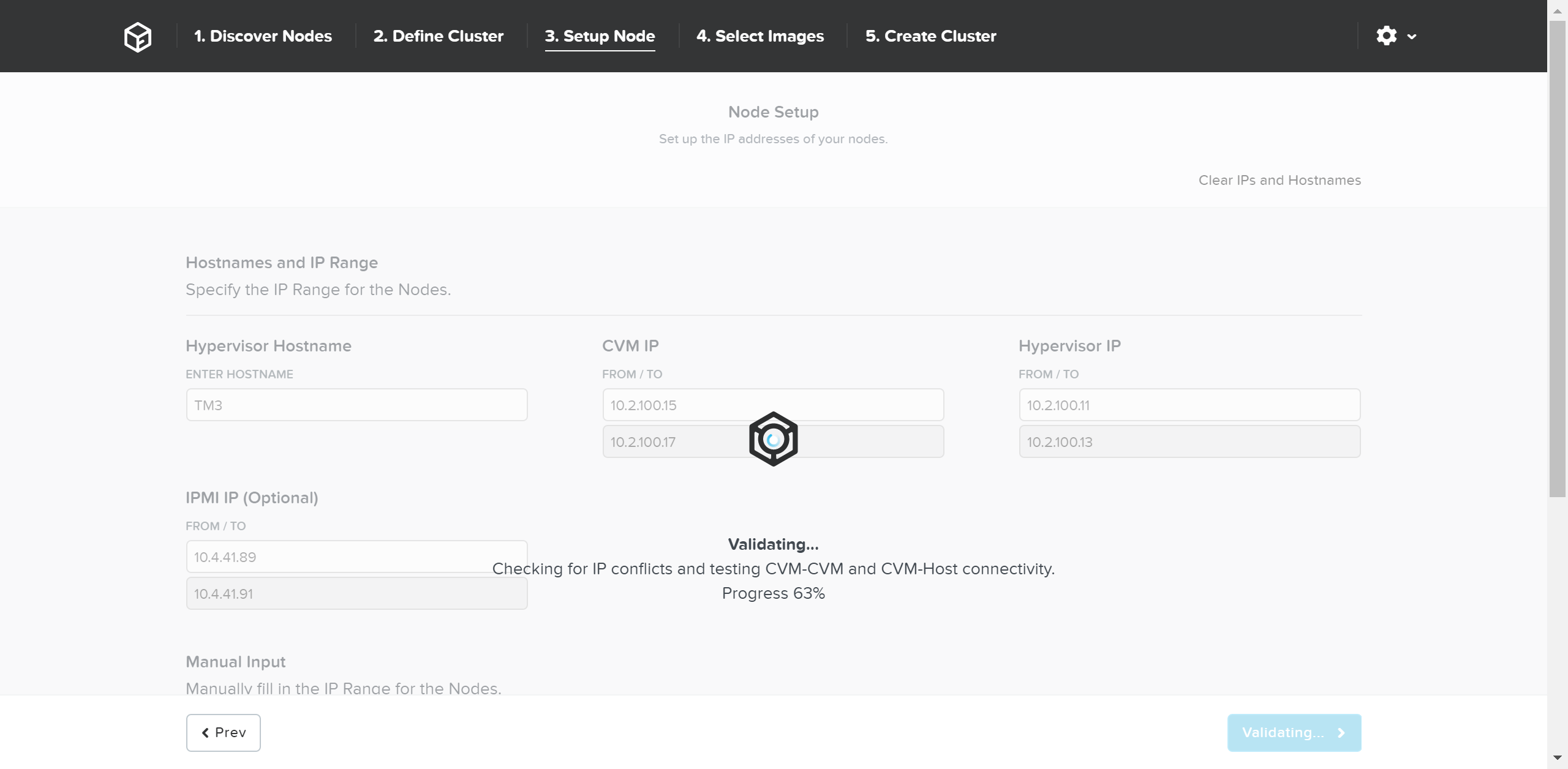
Возможность динамического масштабирования - ключевая функция кластеров Acropolis. Для масштабирования кластера Acropolis просто смонтируйте оборудование, подключите его к сети и нажмите на кнопку питания. Как только узел будет запущен - он будет найден посредством mDNS.
На рисунке изображен пример найденного узла, готового для добавления в кластер:
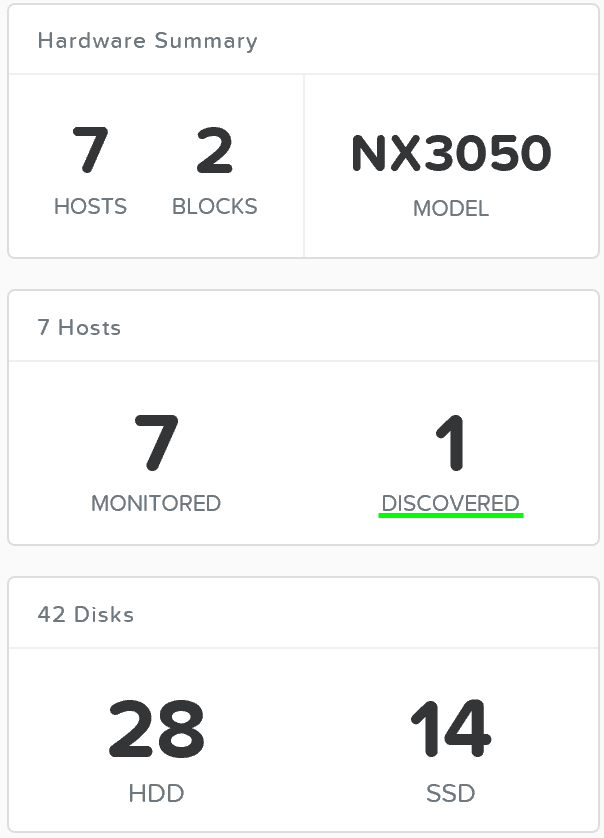
Множество узлов могут быть найдены и добавлены в кластер единовременно.
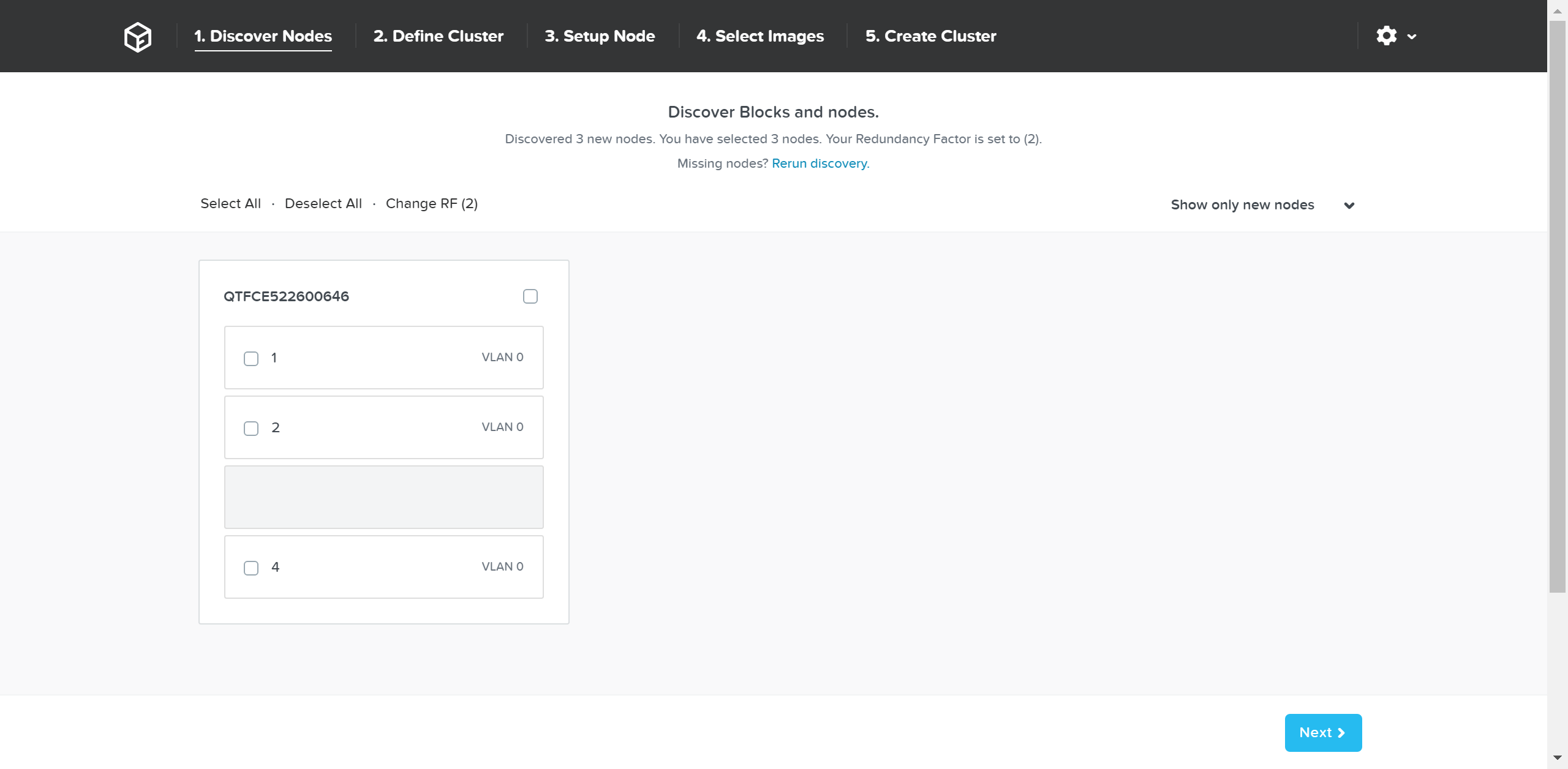
Как только узлы найдены вы можете начинать процесс масштабирования, нажав на кнопку 'Expand Cluster' доступную в правом верхнем углу на странице 'Hardware':
Также, можно запустить процесс масштабирования из меню настройки:
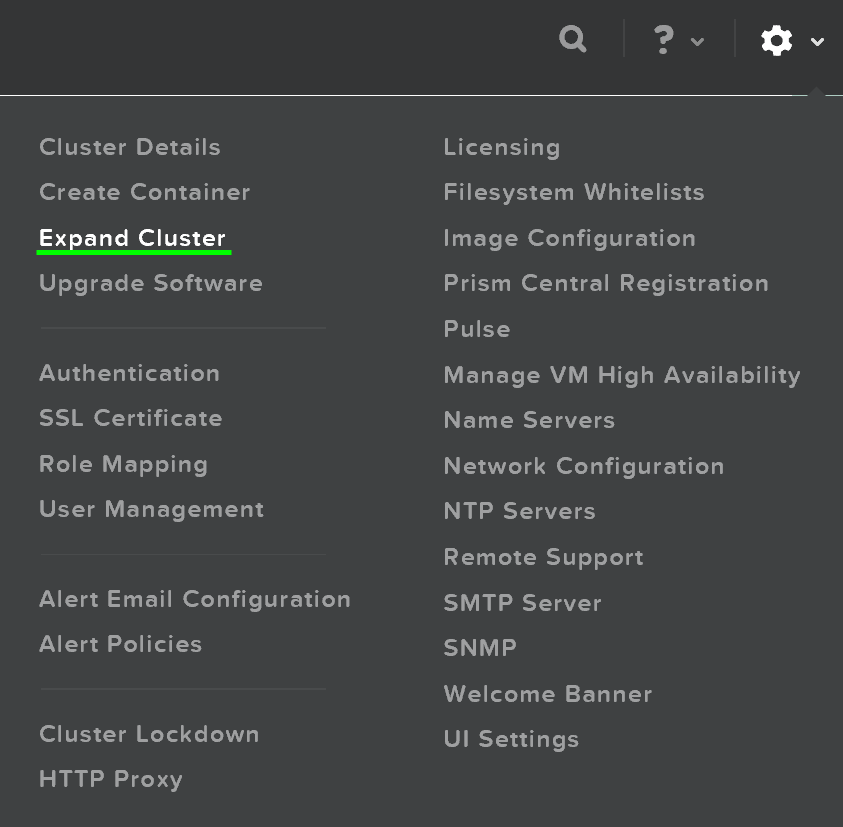
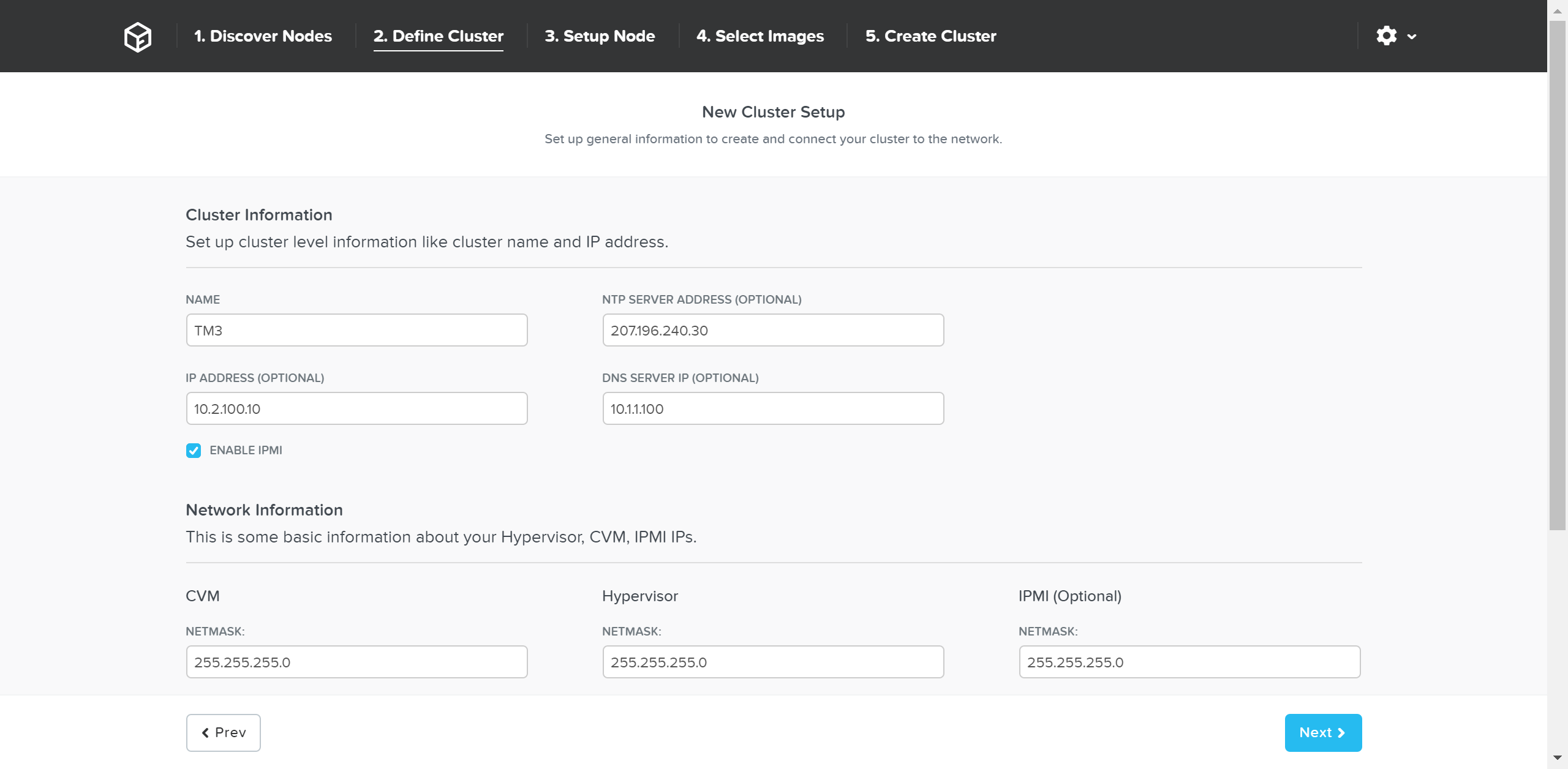
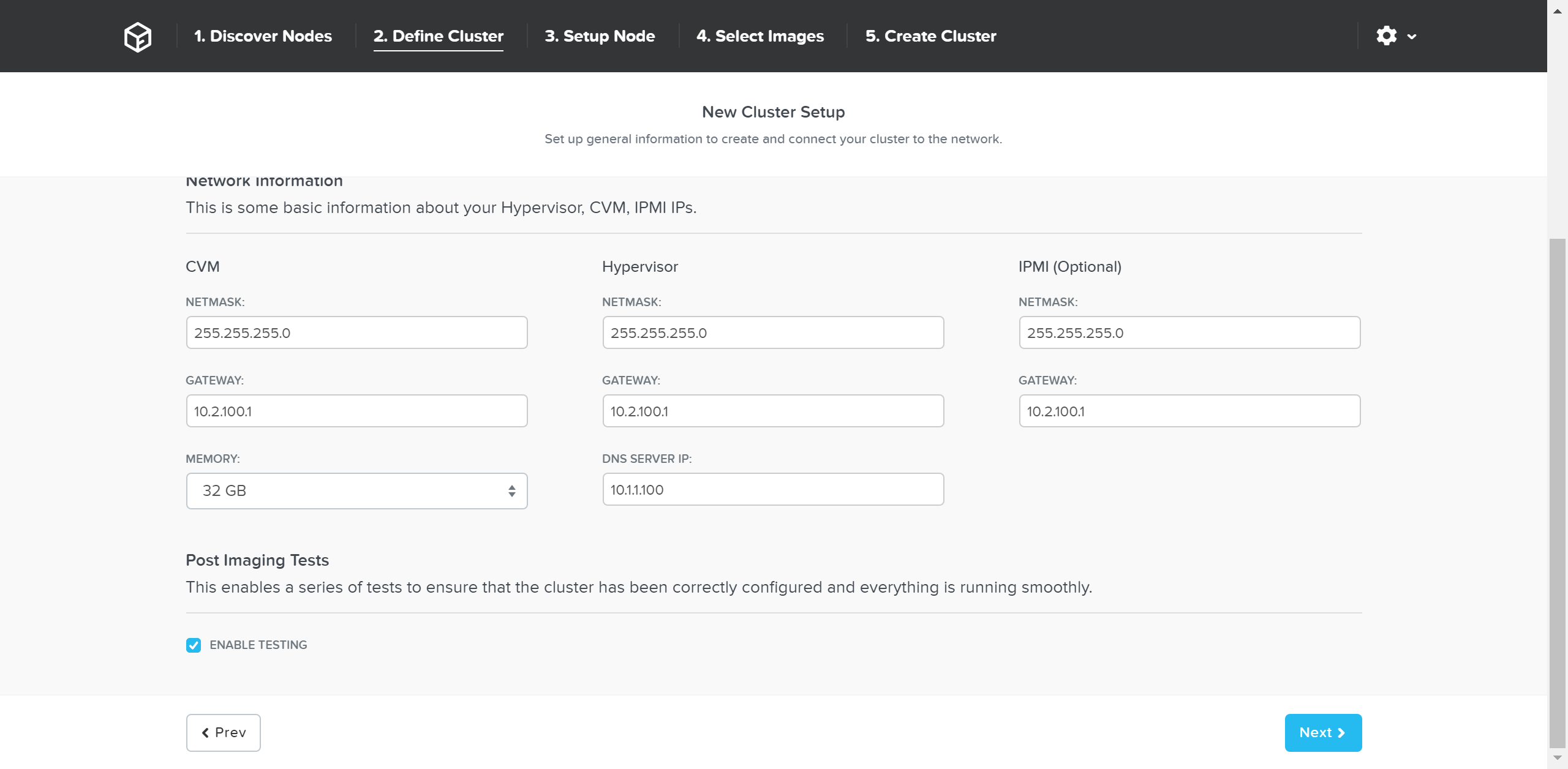
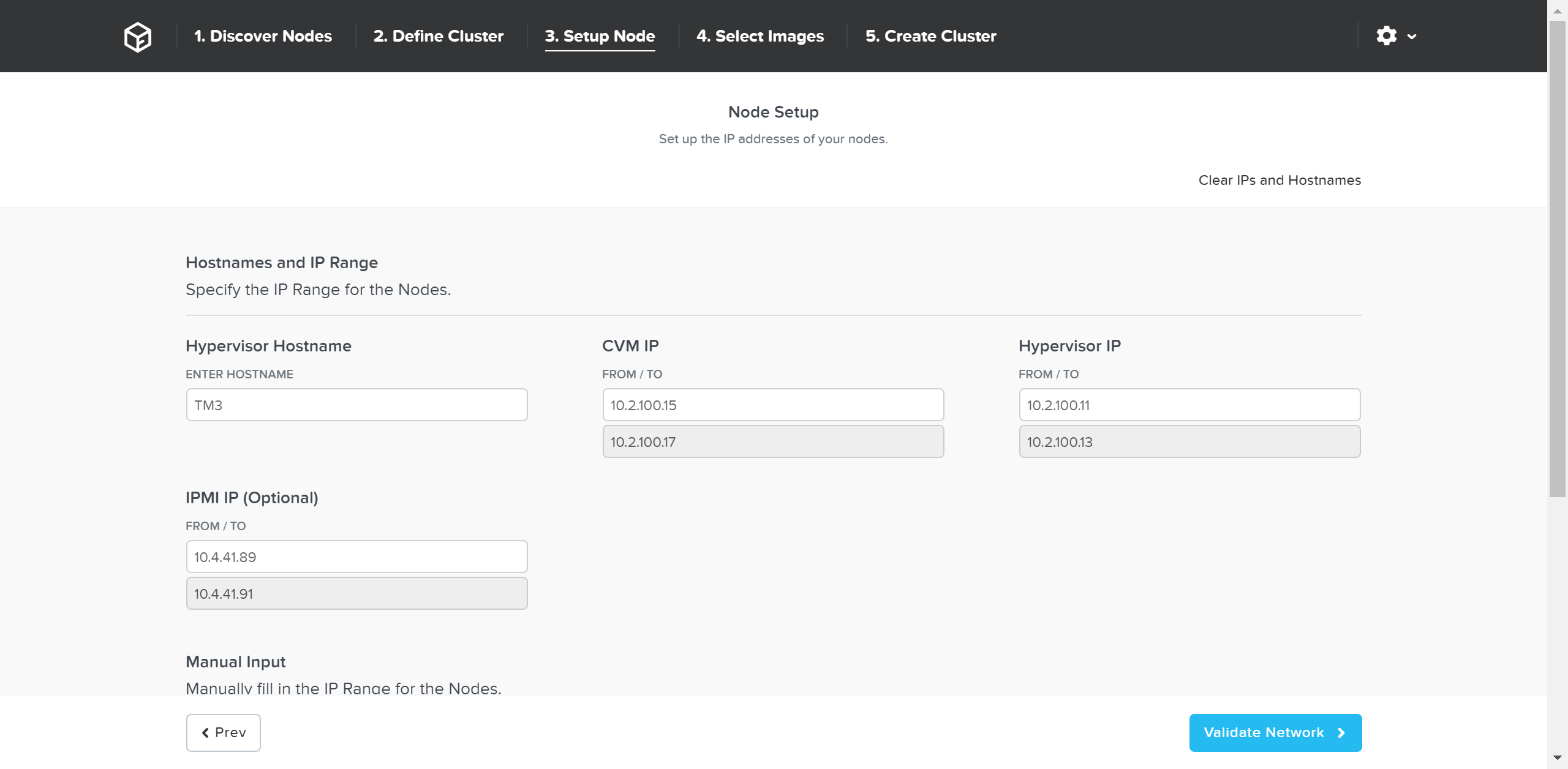
В меню масштабирования кластера можно отметить узлы для добавления и указать для них IP-адреса:
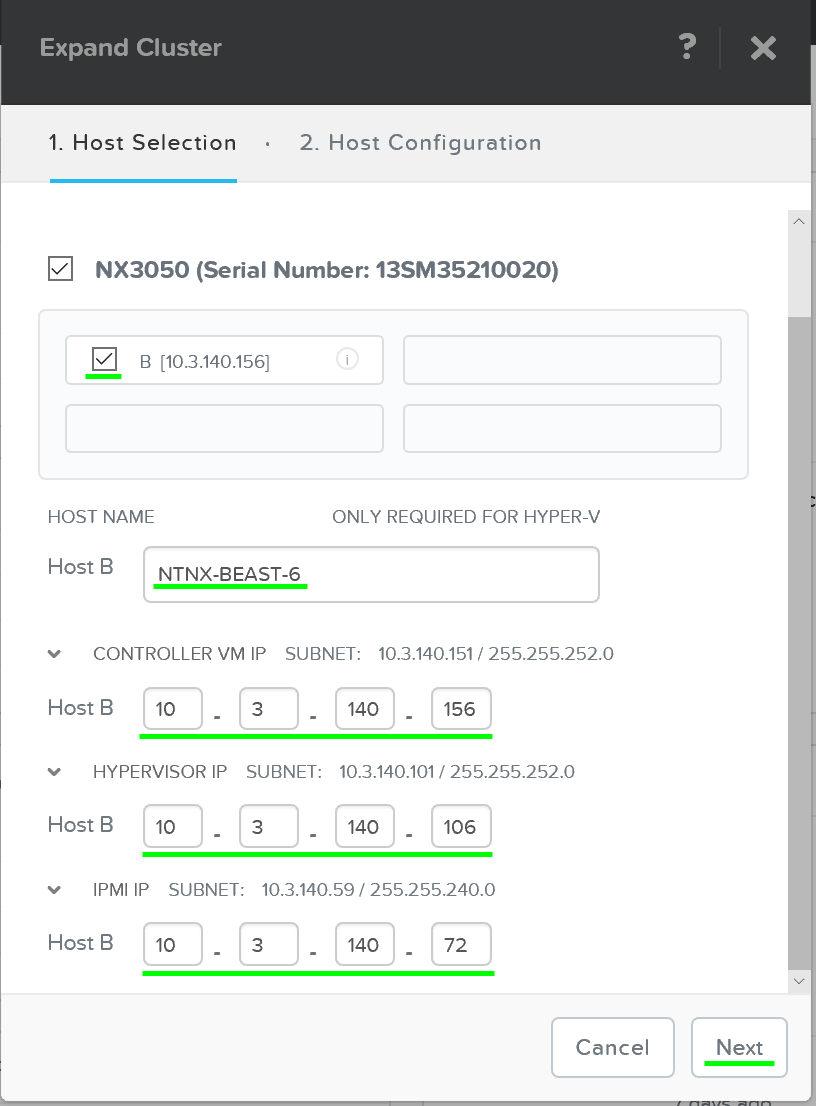
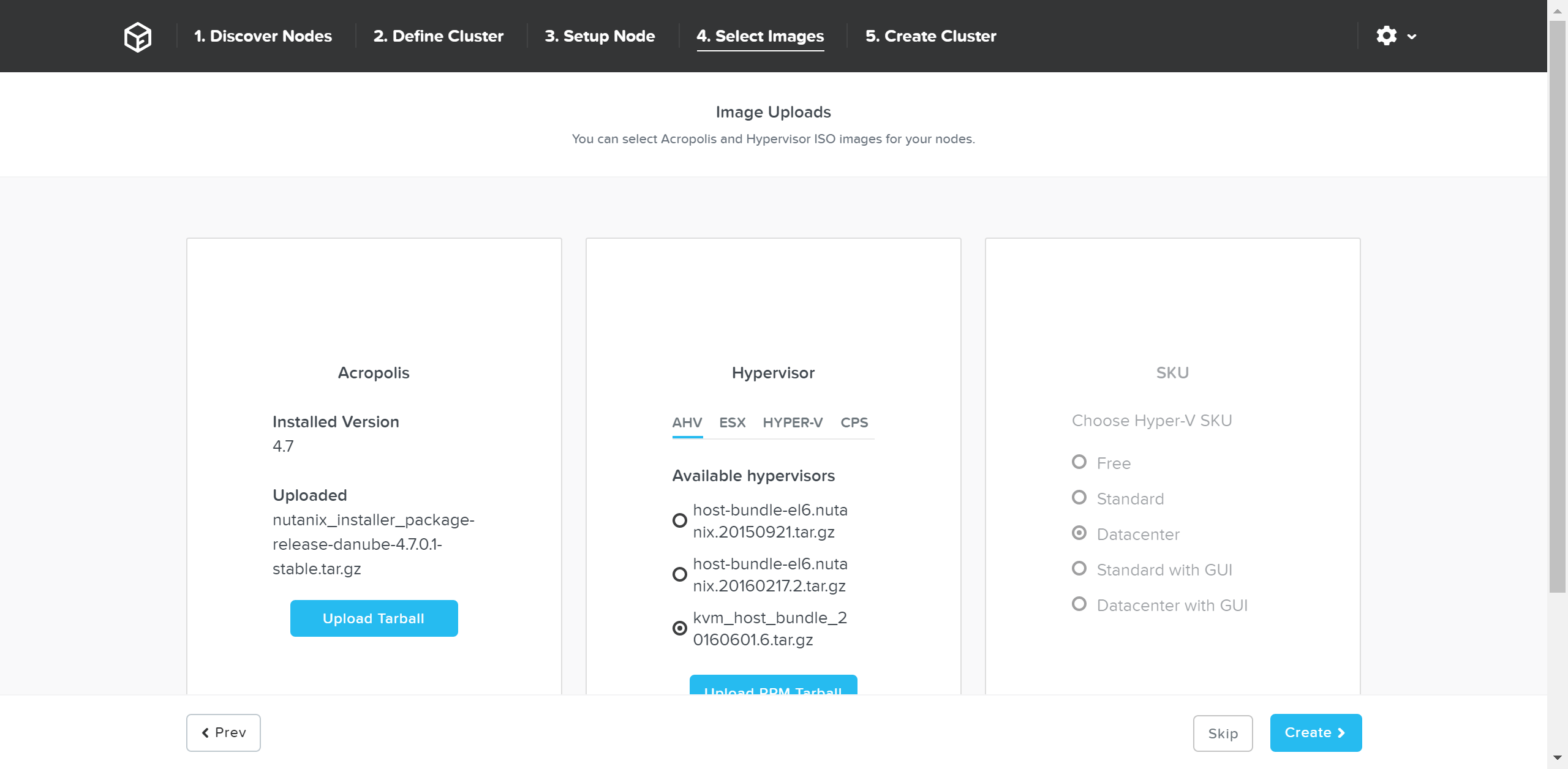
После того, как узел будет выбран, можно загрузить образ требуемого гипервизора на добавляемые узлы. Для узлов с гипервизором AHV, или при наличии образа в хранилище дополнительных действий не требуется.
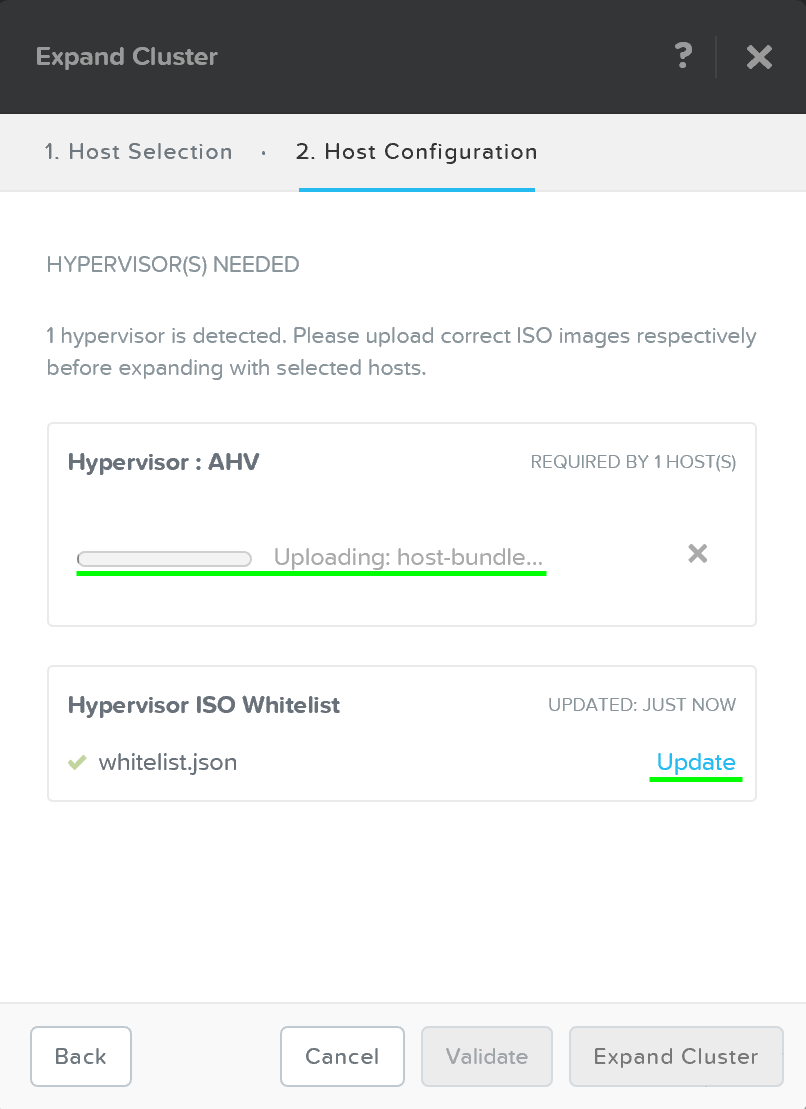
После завершения загрузки образа нажмите 'Expand Cluster' для начала процесса обновления узла и добавления его в кластер:
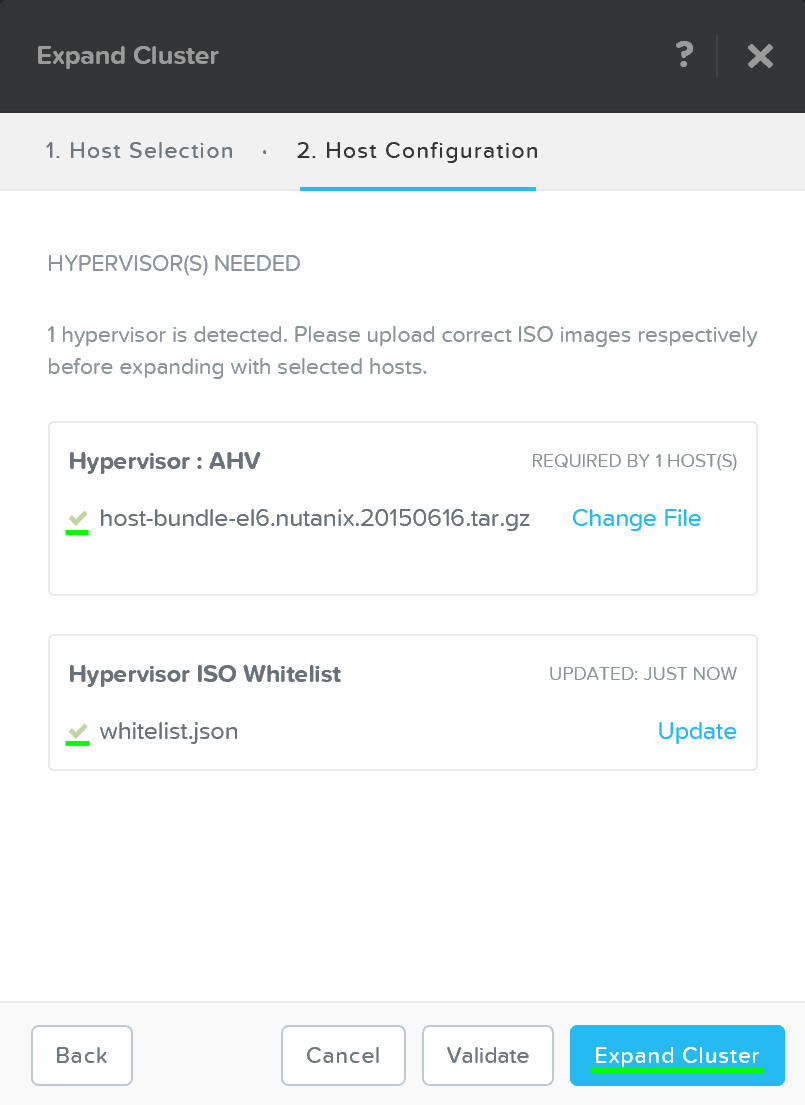
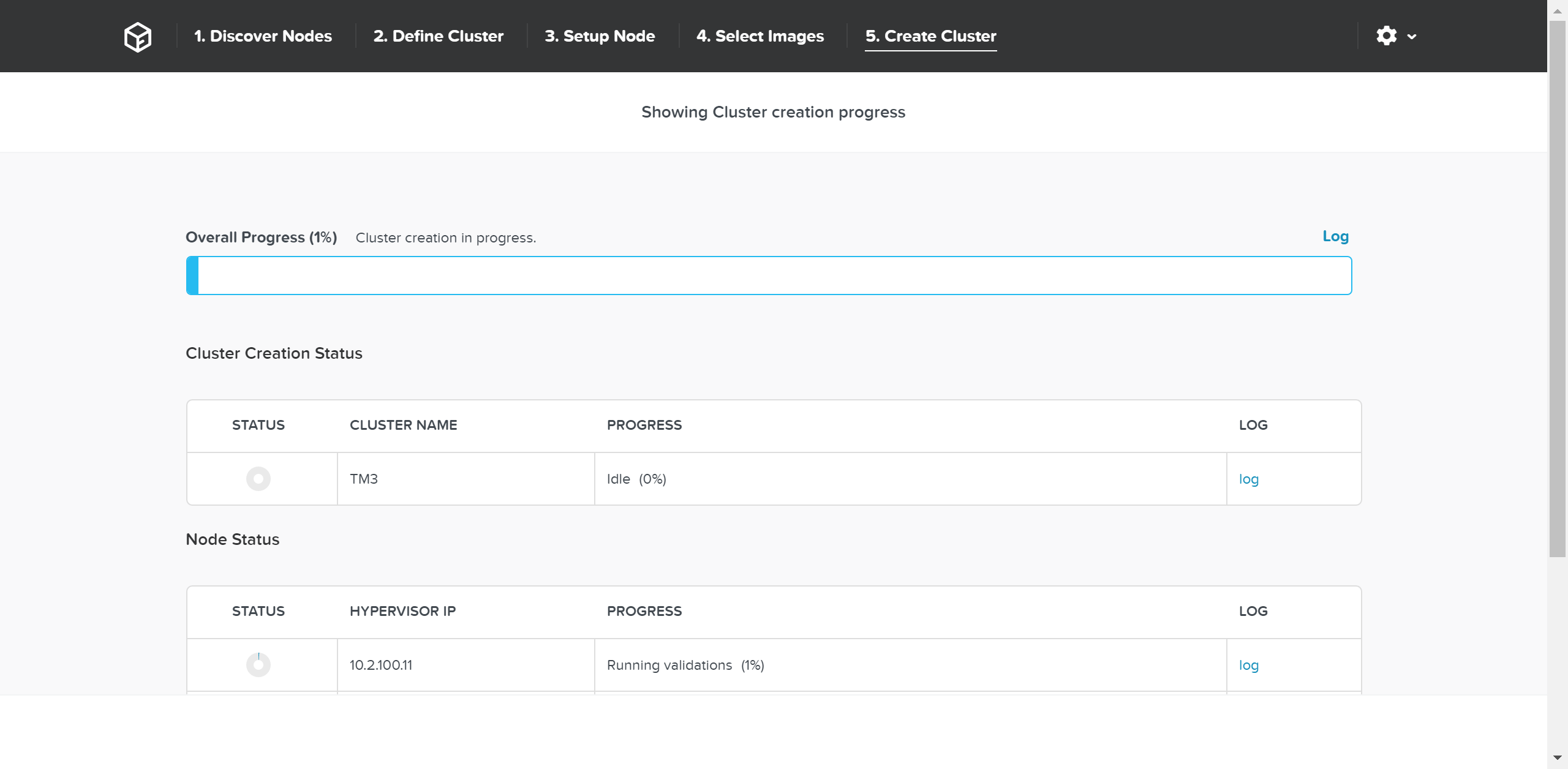
Задача будет сформирована и отправлена на исполнение, появится строка состояния для данной задачи:

Подробная информация о выполнении задачи доступна при нажатии на строке состояния:
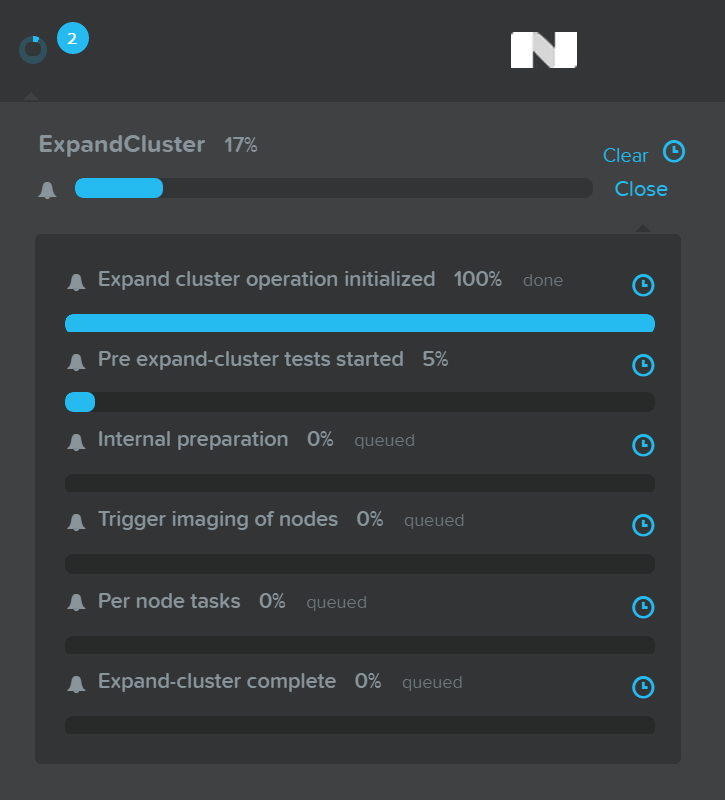
После завершения процесса масштабирования, информация о ресурсах кластера и количестве узлов будет обновлена:
Метрики I/O
Поиск узких мест - одна из самых важных задач в процессе анализа работы платформы и устранения неисправностей. Для упрощения этой задачи в интерфейсе Nutanix есть специальный раздел 'I/O Metrics' на странице с ВМ.
Задержки зависят от множества переменных (глубины очереди, размера I/O, состояния системы, производительности сети и так далее). Эта страница предоставляет подробную информацию о размере I/O, задержках, источниках, и типах нагрузки.
Чтобы получить доступ к этим данным - перейдите на страницу 'VM' и выберите нужную ВМ из списка:

Вкладка с информацией по I/O находится чуть ниже:

На этой вкладке подробно расписаны все метрики I/O. Давайте разберем, что за данные тут доступны.
Первое представление 'Avg I/O Latency' демонстрирует среднюю задержку при операциях чтения/записи за последние три часа. По умолчанию вы видите самые свежие данные по данной метрике.
Тут можно выбрать интересующее время и получить информацию за конкретный период.

Это может быть полезно, если наблюдается внезапный всплеск. Можно найти этот всплеск на графике, и нажать на него для получения детальной информации.
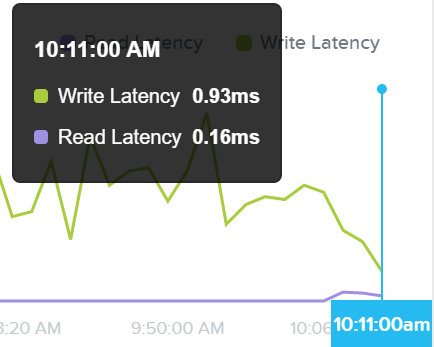
Если с задержками все в порядке, то нет смысла копать дальше.
Следующая секция демонстрирует график размера блока I/O при операциях чтения и записи:
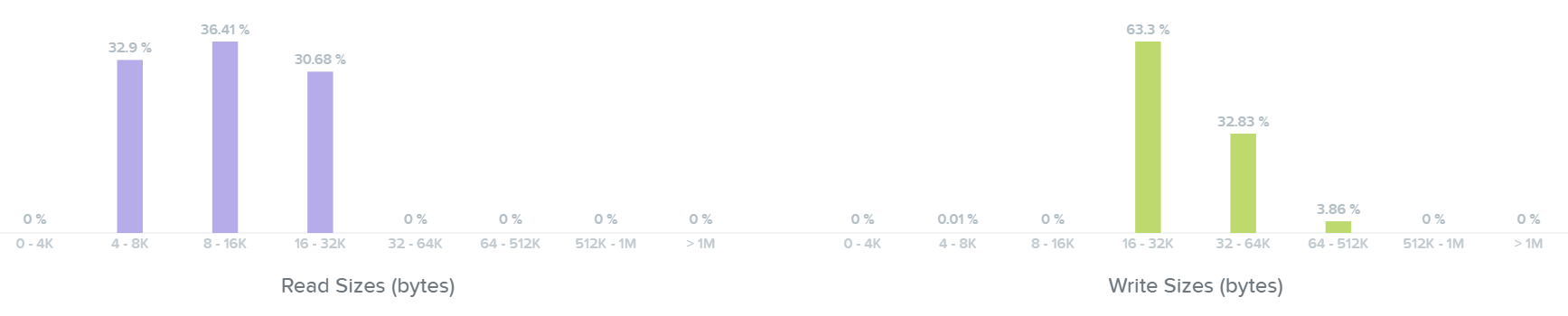
Тут мы видим, что наши операции чтения находятся в диапазоне между 4K и 32K:
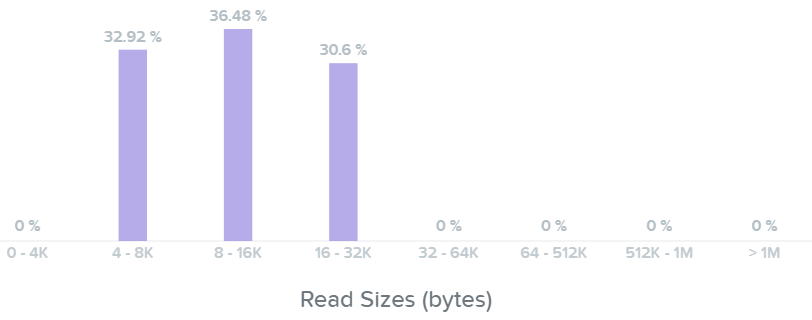
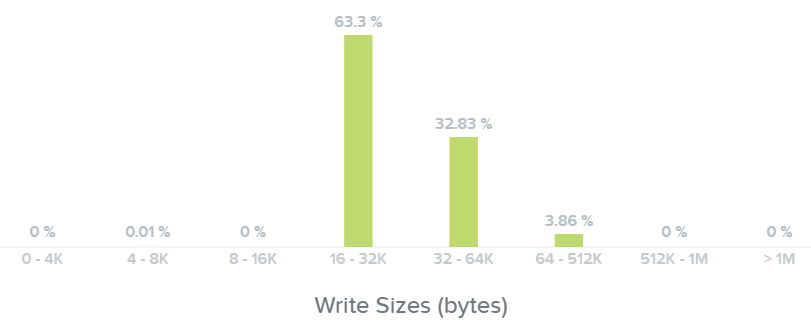
Далее - мы видим размер операций записи - они в диапазоне от 16K до 64K, а некоторые - 512K:
Примечание
Совет от создателей
Если видны пики по задержкам - в первую очередь стоит проверить размер операций I/O. Большие операции I/Os (64K up to 1MB) обычно генерируют более существенные задержки, чем небольшие операции (4K to 32K).
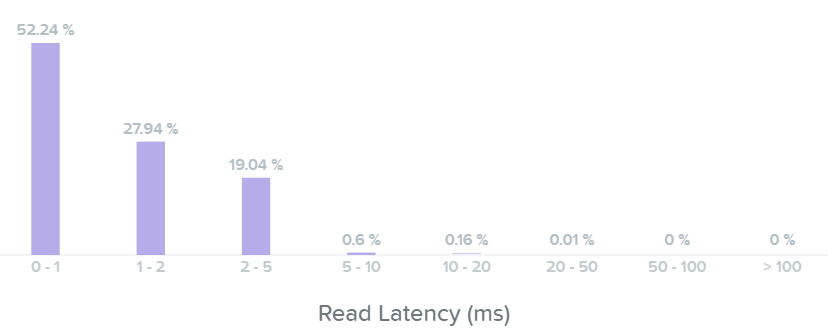
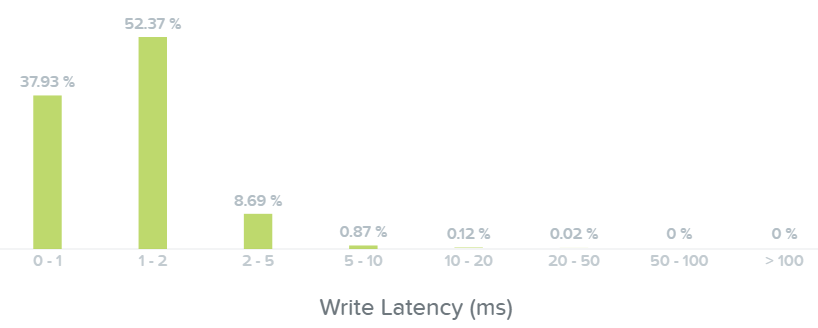
Следующая секция демонстрирует гистограмму для задержек при операциях чтения и записи:

На этом графике видно, что большая часть операций чтения имела задержку около 1ms, а некоторые из операций - 2-5ms.
Если посмотреть в секцию 'Read Source', то будет видно, что большая часть операций чтения/записи выполняется с SSD:

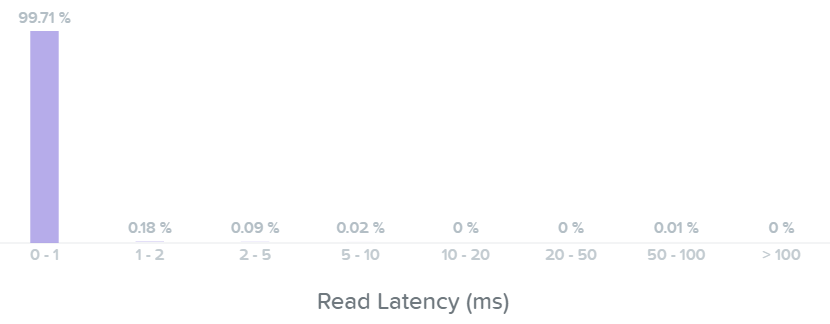
Как только данные считаны - они передаются в общий кэш (DRAM+SSD) в реальном времени (В секции 'Операции чтения/записи и кэширование' это раскрыто более подробно). Тут мы видим, что данные были загружены в кэш и теперь обслуживаются при помощи DRAM:

Тут видно, что по большей части операции чтения имеют задержки менее 1ms:
А здесь видно, что большая часть операций записи выполняется с задержками в районе <1-2ms:
Примечание
Совет от создателей
Если наблюдается всплеск задержек при чтении, и размер операции - небольшой, то стоит проверить - откуда выполняется чтение. Любая операция чтения с HDD будет иметь значительно большую задержку, чем из кэша DRAM; однако, как только требуемые данные попадут в DRAM вы увидите улучшение ситуации с задержками.
Последняя секция отображает типичные профили операций чтения и записи - случайные эти операции или последовательные:
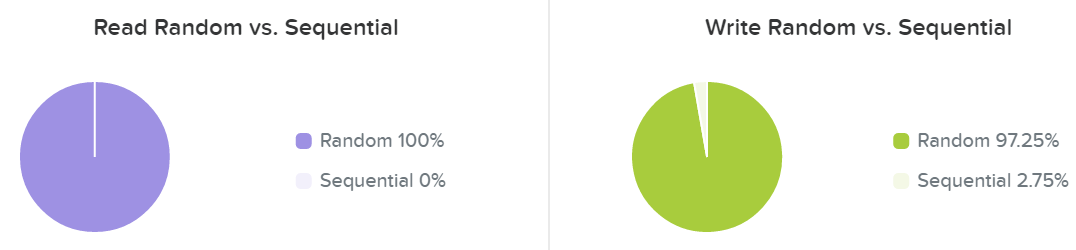
Обычно профиль операций чтения/записи сильно зависят от типа приложения (например VDI генерирует случайные IO, а Hadoop - последовательные). Какие-то приложения будут смешивать оба типа. Например, базы данных будут генерировать случайные IO при запросах или добавлении данных и последовательные при операциях ETL.
Планирование ресурсов
Для получения информации по планированию ресурсов нужно нажать на интересующий кластер в секции 'cluster runway' интерфейса Prism Central:
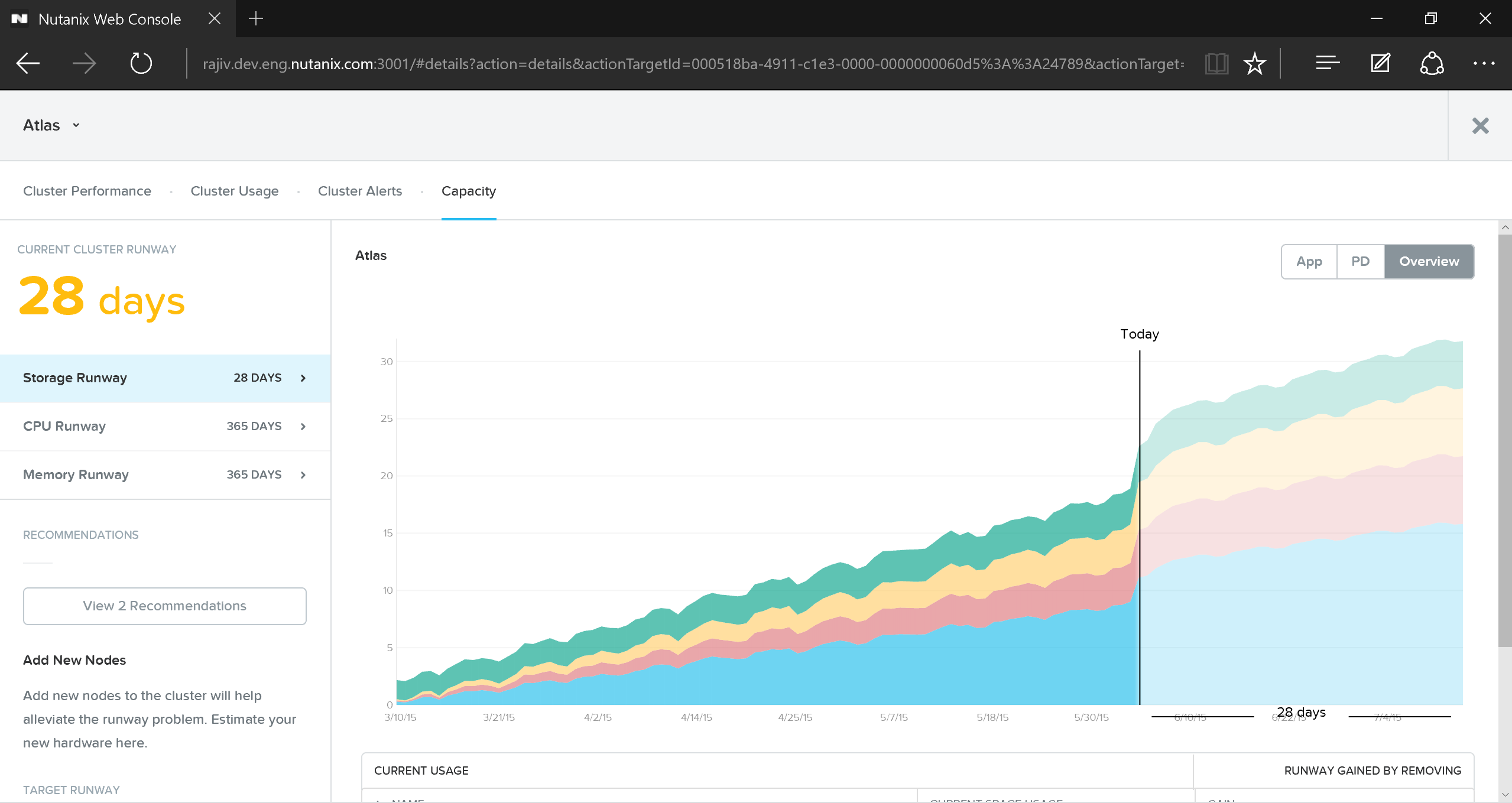
Тут содержится подробная информация о тренде использования ресурсов. Здесь можно получить информацию о главных потребителях ресурсов, путях высвобождения ресурсов и рекомендации по типу узлов, для дальнейшего масштабирования кластера.
HTML5 интерфейс Prism - основной инструмент для простого управления кластером. Но не менее важен API который предоставляет прекрасную возможность для автоматизации. Все функции доступные через интерфейс Prism так же могут быть вызваны через REST APIs, что обеспечивает возможность интеграции с различном сторонним ПО. Это позволяет клиентам и партнерам компании интегрировать ПО от сторонних разработчиков или даже создавать собственный пользовательский интерфейс.
В следующем разделе описаны все интерфейсы Платформы и приведены примеры их использования.
API и интерфейсы
Такие интерфейсы являются основой любой программно-определяемой среды. Nutanix предоставляет широкий набор таких интерфейсов для простого взаимодействия с платформой:
- REST API
- CLI - ACLI & NCLI
- Интерфейсы автоматизации
Примечание
deleveloper.nutanix.com
Обязательно посетите раздел нашего сайта для получения подробной информации по этой теме: developer.nutanix.com!
REST API позволяет получить доступ ко всем функциям Prism UI, так любое средство автоматизации и оркестрации может с легкостью управлять Платформой. Вы можете использовать любое удобное ПО - Saltstack, Puppet, vRealize Operations, System Center Orchestrator, Ansible для автоматизации и создания собственных сценариев работы с Nutaix Кроме того, любые сторонние разработчики могут создавать свои пользовательские интерфейсы для Платформы и отправлять запросы через REST.
Ниже показан инструмент удобной работы с API - Nutanix REST API Explorer, который позволяет отправлять запросы и получать примеры ответов:
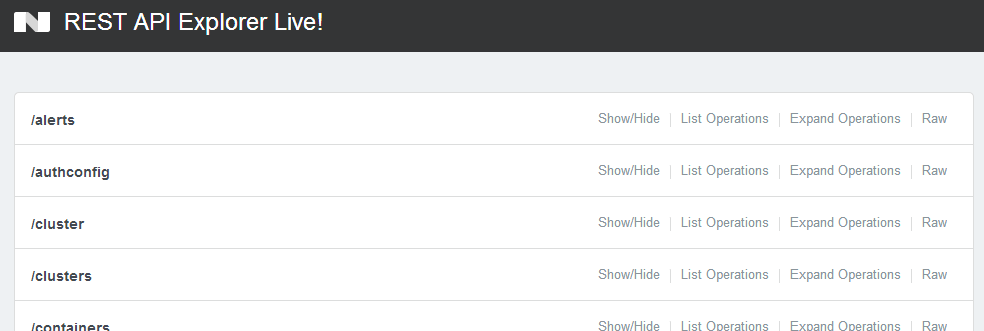
По каждой операции можно получить подробнейшую информацию и примеры вызовов REST:
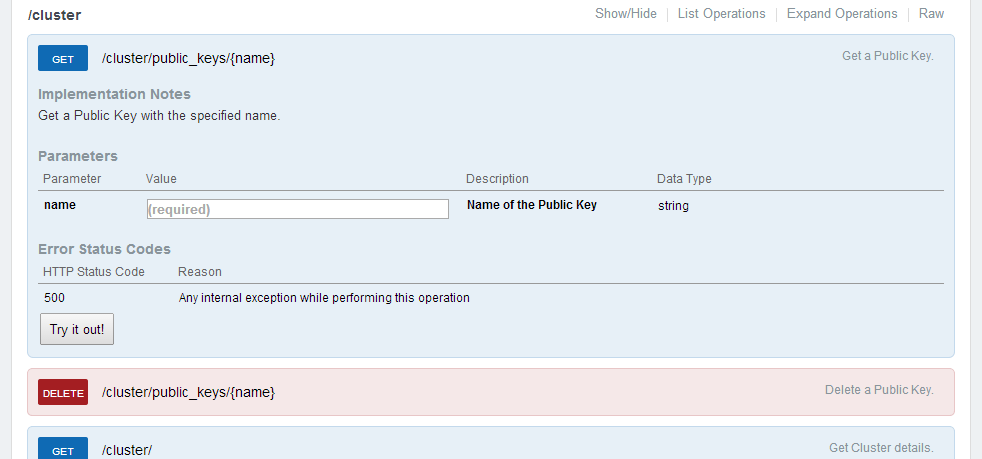
Примечание
Схема аутентификации API
Начиная с версии 4.5.x используется стандартная аутентификация через HTTPS для проверки подлинности запросов по HTTP.
ACLI
The Acropolis CLI (ACLI) это командный интерфейс к платформе, являющийся неотъемлемой его частью. Этот компонент стал доступным, начиная с версии 4.1.2
Примечание: Все эти действия могут быть выполнены так же через веб-интерфейс и REST API. Я использую эти команды для автоматизации рутинных задач с помощью скриптов.
Вход в ACLI
Описание: Вход в оболочку ACLI (с любой CVM)
Acli
OR
Описание: Вход в оболочку ACLI через консоль Linux
ACLI <Command>
Вывод ACLI в формате json
Описание: Просмотр узлов в кластере
Acli –o json
Список узлов
Описание: Просмотр узлов в кластере
host.list
Создание сети
Описание: Создание сети на базе VLAN
net.create <TYPE>.<ID>[.<VSWITCH>] ip_config=<A.B.C.D>/<NN>
Пример: net.create vlan.133 ip_config=10.1.1.1/24
Список сетей
Описание: Список сетей
net.list
Создание пула DHCP
Описание: Создание пула DHCP
net.add_dhcp_pool <NET NAME> start=<START IP A.B.C.D> end=<END IP W.X.Y.Z>
Примечание: Адрес .254 всегда резервируется под встроенный сервер DHCP, если он не был указан пользователем при создании сети
Пример: net.add_dhcp_pool vlan.100 start=10.1.1.100 end=10.1.1.200
Детальное описание сети
Описание: Подробный список ВМ в сети, их имен / UUID, MAC адресов и IP
net.list_vms <NET NAME>
Пример: net.list_vms vlan.133
Настройка сервиса DHCP DNS для сети
Описание: Настройка DHCP DNS
net.update_dhcp_dns <NET NAME> servers=<COMMA SEPARATED DNS IPs> domains=<COMMA SEPARATED DOMAINS>
Пример: net.set_dhcp_dns vlan.100 servers=10.1.1.1,10.1.1.2 domains=splab.com
Создание виртуальной машины
Описание: Создание ВМ
vm.create <COMMA SEPARATED VM NAMES> memory=<NUM MEM MB> num_vcpus=<NUM VCPU> num_cores_per_vcpu=<NUM CORES> ha_priority=<PRIORITY INT>
Пример: vm.create testVM memory=2G num_vcpus=2
Массовое создание ВМ
Описание: Массовое создание ВМ
vm.create <CLONE PREFIX>[<STARTING INT>..<END INT>] memory=<NUM MEM MB> num_vcpus=<NUM VCPU> num_cores_per_vcpu=<NUM CORES> ha_priority=<PRIORITY INT>
Пример: vm.create testVM[000..999] memory=2G num_vcpus=2
Клонирование существующей ВМ
Описание: Create clone of existing VM
vm.clone <CLONE NAME(S)> clone_from_vm=<SOURCE VM NAME>
Пример: vm.clone testClone clone_from_vm=MYBASEVM
Создание нескольких клонов из существующей ВМ
Описание: Массовое создание клонов из существующей ВМ
vm.clone <CLONE PREFIX>[<STARTING INT>..<END INT>] clone_from_vm=<SOURCE VM NAME>
Пример: vm.clone testClone[001..999] clone_from_vm=MYBASEVM
Создание диска и подключение его к ВМ
# Описание: Создание диска ВМ
vm.disk_create <VM NAME> create_size=<Size and qualifier, e.g. 500G> container=<CONTAINER NAME>
Пример: vm.disk_create testVM create_size=500G container=default
Подключение сетевого интерфейса к ВМ
Описание: Создание и подключение сетевого интерфейса к ВМ
vm.nic_create <VM NAME> network=<NETWORK NAME> model=<MODEL>
Пример: vm.nic_create testVM network=vlan.100
Настройка загрузочного диска ВМ
Описание: Настройка загрузочного диска ВМ
Настройка загрузочного диска, через указание специфического id
vm.update_boot_device <VM NAME> disk_addr=<DISK BUS>
Пример: vm.update_boot_device testVM disk_addr=scsi.0
Настройка CDROM в качестве загрузочного диска
Установка загрузки с CDrom
vm.update_boot_device <VM NAME> disk_addr=<CDROM BUS>
Пример: vm.update_boot_device testVM disk_addr=ide.0
Монтирование ISO
Описание: Монтирование ISO
Порядок действий:
1. Загрузить ISOs в контейнер
2. Создать белый список IP-адресов клиента
3. Загрузить ISOs в общую папку
Создание CDrom с ISO
vm.disk_create <VM NAME> clone_nfs_file=<PATH TO ISO> cdrom=true
Пример: vm.disk_create testVM clone_nfs_file=/default/ISOs/myfile.iso cdrom=true
Если CDrom уже создан - просто смонтируйте его
vm.disk_update <VM NAME> <CDROM BUS> clone_nfs_file<PATH TO ISO>
Пример: vm.disk_update atestVM1 ide.0 clone_nfs_file=/default/ISOs/myfile.iso
Отключение ISO от CDrom
Описание: Отключение образа ISO от CDrom
vm.disk_update <VM NAME> <CDROM BUS> empty=true
Включение ВМ
Описание:Включение ВМ
vm.on <VM NAME(S)>
Пример: vm.on testVM
Включение всех ВМ
Пример: vm.on *
Включение всех ВМ по префиксу
Пример: vm.on testVM*
Включение списка ВМ
Пример: vm.on testVM[0-9][0-9]
NCLI
Примечание: Все эти действия могут быть выполнены через веб-интерфейс и REST API. Я использую эти команды для написания автоматизации рутинных задач с помощью скриптов.
Добавление подсети в белый список NFS
Описание: Добавление подсети в белый список NFS
ncli cluster add-to-nfs-whitelist ip-subnet-masks=10.2.0.0/255.255.0.0
Получение информации о версии ПО Nutanix
Описание: Получение информации о версии ПО Nutanix
ncli cluster version
Отображение скрытых опций NCLI
Описание: Отображение скрытых опций и команд NCLI
ncli helpsys listall hidden=true [detailed=false|true]
Список пулов хранения
Описание: Список всех существующих пулов хранения
ncli sp ls
Список контейнеров
Описание: Список всех существующих контейнеров
ncli ctr ls
Создание контейнеров
Описание: Создание нового контейнера
ncli ctr create name=<NAME> sp-name=<SP NAME>
Список ВМ
Описание: Список всех существующих ВМ
ncli vm ls
Список публичных ключей
Описание: Список всех существующих публичных ключей
ncli cluster list-public-keys
Добавление публичных ключей
Описание: Добавление публичных ключей для доступа к кластеру
Копирование публичных ключей на CVM
Добавление публичных ключей
ncli cluster add-public-key name=myPK file-path=~/mykey.pub
Удаление публичных ключей
Описание: Удаление публичных ключей
ncli cluster remove-public-keys name=myPK
Создание домена защиты
Описание: Создание домена защиты
ncli pd create name=<NAME>
Создание кластера назначения
Описание: Создание кластера назначения для выполнения репликации
ncli remote-site create name=<NAME> address-list=<Remote Cluster IP>
Создание домена защиты для всех ВМ в рамках контейнера
Описание: Защита всех ВМ в контейнере
ncli pd protect name=<PD NAME> ctr-id=<Container ID> cg-name=<NAME>
Создание домена защиты для конкретных ВМ
Описание: Защита конкретных ВМ
ncli pd protect name=<PD NAME> vm-names=<VM Name(s)> cg-name=<NAME>
Создание домена защиты для объектов хранилища (они же vDisk)
Описание: Защита конкретных объектов хранилища
ncli pd protect name=<PD NAME> files=<File Name(s)> cg-name=<NAME>
Создание снимка домена защиты
Описание: Разовое создание снимка домена защиты
ncli pd add-one-time-snapshot name=<PD NAME> retention-time=<seconds>
Создание расписания для создания снимков и репликации на кластер назначения
Описание: Создание расписания для создания снимков и репликации на кластер(ы) назначения
ncli pd set-schedule name=<PD NAME> interval=<seconds> retention-policy=<POLICY> remote-sites=<REMOTE SITE NAME>
Статус задач репликации
Описание: Статус задач репликации
ncli pd list-replication-status
Перенос домена защиты на другой кластер
Описание: Перенос домена защиты на другой кластер
ncli pd migrate name=<PD NAME> remote-site=<REMOTE SITE NAME>
Активация домена защиты
Описание: Активация домена защиты на кластере назначения
ncli pd activate name=<PD NAME>
Включение теневых клонов для DSF
Описание: Включение функции создания теневых клонов DSF
ncli cluster edit-params enable-shadow-clones=true
Активация функции дедупликации для vDisk
Описание: Включение функции создания снимков и дедупдликации для конкретного vDisk
ncli vdisk edit name=<VDISK NAME> fingerprint-on-write=<true/false> on-disk-dedup=<true/false>
Проверка состояния отказоуствойчивости кластера
# Статус узлов
ncli cluster get-domain-fault-tolerance-status type=node
# Статус блоков
ncli cluster get-domain-fault-tolerance-status type=rackable_unit
Командлеты для PowerShell
Ниже мы рассмотрим командлеты для PowerShell от Nutanix и то как их использовать, а так же остановимся на некоторых основных моментах касаемо Windows PowerShell.
Основы
Windows PowerShell это мощная командная оболочка (отсюда и название ;P) а так же встроенный язык для автоматизации на основе фреймворка .NET Это очень простой в использовании язык, созданный быть интерактивным и интуитивным. Ключевые элементы конструкций PowerShell:
CMDlets (командлеты)
CMDlets это команды или классы .NET которые выполняют те или иные операции. Они следуют методологии получения и отправки запросов и использую структуру <Глагол>-<Существительное>. Например: Get-Process, Set-Partition, и так далее.
Конвейеры
Конвейеры важная конструкция в PowerShell (так же как и в Linux) и может очень упростить некоторые конструкции. С конвейером вы можете передавать результат одной секции конвейера в следующую, в качестве входных параметров. Конвейер может иметь такую длину, как вам необходимо. Простым примером конвейера может быть получение списка процессов, поиск конкретных по фильтру и сортировка результата:
Get-Service | where {$_.Status -eq "Running"} | Sort-Object Name
Кроме того, конвейер может быть использован для каждого значения в массиве, например:
# Для каждого значения в массиве
$myArray | %{
# Выполнить какие-то действия
}
Ключевые типы объектов
Ниже рассмотрим несколько ключевых объектов PowerShell. Тип объекта можно получить через метод .getType(), например: $someVariable.getType() вернет тип для объекта.
Переменные
$myVariable = "foo"
Примечание: Можно поместить в переменную конвейер:
$myVar2 = (Get-Process | where {$_.Status -eq "Running})
В этом примере переменная получит результат выполнения команды в качестве значения.
Массив
$myArray = @("Value","Value")
Примечание: Можно создать массив из массивов, хэш-таблиц или пользовательских типов
Хэш-таблица
$myHash = @{"Key" = "Value";"Key" = "Value"}
Полезные команды
Получение справки по конкретному командлету (так же как man в Linux)
Get-Help <имя командлета>
Пример: Get-Help Get-Process
Список свойств и методов команды или объекта
<Вырожение или объект> | Get-Member
Пример: $someObject | Get-Member
Основные командлеты Nutanix и их использование
Загрузить установщик командлетов Nutanix можно из Prism UI (после версии 4.0.1):
Загрузка оснастки Nutanix
Проверьте загружена ли оснастка Nutanix, если нет - загрузите
if ( (Get-PSSnapin -Name NutanixCmdletsPSSnapin -ErrorAction SilentlyContinue) -eq $null )
{
Add-PsSnapin NutanixCmdletsPSSnapin
}
Список командлетов Nutanix
Get-Command | Where-Object{$_.PSSnapin.Name -eq "NutanixCmdletsPSSnapin"}
Подключение к кластеру Acropolis
Connect-NutanixCluster -Server $server -UserName "myuser" -Password (Read-Host "Password: " -AsSecureString) -AcceptInvalidSSLCerts
Получение списка ВМ по маске
Объявление переменной
$searchString = "myVM"
$vms = Get-NTNXVM | where {$_.vmName -match $searchString}
Выполнение
Get-NTNXVM | where {$_.vmName -match "myString"}
Выполнение и форматирование
Get-NTNXVM | where {$_.vmName -match "myString"} | ft
Получение объектов хранилища
Объявление переменной
$vdisks = Get-NTNXVDisk
Выполнение
Get-NTNXVDisk
Выполнение и форматирование
Get-NTNXVDisk | ft
Получение списка контейнеров Nutanix
Объявление переменной
$containers = Get-NTNXContainer
Выполнение
Get-NTNXContainer
Выполнение и форматирование
Get-NTNXContainer | ft
Получение списка доменов защиты
Объявление переменной
$pds = Get-NTNXProtectionDomain
Выполнение
Get-NTNXProtectionDomain
Выполнение и форматирование
Get-NTNXProtectionDomain | ft
Получение списка групп консистентности
Объявление переменной
$cgs = Get-NTNXProtectionDomainConsistencyGroup
Выполнение
Get-NTNXProtectionDomainConsistencyGroup
Выполнение и форматирование
Get-NTNXProtectionDomainConsistencyGroup | ft
Ресурсы и скрипты:
- Nutanix Github - https://github.com/nutanix/Automation
- Manually Fingerprint vDisks - http://bit.ly/1syOqch
- vDisk Report - http://bit.ly/1r34MIT
- Отчет о доменах защиты - http://bit.ly/1r34MIT
- Восстановление доменов защиты по очереди - http://bit.ly/1pyolrb
Примечание: некоторые скрипты не поддерживаются и могут быть использованы только в качестве примера.
Больше скриптов доступно на официальном гите Nutanix https://github.com/nutanix
Интеграция
OpenStack
OpenStack это открытая платформа для реализации и управления облаками. Он состоит из пользовательского интерфейса, API и инфраструктурных сервисов (сервис вычисления, хранения, и так далее).
Решение Nutanix OpenStack состоит из нескольких основных компонент:
- OpenStack Controller (OSC)
- Существующая или вновь созданная ВМ, на которой размещаются сервисы OpenStack - UI, API и служебные сервисы. Тут обрабатываются все вызовы к API OpenStack. Если в качестве платформы используется Acropolis тут же может размещаться и драйвер Acropolis OpenStack
- Acropolis OpenStack Driver
- Отвечает за обработку вызовов OpenStack RPCs от контроллера OpenStack и трансляции их в стандартный API Acropolis. Может быть развернут в рамках OCS, OVM или на отдельной ВМ.
- Служебная ВМ - Acropolis OpenStack Services (OVM)
- ВМ на которой размещаются драйверы Acropolis. Отвечает за получение вызовов OpenStack RPCs от контроллера OpenStack и трансляцией их в стандартный API Acropolis.
OSC может располагаться на существующей ВМ или сервере, или может быть развернут как часть решения Nutanix OpenStack. OVM - является вспомогательной ВМ, и разворачивается как часть решения Nutanix OpenStack.
Клиенты взаимодействуют с OSC используя стандартные методы и способы (Web UI / HTTP, SDK, CLI or API), OSC взаимодействует с OVM которая преобразует запросы OpenStack API в стандартные вызовы REST API Acropolis, через Acropolis OpenStack Driver.
Верхнеуровневая схема взаимодействия компонент:
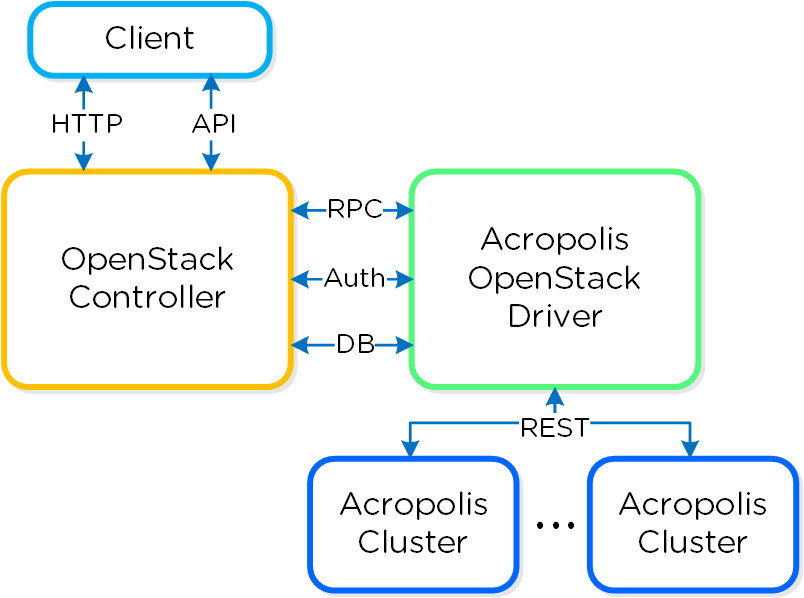
Такое решение позволяет использовать все преимущества OpenStack - пользовательский портал, API и так далее, без сложностей присущих классическим инсталляциям OpenStack. Все низкоуровневые сервисы (вычисление, хранение, сети) реализуются стандартными средствами Nutanix. А значит, нет необходимости разворачивать компоненты вроде Nova Compute, и так далее. Платформа будет принимать все стандартные запросы, и перенаправлять их к компонентам Nutanix, транслируя в вызовы Acropolis API. Кроме того, такое решение можно развернуть менее чем за 30 минут.
Поддерживаемые контроллеры OpenStack
На текущий момент (начиная с 4.5.1) поддерживаются версии OpenStack начиная с Kilo и более поздние.
Верхнеуровневый маппинг ролей:
| Объект | Роль | Контроллер OpenStack | Acropolis OVM | Кластер Acropolis | Prism |
|---|---|---|---|---|---|
| Пользовательский интерфейс | Пользовательский интерфейс и API | X | |||
| Административный интерфейс | Мониторинг и управление инфраструктурой | X | X | ||
| Оркестрация | Управление объектами (CRUD) и жизненным циклом | X | |||
| Квоты | Управоение ресурсами и лимитами на их использование | X | |||
| Пользователи, Группы и Роли | Управление на базе ролей пользователей (RBAC) | X | |||
| Единая точка входа | Сквозная авторизация | X | |||
| Интеграция с платформой | Интеграция OpenStack и Nutanix | X | |||
| Инфраструктурные сервисы | Целевая инфраструктура (вычисление, хранение, сеть) | X |
Компоненты OpenStack
OpenStack состоит из набора компонент, каждый компонент отвечает за какую-то инфраструктурную функцию. Некоторые из этих функций будут развернуты на базе контроллера OpenStack Controller, некоторые на базе Acropolis OVM.
Таблица показывает соотношение компонентов OpenStack и их инфраструктурных ролей:
| Компонент | Роль | Контролер OpenStack | Acropolis OVM |
|---|---|---|---|
| Keystone | Сервис идентификации | X | |
| Horizon | Веб-интерфейс | X | |
| Nova | Вычисление | X | |
| Swift | Объектное хранилище | X | X |
| Cinder | Блочное хранилище | X | |
| Glance | Хранилище образов | X | X |
| Neutron | Сеть | X | |
| Heat | Оркестрация | X | |
| Другие | Другие компоненты | X |
На рисунке отображено взаимодействие между компонентами OpenStack:
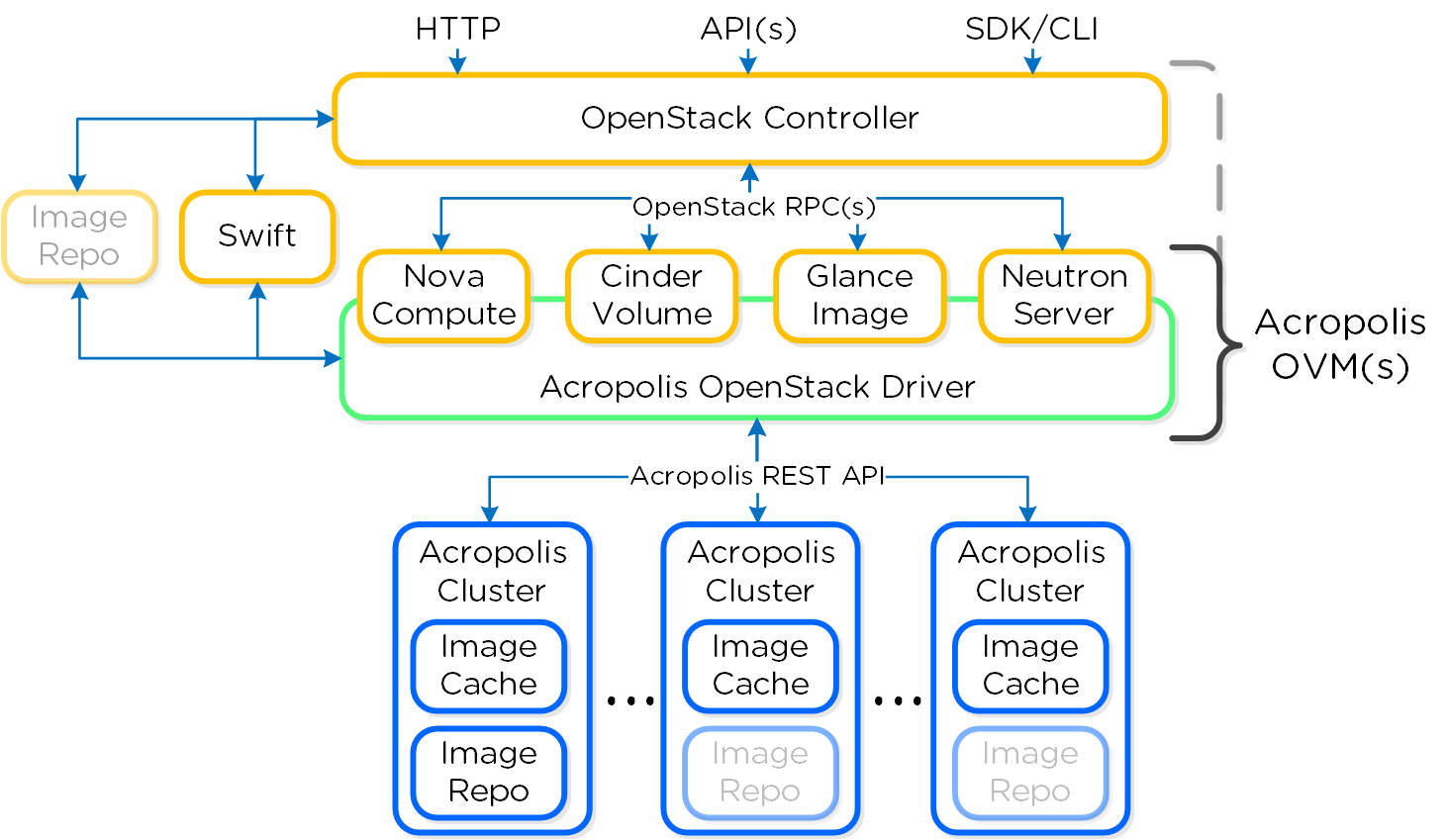
В следующем разделе мы остановимся на ключевых компонентах OpenStack и расскажем как они интегрированы с Nutanix.
Nova
Nova - подсистема управления вычислительными узлами и задачами. В решении Nutanix OpenStack каждая OVM выступает в роли вычислительного узла, так каждый Acropolis Cluster и узел внутри него могут быть использованы для создания ВМ OpenStack. Acropolis OVM управляет сервисом Nova.
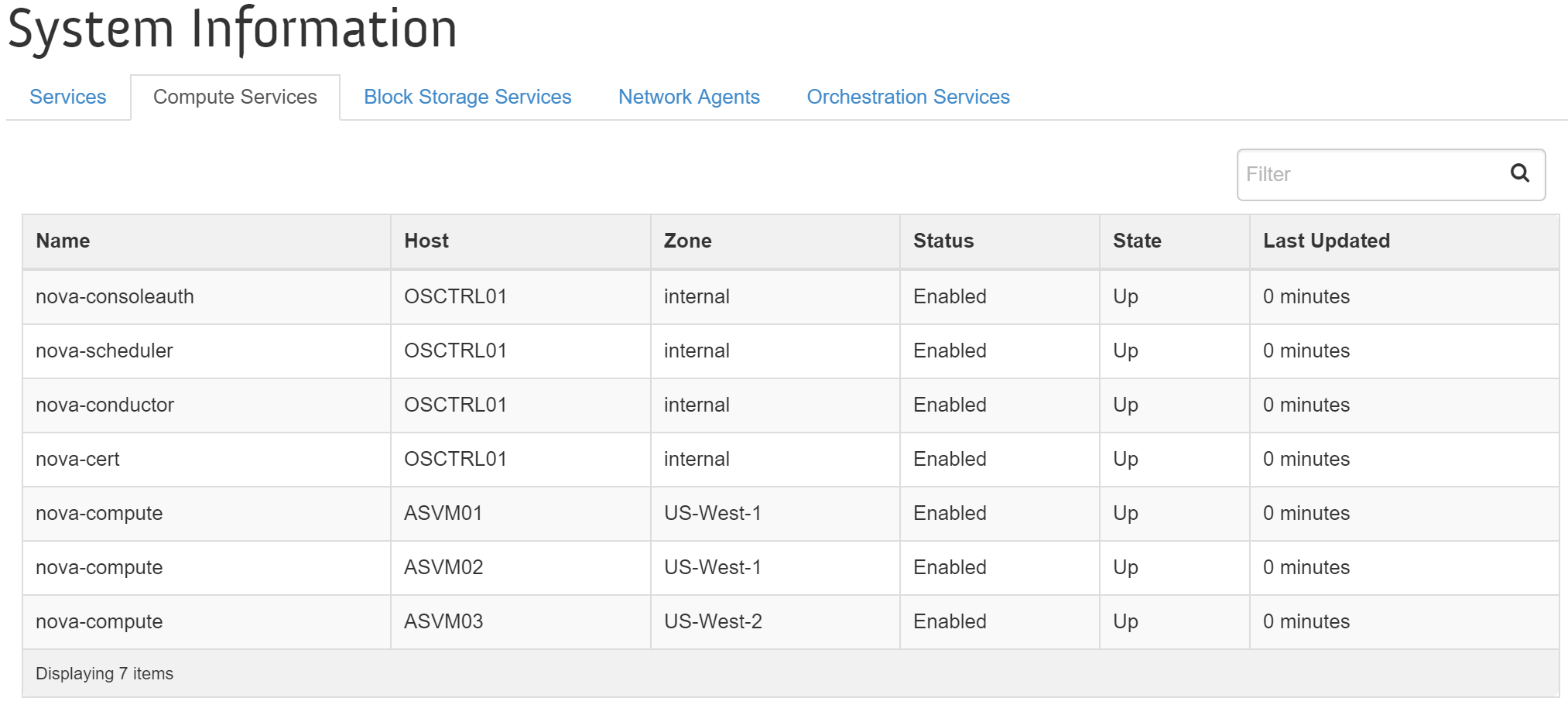
Все сервисы Nova доступны в веб-интерфейсе OpenStack на странице 'Admin'->'System'->'System Information'->'Compute Services'.
На рисунке показаны сервисы Nova, узлы и их статус:
Планировщик ресурсов Nova определяет на каком вычислительном узле (он же OVM) разместить ВМ на базе выбранных зон доступности. Такой запрос будет отправлен к выбранной OVM, а затем перенаправлен конкретному планировщику Acropolis (отвечающему за конкретный кластер). Планировщик Acropolis определит оптимальный узел для размещения ВМ внутри кластера. Конкретные узлы кластера Acropolis не отображаются в OpenStack.
Вы можете увидеть доступные "вычислительные узлы" на портале OpenStack во вкладке 'Admin'->'System'->'Hypervisors'.
На рисунке ниже отображен перечень Acropolis OVM как список вычислительных узлов OpenStack:
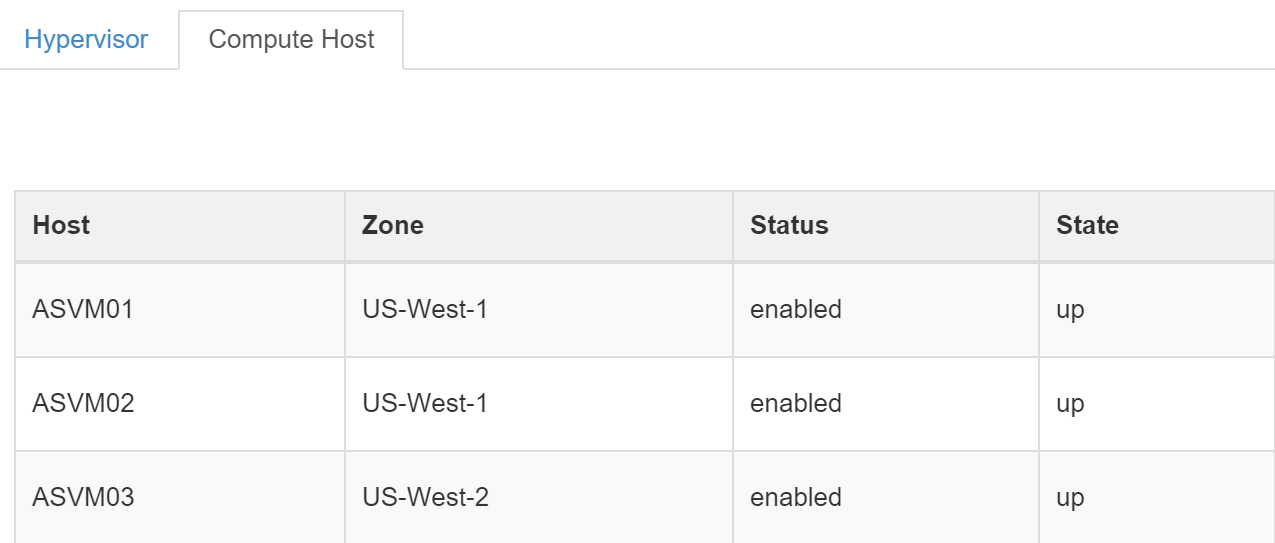
На рисунке ниже показан кластер Acropolis, OpenStack распознает его как гипервизор:

Как видно на рисунке выше - целый кластер Nutanix представлен как единственный гипервизор.
Swift
Swift - объектное хранилище, используемое для хранения файлов. Сейчас оно используется исключительно для создания и восстановления снимков и образов.
Cinder
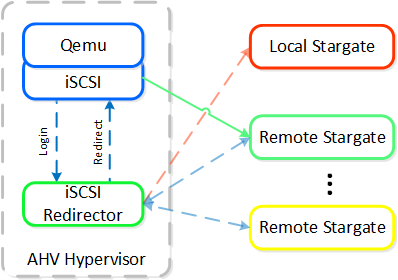
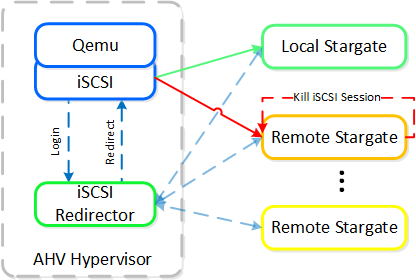
Cinder - компонент управления хранилищем для взаимодействия с iSCSI. Cinder использует API по управлению томами в Acropolis. Эти тома будут подключены к ВМ напрямую, в качестве блочных устройств.
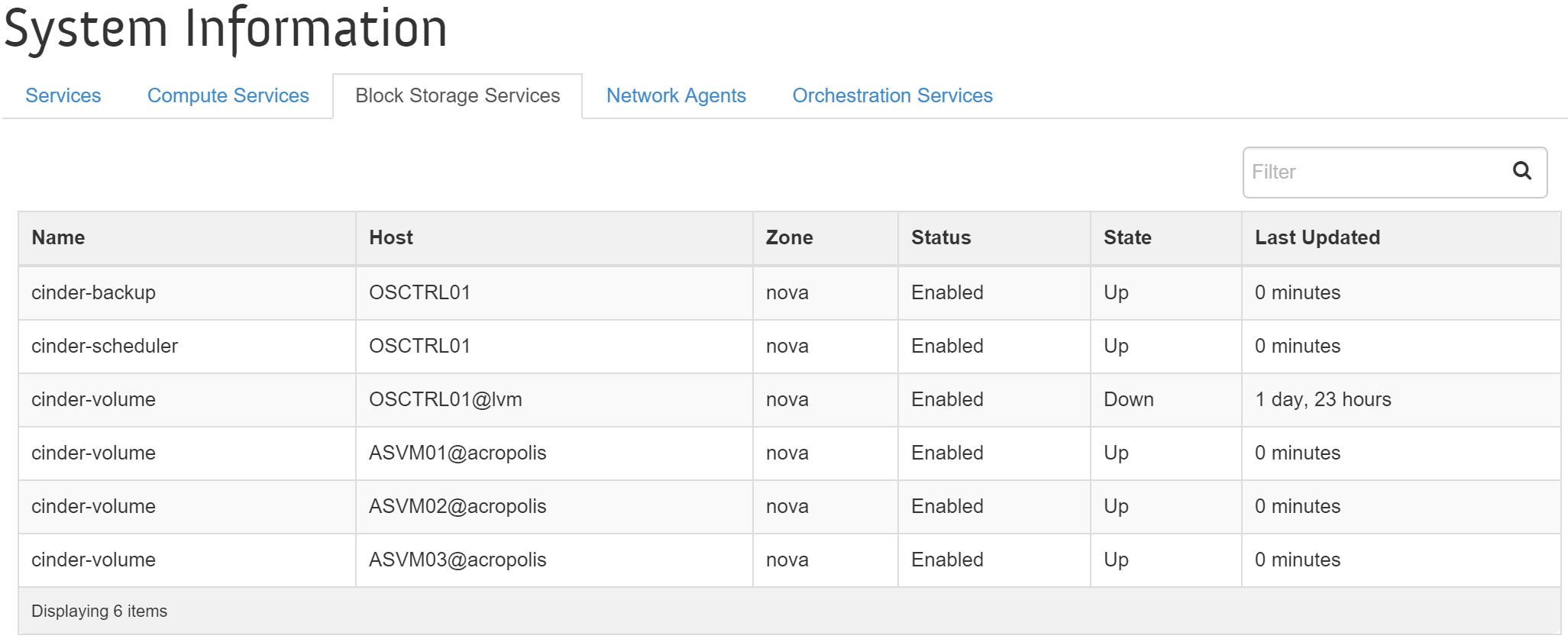
Вы можете увидеть перечень сервисов Cinder в интерфейсе OpenStack, в меню 'Admin'->'System'->'System Information'->'Block Storage Services'.
На рисунке показаны сервисы Cinder, узел и статус:
Glance - репозиторий образов
Glance это хранилище образов в инфраструктуре OpenStack. Через данный модуль происходит выдача информации о доступных для использования образов ВМ, снимков и ISO.
Репозиторий образов - хранилище образов под управлением Glance. Репозиторий может располагаться как в рамках платформы Nutanix, так и вне ее. Если образы хранятся на платформе Nutanix, они автоматически будут опубликован в OpenStack посредством Glance на OVM. Если хранилище образов настроено как внешний источник, Glance будет располагаться на контроллере OpenStack, а кэш образов будет использоваться кластером Acropolis.
Модуль Glance разворачивается для каждого кластера Acropolis и всегда содержит кэш образов. Когда Glance активирован на нескольких кластерах Nutanix - репозиторий образов будет охватывать все эти кластеры, и образы, создаваемые через портал OpenStack будут распространены по всем кластерам с Glance. Кластеры без сервиса Glance будут держать кэши образов при помощи кэша образов.
Примечание
Совет от создателей
В рамках больших инсталляций сервис Glance должен функционировать как минимум на двух кластерах Acropolis на площадку. Такая инсталляция обеспечит HA для репозитория образов даже для случая, и образы всегда будут доступны, даже если их нет в кэше.
Когда в качестве репозитория образов используется внешний ресурс, задачу доставки образов на кластер Acropolis берет на себя сервис Nova. Все необходимые образы будут перенесены в кэш образов, для быстрого доступа к ним, в случае необходимости.
Neutron
Сервис Neutron - сетевой компонент OpenStack который отвечает за настройку сети ВМ. OVM позволяет выполнять все CRUD операции, выполняемые из интерфейса OpenStack и осуществлять все необходимые задачи в Acropolis.
Вы можете посмотреть список сервисов Neutron через пользовательский интерфейс OpenStack, в меню 'Admin'->'System'->'System Information'->'Network Agents'.
На изображении показаны сервисы Neutron, узлы и статусы:
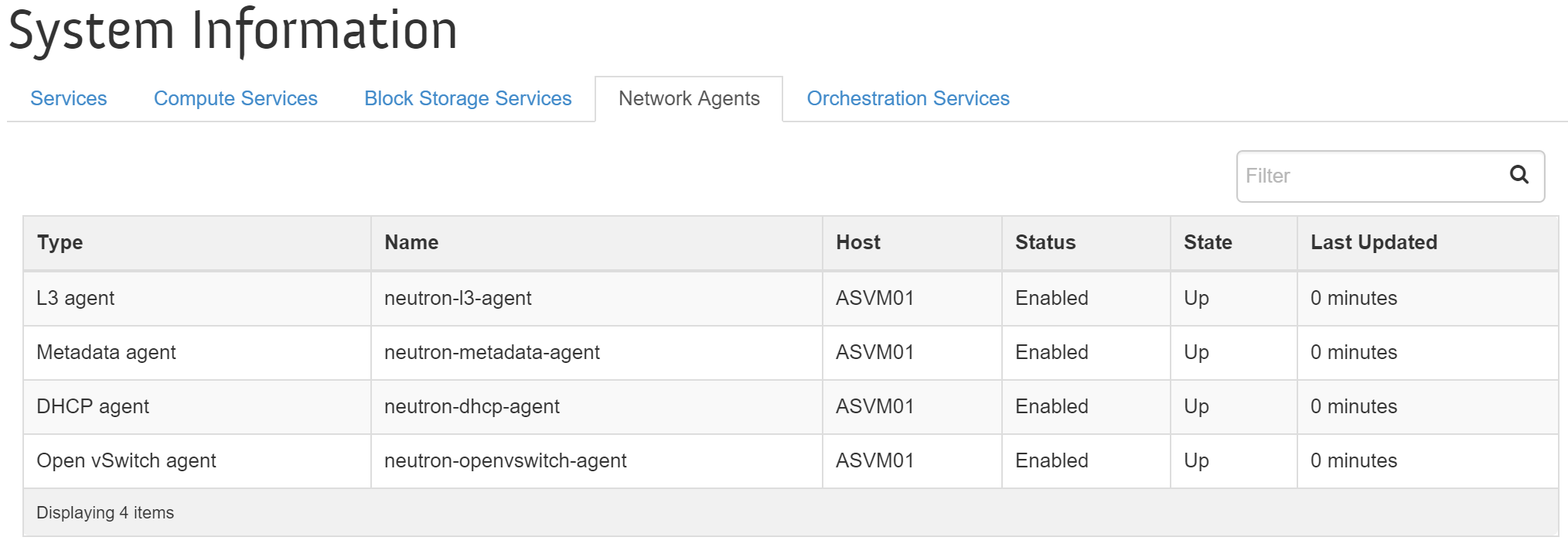 + На текущий момент поддерживаются только два типа сети Local и VLAN.
+ На текущий момент поддерживаются только два типа сети Local и VLAN.
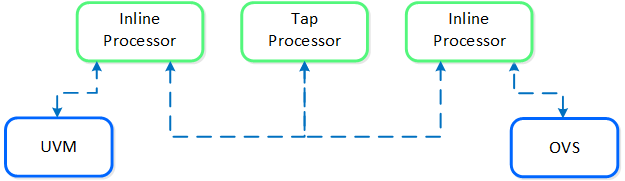
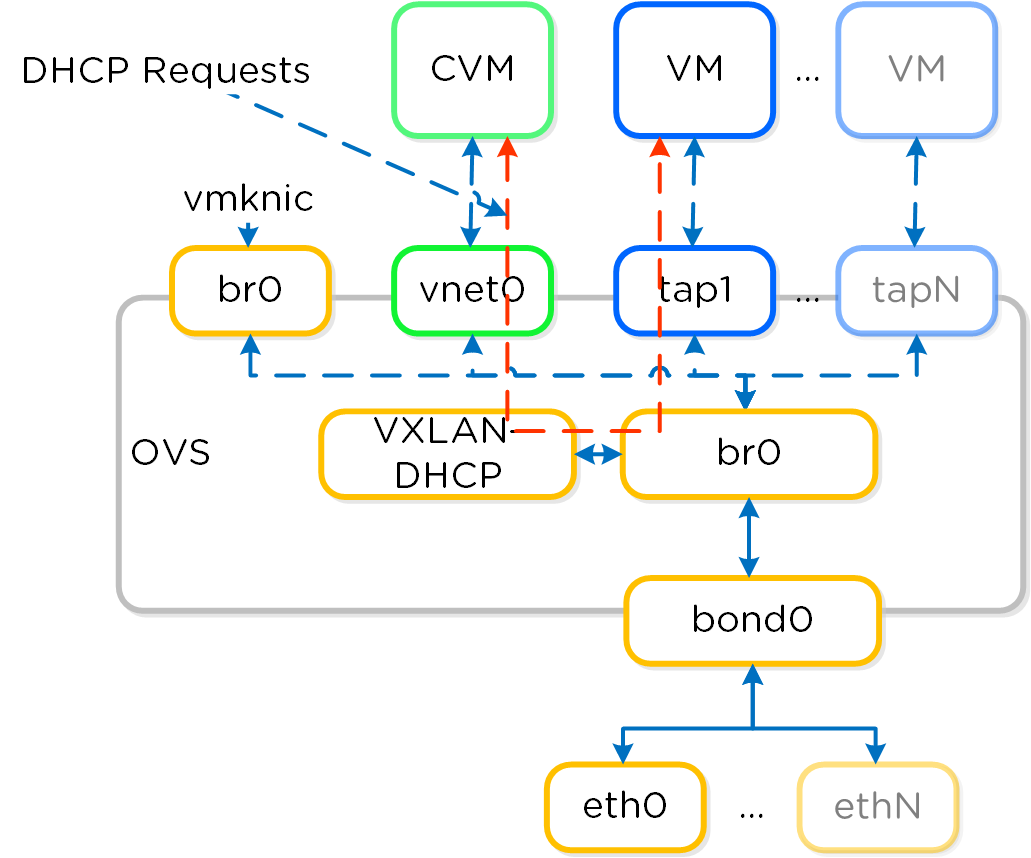
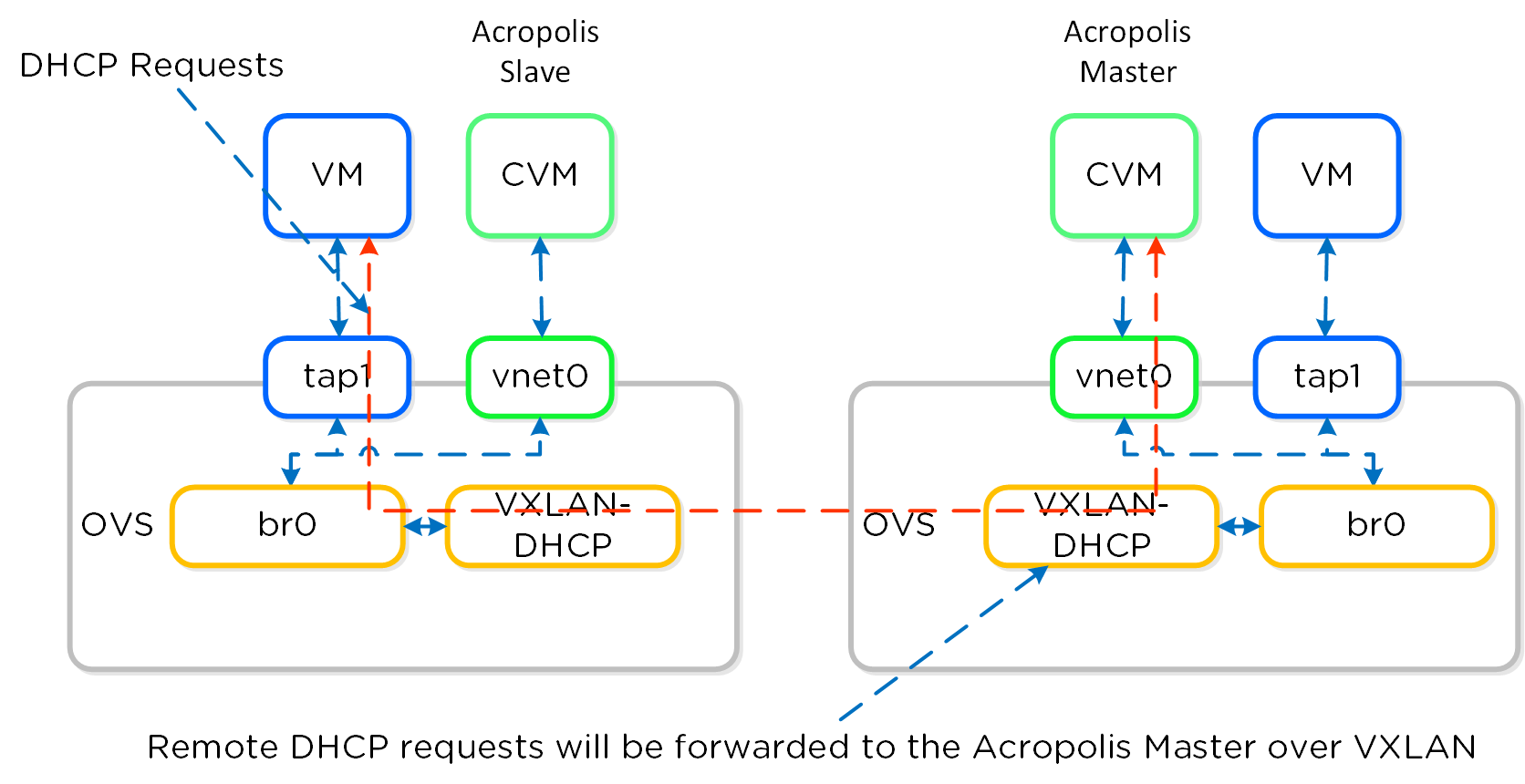
Сервис Neutron будет присваивать IP-адрес ВМ при каждой перезагрузке. В этом случае Acropolis резервирует требуемый адрес за ВМ которой он выдается. Когда ВМ выполняет DHCP запрос - Acropolis ответит на него в рамках VXLAN, как обычно в AHV.
Примечание
Поддерживаемые типы сетей
На текущий момент поддерживаются только два типа сети Local и VLAN.
Сервис Keystone и веб-интерфейс Horizon размещаются в OpenStack Controller в рамках Acropolis OVM. OVM содержит драйвер OpenStack отвечающий за трансляцию вызовов OpenStack API в стандартный Acropolis API.
Проектирование и инсталляция
Для масштабных инсталляций облачных инфраструктур важно использовать максимально распределенную инфраструктуру, которая будет отвечать запросам пользователя. И обеспечивать гибкость и локализацию вычислений и данных.
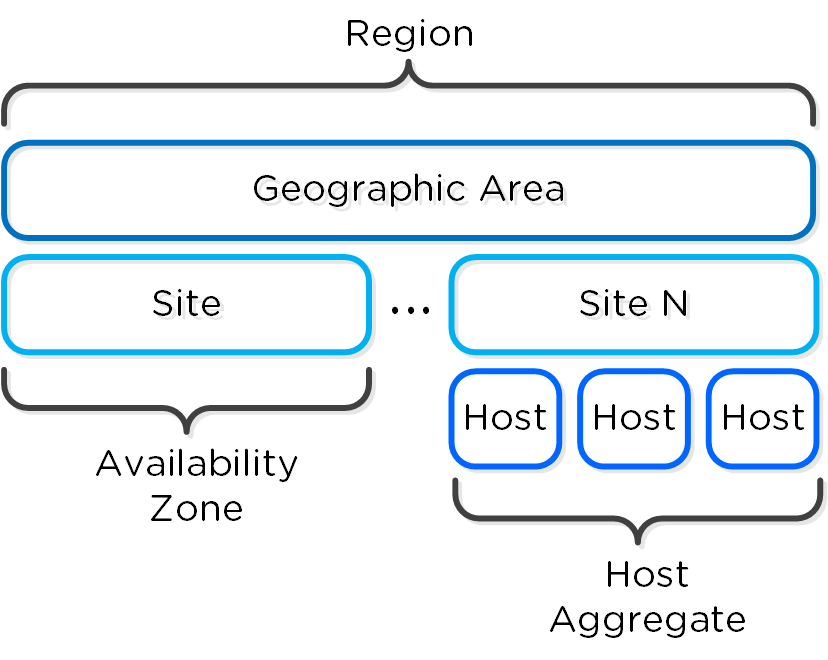
OpenStack имеет следующие высокоуровневые объекты:
-
Регионы (Region)
- Географический объект или область, включающие в себя по несколько зон доступности. Например, регионы - US-Northwest или US-West
-
Зоны доступности (Availability Zone)
- Специфический ЦОД или инсталляция, где размещаются облачные сервисы. Может включать площадки, например - US-Northwest-1 или US-West-1
-
Группы узлов (Host Aggregate)
- Группа вычислительных узлов - узел, стойка или же может соответствовать по размеру зоне доступности.
-
Вычислительные узлы (Compute Host)
- Acropolis OVM, где запущены сервисы Nova.
-
Гипервизоры (Hypervisor Host)
- Кластер Acropolis (выглядит как один узел с гипервизором).
Ниже показаны связи между этими компонентами:
Пример размещения приложений:
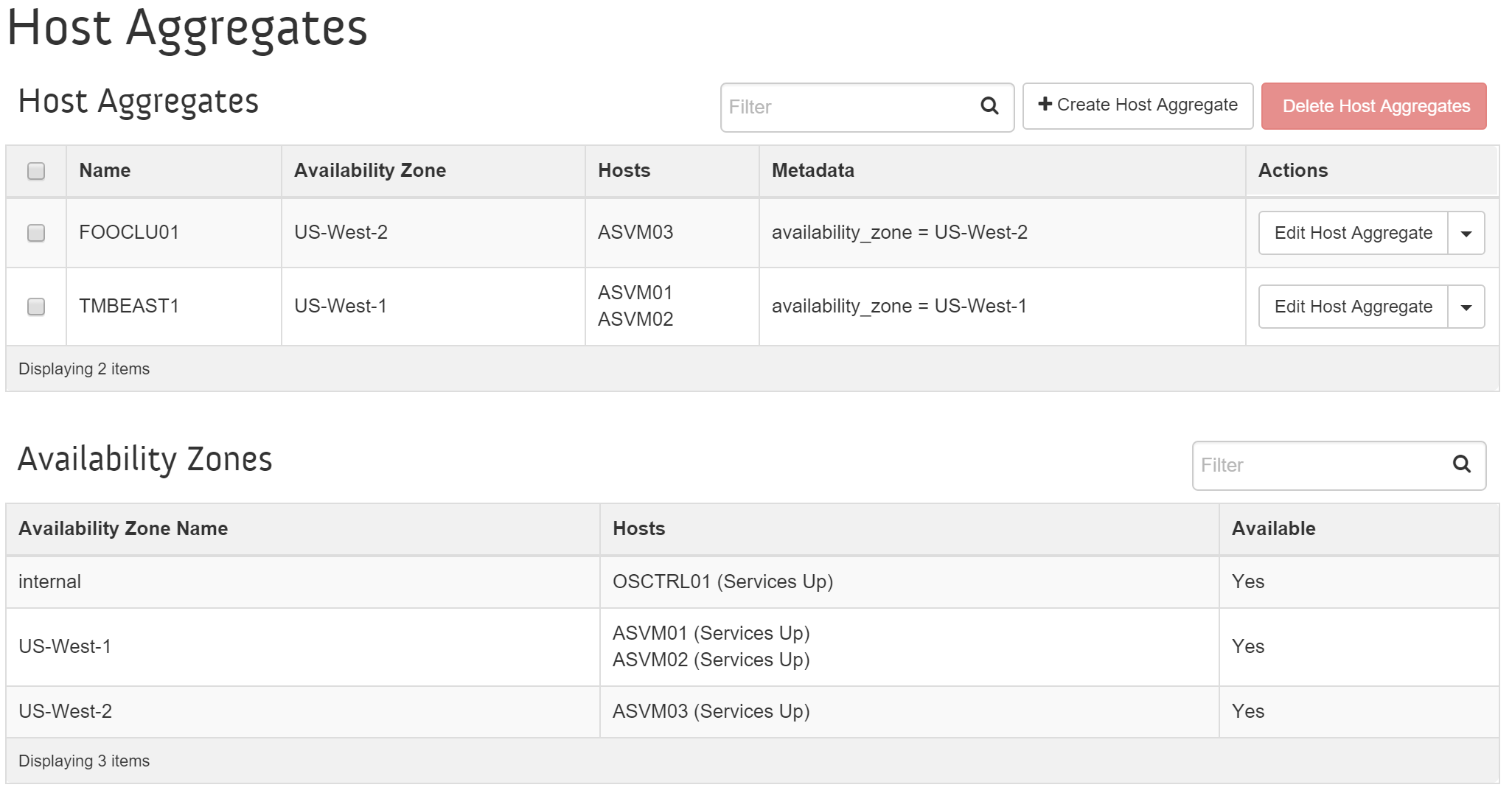
Перечень вычислительных узлов, групп и зон доступности можно посмотреть в меню интерфейса OpenStack: 'Admin'->'System'->'Host Aggregates'.
На рисунке изображены группы узлов, зоны доступности и вычислительные узлы непосредственно:
Проектирование и масштабирование
Для масштабных инсталляций рекомендуется использовать несколько Acropolis OVMs подключенных к OpenStack Controller и балансировку нагрузки между ними. Такой подход обеспечивает HA и распределяет нагрузку между несколькими OVM. OVM не содержат данных, по этому их количество может легко увеличиваться.
Ниже представлен пример схемы с использованием нескольких OVM в рамках одного ЦОД:
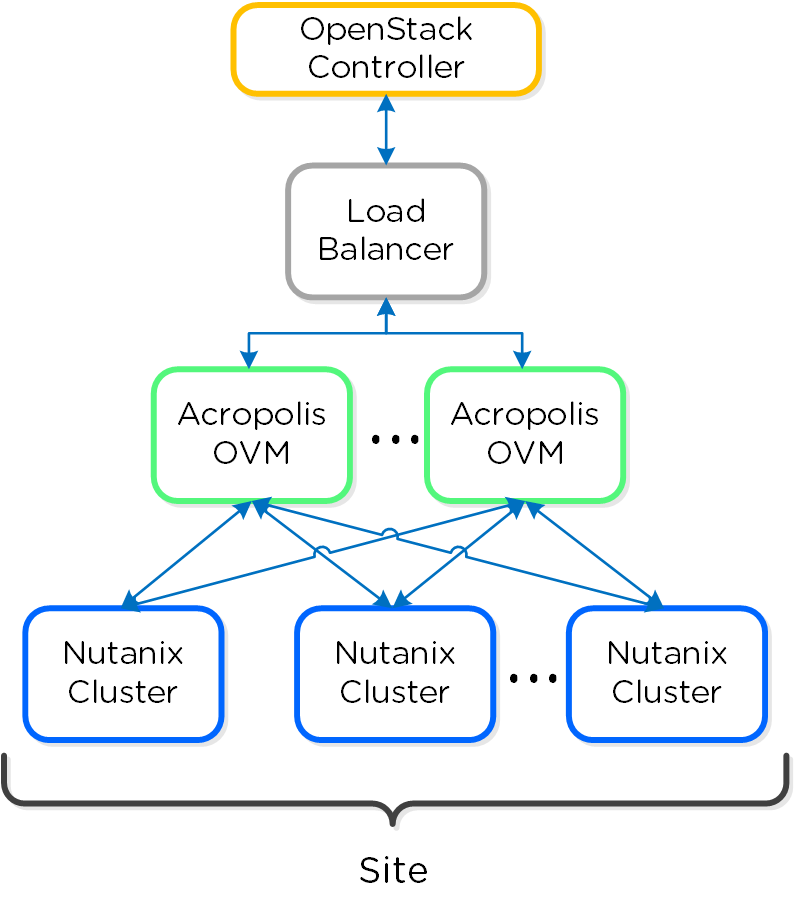
В качестве балансировщика можно использовать такие решения, как Keepalived и HAproxy.
Для инсталляций в рамках нескольких ЦОД контроллер OpenStack будет взаимодействовать с несколькими OVM на разных площадках.
На рисунке пример схемы для нескольких ЦОД:
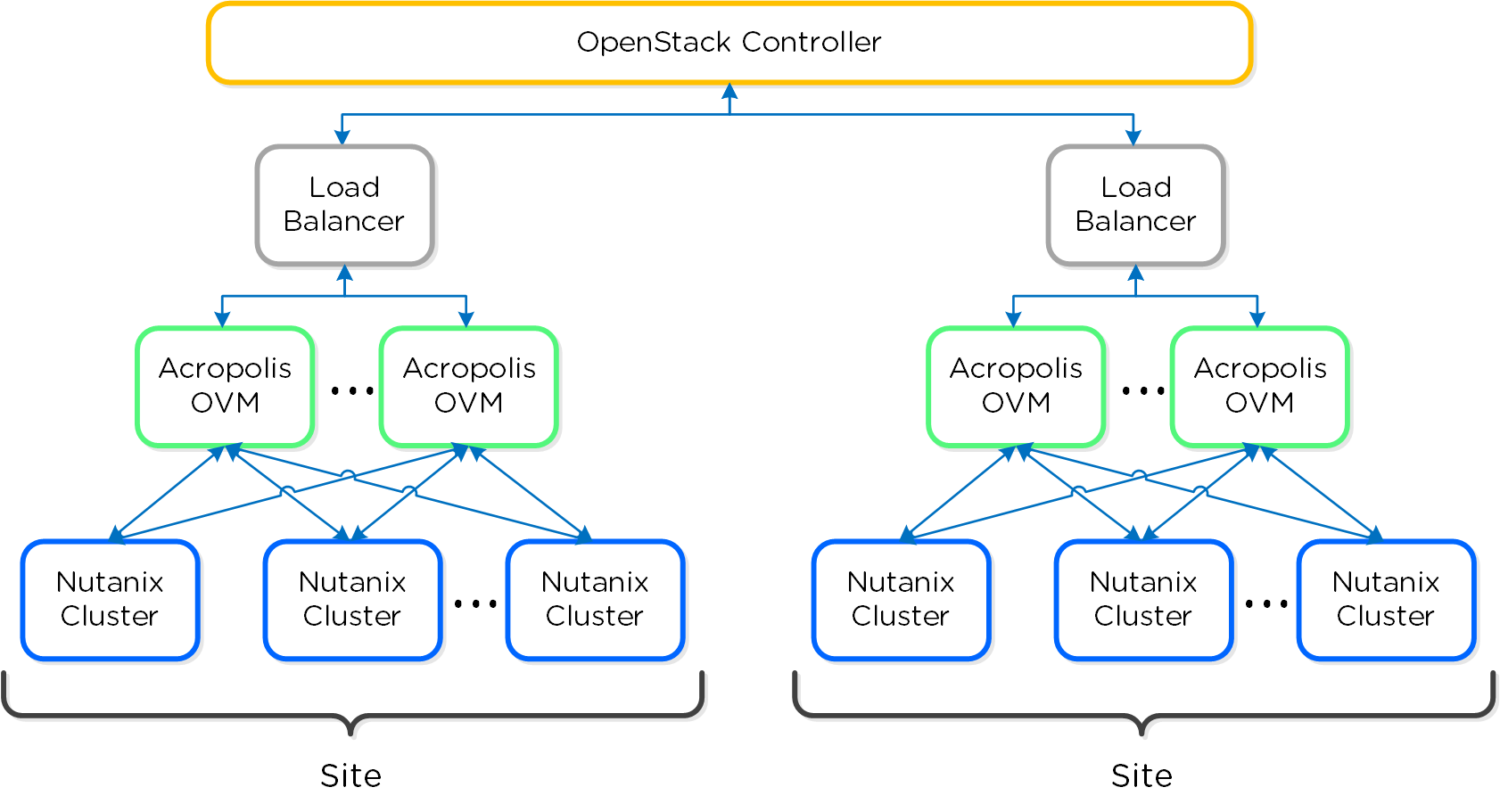
Инсталляция
OVM может быть развернут как ПО в виде RPM, в рамках CentOS / Redhat или же как ВМ целиком. Acropolis OVM может инсталлироваться на любую платформу - Nutanix или не-Nutanix, но должен иметь доступ к контроллеру OpenStack и кластеру Nutanix.
ВМ для Acropolis OVM может быть развернута на кластере Nutanix AHV следуя шагам, описанным ниже. Если OVM уже существует, этот пункт можно пропустить. Можно использовать готовый образ OVM или же использовать другую ВМ с CentOS / Redhat.
Для начала требуется импортировать все диски Acropolis OVM на кластер Acropolis. Это можно сделать, скопировав образы дисков с помощью SCP или же загрузить их по URL. Мы рассмотрим вариант с импортом образов с использованием API. Примечание: Как и говорилось ранее - можно развернуть эти ВМ где угодно, не обязательно на кластере Acropolis.
Для импорта образов требуется выполнить следующие команды:
image.create <IMAGE_NAME> source_url=<SOURCE_URL> container=<CONTAINER_NAME>
Теперь нужно создать ВМ для ПО OVM выполнив следующие команды ACLI на любой из CVM, в рамках кластера:
vm.create <VM_NAME> num_vcpus=2 memory=16G
vm.disk_create <VM_NAME> clone_from_image=<IMAGE_NAME>
vm.nic_create <VM_NAME> network=<NETWORK_NAME>
vm.on <VM_NAME>
После создания OVM - включите ее, подключиться по SSH и ввести данные учетной записи.
Примечание
Справка OVMCTL
Справочаня информация доступна при выполнении команды на OVM:
ovmctl --help
OVM поддерживает следующие типы инсталляции:
-
OVM-все-в-одном
- OVM включает все драйверы Acropolis и контроллер OpenStack
-
OVM-как-сервис
- OVM включает в себя все драйверы Acropolis и взаимодействует с внешним контроллером OpenStack
Оба типа инсталляции расписаны в разделе ниже. Вы можете использовать любой тип инсталляции, а так же переключаться между ними.
OVM-все-в-одном
Следующие шаги описывают инсталляцию OVM-все-в-одном. Для настройки требуется подключиться по SSH к OVM(s) и выполнить перечисленные команды.
# Регистрация сервиса драйвера OpenStack
ovmctl --add ovm --name <OVM_NAME> --ip <OVM_IP> --netmask <NET_MASK> --gateway <DEFAULT_GW> --domain <DOMAIN> --nameserver <DNS>
# Регистрация контроллера OpenStack
ovmctl --add controller --name <OVM_NAME> --ip <OVM_IP>
# Регистрация кластера Acropolis
ovmctl --add cluster --name <CLUSTER_NAME> --ip <CLUSTER_IP> --username <PRISM_USER> --password <PRISM_PASSWORD>
Следующие значения являются стандартными:
Количество VCPUs на ядро = 4
Стандартное имя контейнера = default
Кэш образов = disabled, URL адрес кэша образов = None
Проверяем правильность конфигурации:
ovmctl --show
Если команда вернет информацию - значит все хорошо.
OVM-как-сервис
Следующие шаги описывают инсталляцию OVM в виде сервиса. Для настройки требуется подключиться по SSH к OVM(s) и выполнить перечисленные команды.
# Регистрация сервиса драйвера OpenStack
ovmctl --add ovm --name <OVM_NAME> --ip <OVM_IP>
# Регистрация контроллера OpenStack
ovmctl --add controller --name <OS_CONTROLLER_NAME> --ip <OS_CONTROLLER_IP> --username <OS_CONTROLLER_USERNAME> --password <OS_CONTROLLER_PASSWORD>
Следующие значения являются стандартными:
Аутентификация: auth_strategy = keystone, auth_region = RegionOne
auth_tenant = services, auth_password = admin
База данных: db_{nova,cinder,glance,neutron} = mysql, db_{nova,cinder,glance,neutron}_password = admin
RPC: rpc_backend = rabbit, rpc_username = guest, rpc_password = guest
# Регистрация кластеров Acropolis
ovmctl --add cluster --name <CLUSTER_NAME> --ip <CLUSTER_IP> --username <PRISM_USER> --password <PRISM_PASSWORD>
Следующие значения являются стандартными:
Количество VCPUs на ядро = 4
Стандартное имя контейнера = default
Кэш образов = disabled, URL адрес кэша образов = None
Если при инсталляции контроллера OpenStack используются нестандартные пароли необходимо обновить их:
# Обновление паролей контроллера
ovmctl --update controller --name <OS_CONTROLLER_NAME> --auth_nova_password <> --auth_glance_password <> --auth_neutron_password <> --auth_cinder_password <> --db_nova_password <> --db_glance_password <> --db_neutron_password <> --db_cinder_password <>
Проверяем правильность конфигурации:
ovmctl --show
Теперь, когда OVM настроена, требуется настроить контроллер OpenStack на использование Glance и Neutron.
Подключитесь к контроллеру OpenStack и введите следующие команды:
# enter keystonerc_admin
source ./keystonerc_admin
Для начала требуется удалить существующие записи:
# Определите старый id сервиса Glance (порт 9292)
keystone endpoint-list
# Удалите старую запись
keystone endpoint-delete <GLANCE_ENDPOINT_ID>
Теперь нужно создать новую запись Glance которая будет указывать на OVM:
# Определите id сервиса Glance
keystone service-list | grep glance
# Вывод будет похож на:
| 9e539e8dee264dd9a086677427434982 | glance | image |
# Добавьте запись
keystone endpoint-create \
--service-id <GLANCE_SERVICE_ID> \
--publicurl http://<OVM_IP>:9292 \
--internalurl http://<OVM_IP>:9292 \
--region <REGION_NAME> \
--adminurl http://<OVM_IP>:9292
Теперь нужно удалить запись Neutron, указывающую на контроллер:
# Определите id старого сервиса Neutron (порт 9696)
keystone endpoint-list
# Удалите старую запись Neutron
keystone endpoint-delete <NEUTRON_ENDPOINT_ID>
Далее - создать новую запись для Neutron, которая будет указывать на OVM:
# Определите id сервиса Neutron
keystone service-list | grep neutron
# Вывод будет похож на:
| f4c4266142c742a78b330f8bafe5e49e | neutron | network |
# Добавьте новую запись Neutron
keystone endpoint-create \
--service-id <NEUTRON_SERVICE_ID> \
--publicurl http://<OVM_IP>:9696 \
--internalurl http://<OVM_IP>:9696 \
--region <REGION_NAME> \
--adminurl http://<OVM_IP>:9696
После обновления записей нужно обновить конфигурацию сервисов Nova и Cinder, указать адрес OVM в качестве адреса Glance сервиса.
Сначала нужно внести изменения в файл Nova.conf - /etc/nova/nova.conf:
[glance]
...
# Default glance hostname or IP address (string value)
host=<OVM_IP>
# Default glance port (integer value)
port=9292
...
# A list of the glance api servers available to nova. Prefix
# with https:// for ssl-based glance api servers.
# ([hostname|ip]:port) (list value)
api_servers=<OVM_IP>:9292
Далее - отключить сервис nova-compute на контроллере OpenStack (если еще не отключен):
systemctl disable openstack-nova-compute.service
systemctl stop openstack-nova-compute.service
service openstack-nova-compute stop
Затем внести изменения в файл /etc/cinder/cinder.conf :
# Default glance host name or IP (string value)
glance_host=<OVM_IP>
# Default glance port (integer value)
glance_port=9292
# A list of the glance API servers available to cinder
# ([hostname|ip]:port) (list value)
glance_api_servers=$glance_host:$glance_port
Так же требуется закомментировать строки:
# Comment out the following lines in cinder.conf
#enabled_backends=lvm
#[lvm]
#iscsi_helper=lioadm
#volume_group=cinder-volumes
#iscsi_ip_address=
#volume_driver=cinder.volume.drivers.lvm.LVMVolumeDriver
#volumes_dir=/var/lib/cinder/volumes
#iscsi_protocol=iscsi
#volume_backend_name=lvm
Затем отключить сервис cinder на контроллере OpenStack:
systemctl disable openstack-cinder-volume.service
systemctl stop openstack-cinder-volume.service
service openstack-cinder-volume stop
Затем отключить сервис glance-image на контроллере OpenStack:
systemctl disable openstack-glance-api.service
systemctl disable openstack-glance-registry.service
systemctl stop openstack-glance-api.service
systemctl stop openstack-glance-registry.service
service openstack-glance-api stop
service openstack-glance-registry stop
После изменения конфигурационных файлов требуется перезагрузить сервисы Nova и Cinder, чтобы изменения вступили в силу. Это можно сделать или используя команды ниже или запустив скрипты, которые доступны для загрузки.
# Перезапуск сервисов Nova
service openstack-nova-api restart
service openstack-nova-consoleauth restart
service openstack-nova-scheduler restart
service openstack-nova-conductor restart
service openstack-nova-cert restart
service openstack-nova-novncproxy restart
# или запустите скрипт:
~/openstack/commands/nova-restart
# Перезапуск сервисов Cinder
service openstack-cinder-api restart
service openstack-cinder-scheduler restart
service openstack-cinder-backup restart
# или запустите скрипт:
~/openstack/commands/cinder-restart
Puppet
Puppet - решение для управления жизненным циклом конфигураций (LCM) которое широко используется в DevOps.
Поиск и устранение неисправностей
Расположение основных журнальных файлов
| Компонент | Путь к журналу |
|---|---|
| Keystone | /var/log/keystone/keystone.log |
| Horizon | /var/log/horizon/horizon.log |
| Nova | /var/log/nova/nova-api.log /var/log/nova/nova-scheduler.log /var/log/nova/nove-compute.log* |
| Swift | /var/log/swift/swift.log |
| Cinder | /var/log/cinder/api.log /var/log/cinder/scheduler.log /var/log/cinder/volume.log |
| Glance | /var/log/glance/api.log /var/log/glance/registry.log |
| Neutron | /var/log/neutron/server.log /var/log/neutron/dhcp-agent.log* /var/log/neutron/l3-agent.log* /var/log/neutron/metadata-agent.log* /var/log/neutron/openvswitch-agent.log* |
Журналы помеченные звездочкой доступны только на Acropolis OVM.
Примечание
Совет от создателей
Если сервер OpenStack Manager помечен как 'down', даже если сервис в OVM функционирует - проверьте NTP. Большинство сервисов требует синхронизации времени между контроллером OpenStack и Acropolis OVM.
Справочник по командам
Загрузите источник для Keystone source (выполняется перед выполнением других команд)
source keystonerc_admin
Список сервисов Keystone
keystone service-list
Список записей Keystone
keystone endpoint-list
Создание записи Keystone
keystone endpoint-create \
--service-id=<SERVICE_ID> \
--publicurl=http://<IP:PORT> \
--internalurl=http://<IP:PORT> \
--region=<REGION_NAME> \
--adminurl=http://<IP:PORT>
Список сервисов Nova
nova list
Просмотр информации о сервисе
nova show <INSTANCE_NAME>
Список гипервизоров Nova
nova hypervisor-list
Просмотр информации о гипервизорах
nova hypervisor-show <HOST_ID>
Список образов Glance
glance image-list
Просмотр информации о образах Glance
glance image-show <IMAGE_ID>
Part III. Книга Acropolis
a·crop·o·lis - /ɘ ' kräpɘlis/ - noun - data plane
Платформа хранения, вычисления и виртуализации.
Архитектура
Acropolis - это распределенная программная платформа управления и оркестрации.
Рассмотрим три основных компонента:
- Распределенная система управления хранилищем (Distributes Storage Fabric - DSF)
- Это то, с чего началась платформа Nutanix, это ПО тесно связано с распределённой файловой системой Nutanix (NDFS). Теперь NDFS не просто система объединяющая все диски в единый ресурсный пул, а нечто большее - платформа хранения с широчайшей функциональностью.
- Распределенная система управления приложениями (App Mobility Fabric - AMF)
- Гипервизор абстрагирует гостевые ОС от аппаратного уровня, а AMF абстрагирует выполнение задач от гипервизора (ВМ, Хранилище, контейнеры и т.д.). Это ПО позволяет динамически перемещать нагрузку между гипервизорами и облаками, именно этот компонент предоставляет возможность менять гипервизор на узлах Nutanix.
- Гипервизор
- Многофункциональный гипервизор на основе CentOS и KVM.
Все ПО Nutanix являются распределенными, такие же решения используются на уровнях виртуализации и управления ресурсами. Служебные сервисы Acropolis управляют нагрузками, ресурсами, созданием и управлением ВМ. Acropolis абстрагирует служебные подсистемы и задачи от пользовательских нагрузок.
Такая структура позволяет переносить нагрузки между гипервизорами, поставщиками облачных решений и платформами.
Ниже показана концептуальная верхнеуровневая архитектура Acropolis:
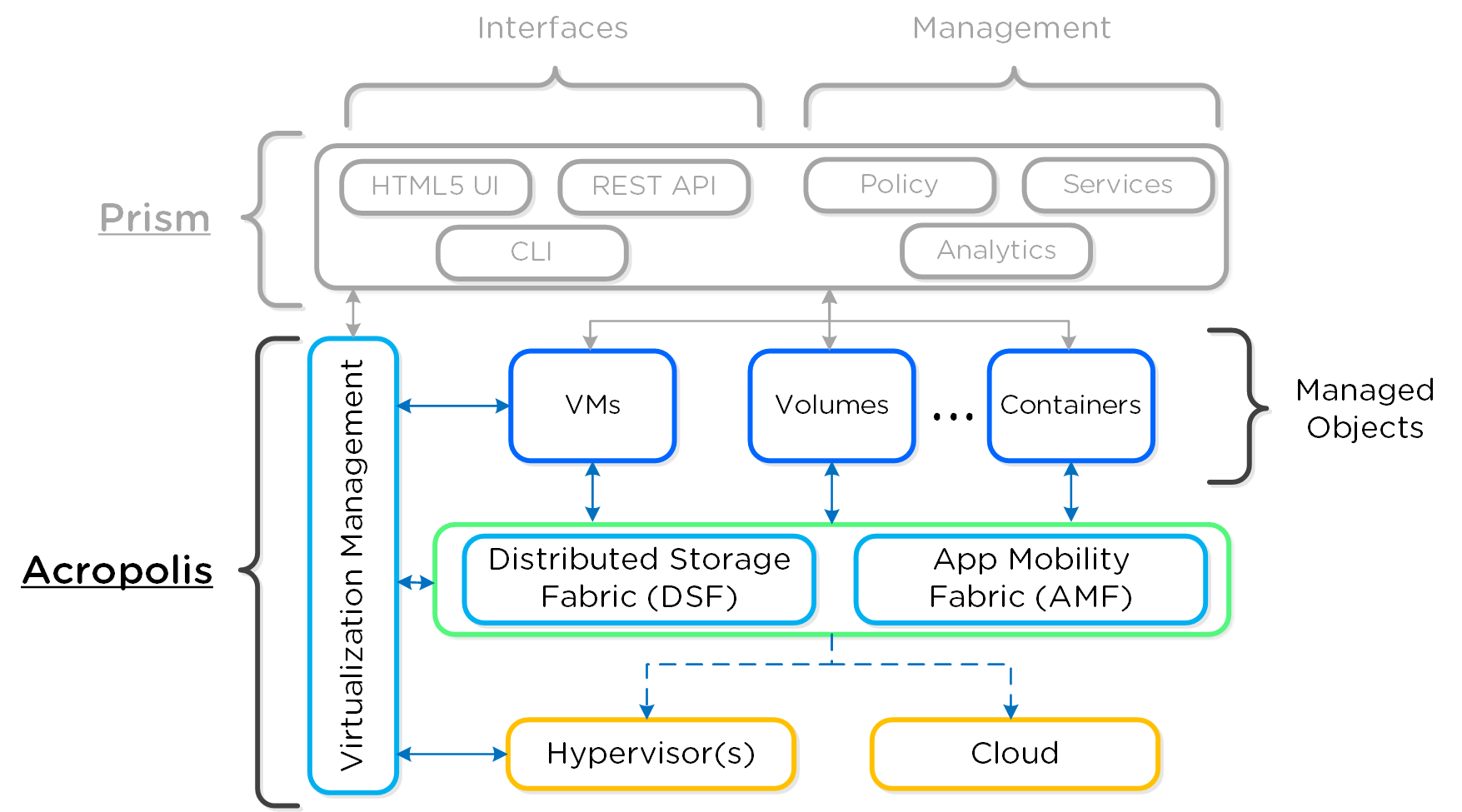
Примечание
Поддерживаемые гипервизоры
Начиная с версии ПО 4.7, управление ВМ и другими объектами поддерживаться для AHV и ESXi, однако в будущем данный список может быть увеличен. API по управлению хранилищем и операций чтения данных о объектах доступно для всех гипервизоров.
Гиперконвергентная платформа
Краткий рассказ на английском языке доступен по ссылке
Nutanix это хранилище и вычислительные мощности объединенные в единую распределенную платформу виртуализации. Платформа поставляется как программно-аппаратное решение, в виде серверных блоков по два (серия 6000/7000) или четыре вычислительных узла (серия 1000/2000/3000/3050) высотой 2U.
Каждый вычислительный узел размещает на себе гипервизор (ESXi, KVM, Hyper-V) и служебную виртуальную машину Nutanix (CVM). В рамках CVM выполняется все ПО Nutanix, обслуживаются операции I/O для гипервизора и всех ВМ запущенных на узле. Для узлов на базе VMware vSphere SCSI контроллер обслуживающий SSD и HDD диски - напрямую подключен к CVM с использованием VM-Direct Path (Intel VT-d). В случае с Hyper-V, все устройства хранения напрямую пробрасываются в CVM.
Ниже показана концептуальная верхнеуровневая архитектура компонент:
Распределенная система
Основные требования к распределенной системе:
- отсутствие любых единых точек отказа
- Система должна линейно масштабироваться
- Все операции должны быть распределены по кластеру (MapReduce)
Узлы Nutanix образуют распределенную систему - кластер Nutanix. Он обеспечивает функционирование ПО Prism и Acropolis. Все сервисы и компоненты распределены между всеми CVM кластера, чтобы обеспечить высокую доступность и линейный, предсказуемый рост производительности при масштабировании.
Ниже приведена структурная схема кластера Nutanix:
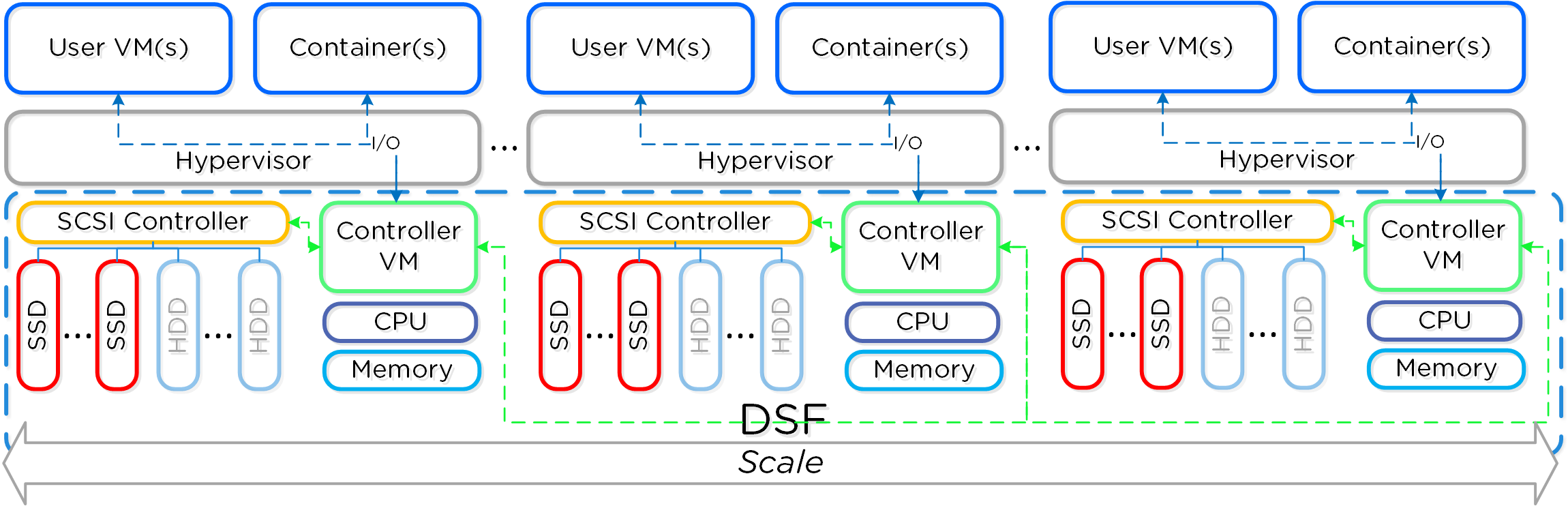
Все данные и метаданные так же распределяются по всему кластеру. Распределяя данные по всем узлам и устройствам хранения мы можем обеспечить действительно высокую производительность и уровень отказоуствойчивости.
Такой подход к хранению, в свою очередь, позволяет сервису Curator задействовать всю мощь кластера для обеспечения параллелизма всех операций. Например, параллелизм операций по защите данных, компрессии, обеспечения избыточного кодирования и дедупликации данных.
Ниже показано, как снижается процент нагрузки на узлы при масштабировании кластера:
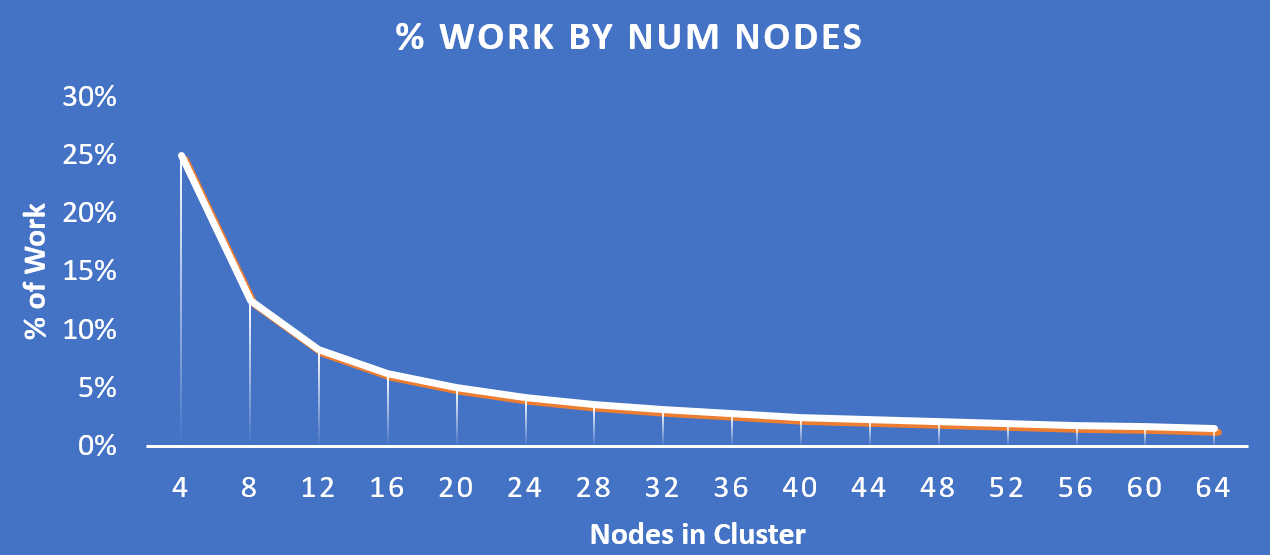
Важно: По мере роста кластера многие операции становятся более эффективными, так как нагрузка равномерно распределяется между всеми узлами.
Программно-определяемая платформа
Основные требования к программно-определяемой платформе:
- Должна обеспечиваться мобильность (между разным оборудованием и гипервизорами)
- Должна поддерживаться работа на оборудовании разных производителей
- Должна обеспечиваться высокая скорость разработки (новые возможности, исправление ошибок, обновления безопасности)
- Должна обеспечиваться параллелизация вычислений
Как говорилось ранее Nutanix представляет собой программное решение, поставляемое как программно-аппаратный комплекс. CVM один из самых важный компонентов платформы, где размещаются все логические компоненты ПО Nutanix. Данный компонент был разработан, чтобы стать частью архитектуры пригодной для неограниченного масштабирования. Одним из ключевых преимуществ программно-определяемого решения - независимость от аппаратной платформы. При таком подходе новые возможности могут быть предоставлены пользователю, независимо от оборудования, которое он использует.
А значит, не имея привязки к каким-то специфическим ASIC/FPGA решение Nutanix может разрабатывать и предоставлять новые возможности через простое обновление ПО. Т.е. какая-то функция, например дедупликация, становится возможной просто при установке актуальной версии ПО Nutanix. Такие сложные функции могут быть развернуты как на новое серверное оборудование, так и на устаревшее. Например, у вас есть инсталляция, где работает старая версия ПО Nutanix, на устаревающем оборудовании - серия 2400. Эта серия поставлялась без функции дедупликации данных, однако эта функция полезна и было бы хорошо ее заполучить. Тогда вы просто ставите на серию 2400 актуальное ПО и получаете ее. Вот и все - очень удобно и просто.
Так же легко вводятся и новые адаптеры для доступа к данным на DFS. В самом начале продукт поддерживал доступ только по iSCSI, но со временем были добавлены NFS и SMB. В будущем будут добавлены адаптеры под конкретные типы нагрузок или гипервизоры - например HDFS и так далее. И все эти возможности так же будут доступны через простое обновление ПО. Это ключевое отличие решения Nutanix от классических инфраструктурных решений, когда для получения новых возможностей нужно обновлять не только ПО, но и оборудование. С Nutanix все иначе. Как только функция попала в релиз - вы получаете к ней доступ на любом оборудовании, гипервизоре и так далее.
Ниже представлена схема размещения компонент в программно-определяемом решении:
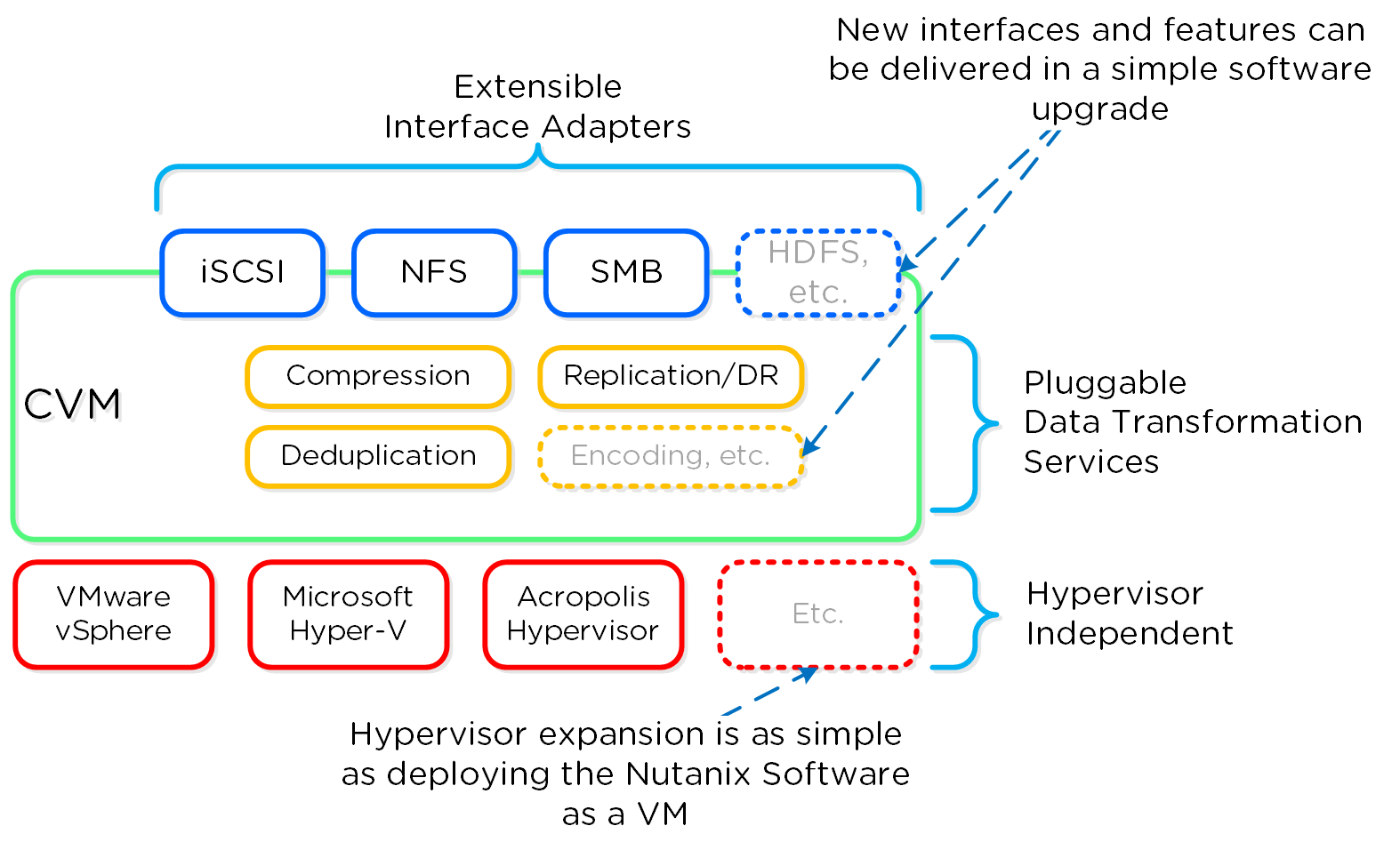
Компоненты кластера
Краткий рассказ на английском языке доступен по ссылке
Nutanix очень простой для развертывания и использования продукт. Таким он становится благодаря высокому уровню абстракции и огромному количеству интерфейсов для автоматизации и интеграции.
Ниже приведена схема со всеми программными компонентами ПО в рамках кластера Nutanix:
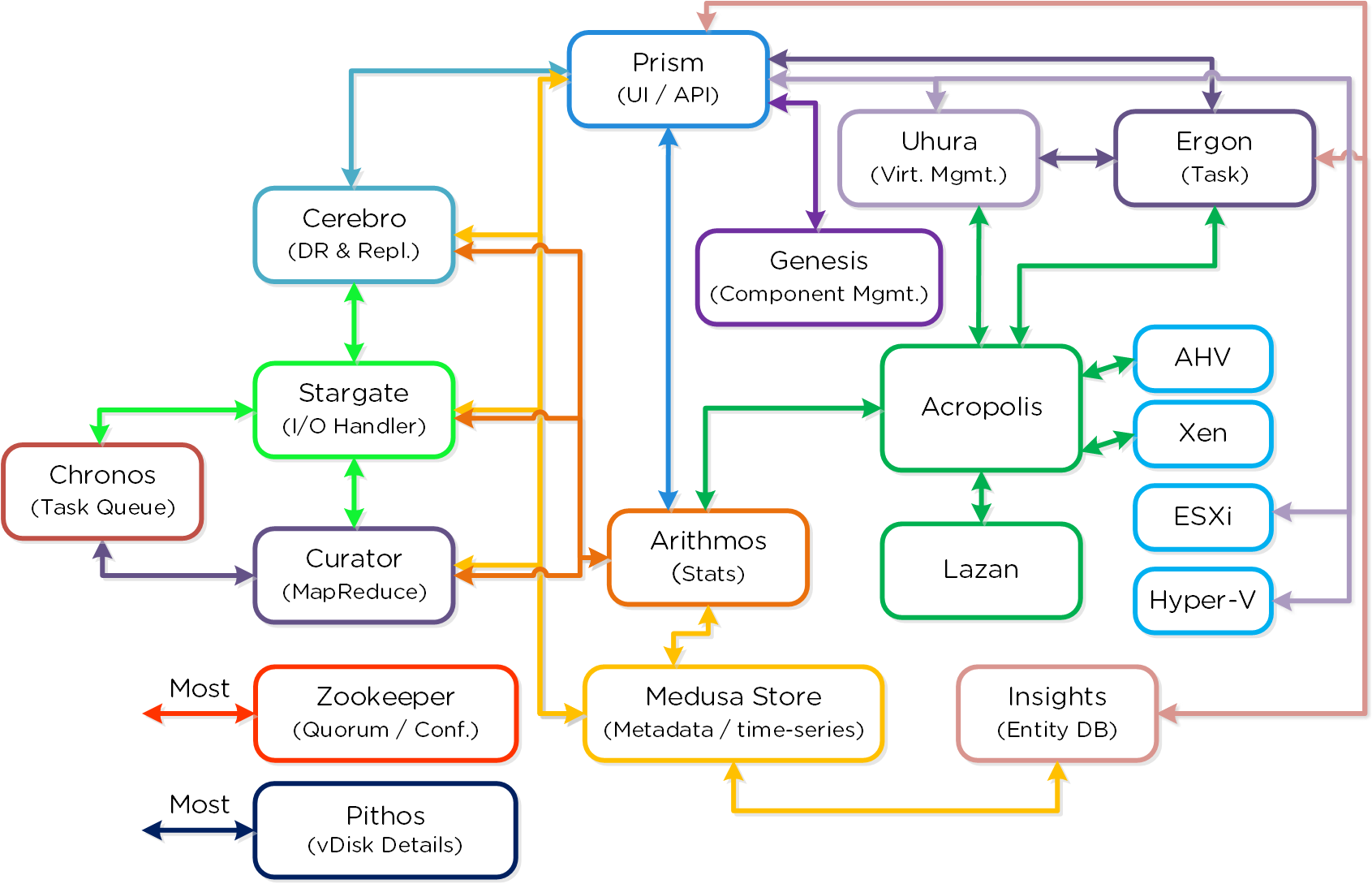
Cassandra
- Роль: Распределенное хранилище метаданных
- Описание: Данный компонент основан на открытом ПО Apache Cassandra, компонент отвечает за хранение и управление метаданными кластера. Данные распределяются на манер кольца между всеми узлами кластера Nutanix. Алгоритм Paxos используется для обеспечения консистентности данных Сервис запущен на всех узлах кластера, и доступен через интерфейс - Medusa.
Zookeeper
- Роль: Менеджер конфигурации кластера
- Описание: Zookeeper хранит все настройки кластера, включая адреса узлов, кластера, статусы сервисов и узлов. Сервис реализован на базе открытого ПО Apache Zookeeper. Это сервис запускается на трех узлах кластера, один из них получает роль лидера. Лидер обрабатывает все запросы и перенаправляет их к остальным двум узлам. Если Лидер не ответил - новый лидер будет выбран автоматически. Zookeeper доступен через интерфейс - Zeus.
Stargate
- Роль: Менеджер операций I/O
- Описание: Stargate отвечает за управление процессами работы с данными и операции I/O и является основным интерфейсом от гипервизора (через NFS, iSCSI, или SMB). Этот сервис запущен на всех узлах кластера, для локализации операций I/O.
Curator
- Роль: Менеджер распределения нагрузки MapReduce
- Описание: Curator отвечает за распределение нагрузки по узлам кластера, включая балансировку данных между дисками, про-активный сбор данных и так далее. Curator запускается на всех узлах и контролируется экземпляром с ролью Мастер который отвечает за перенаправление задач между экземплярами ПО. Сервис выполняет два типа сканирования - полное, выполняется каждые 6 часов и частичное - каждый час.
Prism
- Роль: Веб-интерфейс и API
- Описание: Prism компонент обеспечивающий настройку, мониторинг и управление кластером Nutanix. Данный компонент включает в себя Ncli, пользовательский веб-интерфейс HTML5, и REST API. Prism запускается на всех узлах кластера с выбором лидера, как и в случае с большинством других компонент платформы.
Genesis
- Роль: Менеджер кластерных сервисов
- Описание: Genesis - компонент работающий на всех узлах кластера и отвечающий за работу с остальными сервисами и их начальную конфигурацию. Genesis запускается независимо от кластера и может работать если кластер остановлен или вовсе не сконфигурирован. Единственное, что требуется для нормальной работы Genesis - запущенный сервис Zookeeper. Команды cluster_init и cluster_status полностью обрабатываются компонентом Genesis.
Chronos
- Роль: Планировщик заданий и задач
- Описание: Chronos отвечает за планирование заданий и задач приходящих от компонента Curator, а так же следит за их выполнением на узлах кластера. Chronos работает на всех узлах кластера и контролируется мастер-процессом Chronos Master который отвечает за распределение задач между экземплярами ПО.
Cerebro
- Роль: Менеджер репликации и катастрофоустойчивости
- Описание: Cerebro отвечает за выполнение репликации и функции DR распределенного хранилища данных. Сюда входит контроль за снимками, репликацией на удаленные кластеры, миграцию и восстановление. Cerebro работает на всех узлах кластера, т.е. все узлы отвечают за передачу данных между кластерами Nutanix.
Pithos
- Роль: Менеджер конфигурации объектов хранилища (vDisk)
- Описание: Pithos отвечает за объекты хранилища - они же vDisk. Запускается на всех узлах кластера и работает поверх сервиса Cassandra.
Сервисы Acropolis
Сервис Acropolis в режиме Slave запускается на каждой CVM, при этом осуществляется выбор роли Master которой отвечает за планирование задач, выполнение, функциональность IPAM и так далее. В случае проблем с текущим Master данная роль будет автоматически передана одному из текущих Slave.
Распределение ролей между режимами:
- Acropolis Master
- Планирование и выполнение задач
- Сбор и публикация статистики
- Управление сетью (для гипервизора)
- VNC прокси (для гипервизора)
- HA (для гипервизора)
- Acropolis Slave
- Сбор и публикация статистики
- VNC прокси (для гипервизора)
Ниже представлена схема взаимодействия ролей Master и Slave:
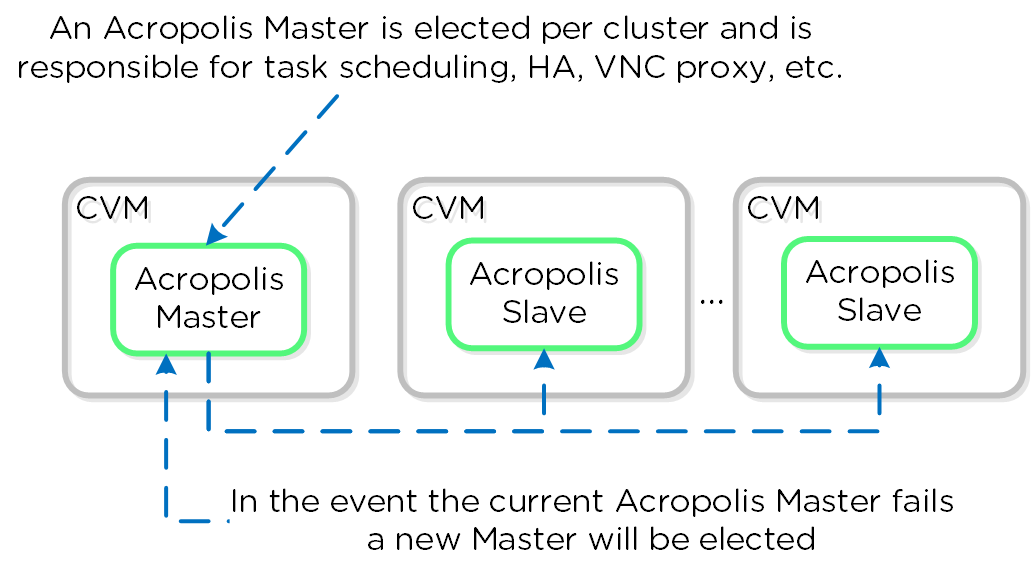
Динамический планировщик
Эффективное планирование ресурсов является критически важным для их эффективного использования. Динамический планировщик Acropolis расширяет традиционные функции планировщика по планированию вычислительных ресурсов для принятия решения о размещении ВМ. Он следит не только за вычислительными мощностями кластера, но и за нагрузкой на хранилище и диски, для более равномерного распределения нагрузки. Это гарантирует эффективное использование ресурсов и оптимальную производительность ВМ для конечных пользователей.
Планирование ресурсов делится на две области:
-
Начальное размещение
- Определение узлов, где ВМ будут размещены первоначальном запуске
-
Последующая оптимизация
- Перераспределение нагрузки между узлами на базе метрик поступающих от компонент
С момента своего появления планировщик Acropolis осуществлял планирование использования ресурсов при первоначальном запуске ВМ. В новой версии планировщика Asterix - планирование и оптимизация ресурсов осуществляется в реальном времени на базе метрик.
Ниже представлена верхнеуровневая архитектура планировщика:
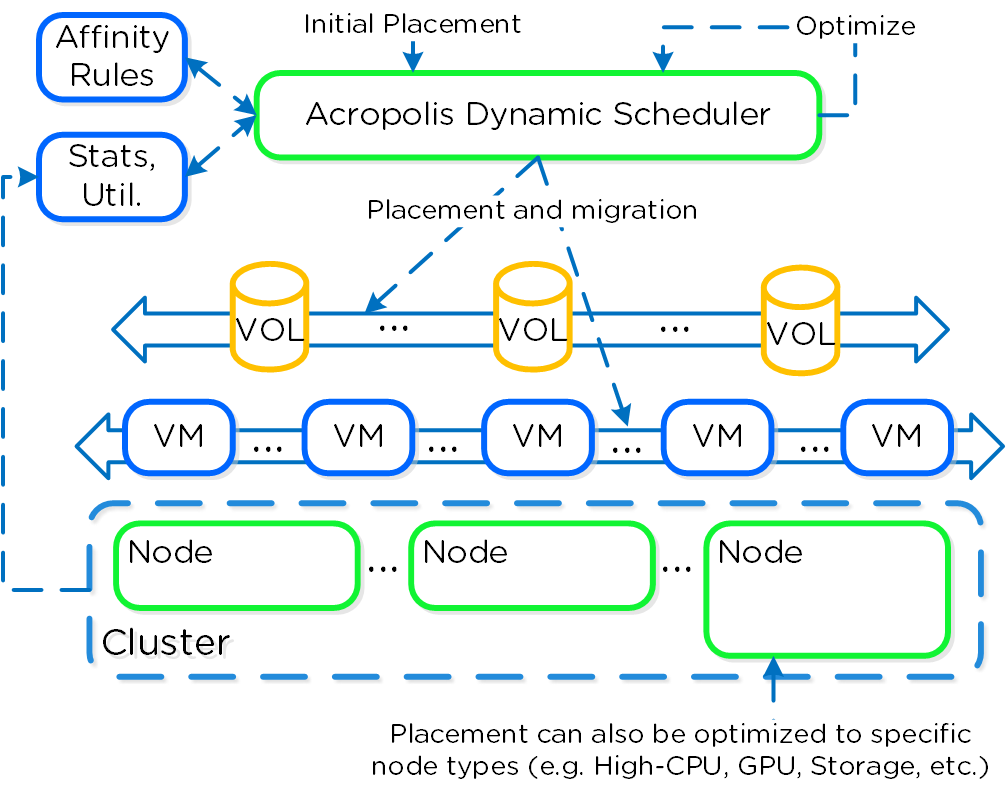
Динамический планировщик запускается каждые 15 минут, для оптимизации нагрузки и перераспределения ее по кластеру (Gflag: lazan_anomaly_detection_period_secs). Предполагаемый рост потребления ресурсов рассчитывается на основе исторических данных. На основе анализа данных осуществляется распределение нагрузки.
Примечание
Иной подход к оптимизации ресурсов
Если рассматривать существующие механизмы распределения нагрузки (VMware DRS, Microsoft PRO) становится понятно, что все они делают упор на перераспределении нагрузки по ресурсам кластера. Примечание: насколько агрессивно ПО выполняет балансировку определяет пользователь, посредством конфигурации ПО.
Например, если у вас три узла в кластере. Они нагружены неравномерно - 50%, 5%, %5. Типичное решение по балансировке будет пытаться добиться равномерного распределения нагрузки ~20% на узел. Но почему?
В действительности в первую очередь необходимо исключить конкуренцию за ресурсы, а не устранять перекос по нагрузке на узлы. Если конкуренции за ресурсы нет, то смысла в выполнении балансировки нет так же. Ведь выполнение бессмысленных операций по перемещению ВМ по кластеру так же требует определенного объема ОЗУ и процессорного времени.
Динамический балансировщик Acropolis будет выполнять перемещение ВМ именно в случае, если ожидается конкуренция за ресурсы. А не просто перемещая ВМ по кластеру. Примечание: Acropolis DSF работает не так, как классические механизмы распределения нагрузки. Его основная цель исключить конкуренцию за ресурсы, исключить горячие места и обеспечить высокую производительность всей платформе. Более подробно механизм работы DSF описан в секции 'Балансировка данных'.
При первом включении платформы динамический балансировщик сразу же приступает к первоначальной балансировке нагрузки.
Решения о размещении ВМ
Решение о размещении ВМ основывается на трех показателях:
-
Использование вычислительных мощностей
- Наше ПО постоянно отслеживает уровень использования вычислительных мощностей на каждом узле кластера. В случае, если ожидаемая нагрузка на CPU достигает порогового значения ПО выполняет перемещение ВМ с узла, для перераспределения нагрузки. (На текущий момент - 85% CPU | Gflag: lazan_host_cpu_usage_threshold_fraction). Важно отметить, что миграция будет выполняться только при конкуренции за ресурсы. Если же наблюдается перекос утилизации ресурсов между узлами, то ПО не производит никаких действий, для экономии ресурсов кластера.
-
Производительность хранилища
- В рамках платформы Nutanix мы управляем и вычислительными ресурсами и хранилищем. По этому балансировщик следит и за сервисом Stargate на каждом узле кластера. Если вдруг процент потребляемых сервисом ресурсов возрастает до порогового значения - ПО начинает перенос ВМ, сохраняя равномерность нагрузки на хранилище. (На текущий момент - 85% выделенного для сервиса Stargate | Gflag: lazan_stargate_cpu_usage_threshold_pct).
-
Правила размещения ВМ ([Anti-]Affinity)
- Правила размещения ВМ определяют где должны или не должны располагаться виртуальные машины. Например в некоторых случаях вы должны иметь возможность запускать какие-то ВМ на конкретных узлах, следуя политике лицензирования прикладного ПО. Или же вам нужно запустить какие-то ВМ на разных узлах, чтобы исключить возможность их одновременной потере при выходе из строя узла кластера. Планировщик учитывает эти настройки при перемещении ВМ по кластеру.
Планировщик будет учитывать все перечисленные выше показатели. Будет стараться не осуществлять лишних перемещений, если в этом нет необходимости.
Система будет оценивать эффективность каждого перемещения, анализировать полученный результат. Такая модель обучения ПО позволяет максимально оптимизировать все процессы и принимать решения о перераспределении нагрузки более взвешенно.
Диски
В этом разделе будут рассмотрены накопители информации используемые в платформе и то как и для чего они используются. Примечание: В качестве единицы для расчета использовались Гибибайты (GiB) вместо Гигабайтов (GB). Так же учитывались накладные расходы на файловую систему.
SSD диски
На SSD размещаются следующие ключевые компоненты:
- Служебные ВМ Nutanix (CVM)
- ПО Cassandra (хранилище метаданных)
- OpLog (постоянный буфер записи)
- Unified Cache (часть кэша, размещаемого на SSD)
- Хранилище данных
На рисунке ниже представлена схема использования SSD дисков:
Примечание: Начиная с версии 4.0.1 размер стал динамическим, это позволяет обеспечивать динамический рост для емкости для размещения данных. Приведенные значения предполагают полностью использованный OpLog. Пропорции графических элементов не соответствует объемам емкости. Оценку оставшейся емкости в GiB следует выполнять сверху вниз. Например, оставшаяся емкость для OpLog рассчитывается путем вычитания размера Nutanix Home и Cassandra из общей емкости отформатированного SSD.
OpLog распределяется между всеми SSD узла, начиная с версии 5.5 - до 8 штук на узел (Gflag: max_ssds_for_oplog). Если доступны NVMe - OpLog будет расположен на них, вместо SATA SSD.
Служебная директория с ПО Nutanix размещается на первых двух SSD, и зеркалируется для обеспечения отказоуствойчивости. Начиная с версии ПО 5.0 Cassandra распределяется по нескольким SSD, в рамках узла (на текущий момент - максимум 4). Под данные СУБД отводится по 15Гб на каждый SSD (может использовать и SSD Stargate, если объем метаданных растет). В системах с двумя SSD метаданные будут зеркалироваться между SSDs.
До версии 5.0 Cassandra размещалась на первом SSD по умолчанию, в случае проблемы с этим диском - CVM перезапускалась и хранилище Cassandra поднималось на втором SSD. В этом случае для метаданных резервировалось по 30GiB на первых двух устройствах.
Большинство моделей Nutanix поставляется с одним или двумя SSD, однако некоторые поставляются и с большим количеством. Например, если мы возьмем как пример 3060 или 6060 с двумя SSD по 400GB, то получим 100GiB для OpLog, 40GiB для Unified Cache, и ~440GiB для хранилища экстентов на узел.
HDD диски
Диски HDD используются гораздо проще::
- Хранилище Curator
- Хранилище данных (Постоянное хранилище)
Если взять для примера модель 3060 с четырьмя HDD по 1TB каждый, то получим 80GiB зарезервированных процессом Curator и ~3.4TiB для размещения пользовательских данных на каждый узел.
Примечание: эти данные актуальны для релиза 4.0.1 и выше, они могут отличаться в следующих версиях.
Безопасность и шифрование
Безопасность
Безопасность важнейший компонент платформы Nutanix, который мы постоянно держим в голове с самого первого дня. Жизненный цикл разработки подсистемы безопасности (SecDL) предполагает применение правил ИБ на каждом шагу разработки. Платформа имеет встроенную систему обеспечения информационной безопасности сразу с завода, и не требует пользовательской настройки или вмешательства.
Платформа Nutanix имеет следующие сертификаты / квалификацию:
-
Общие критерии (Common Criteria)
- Разрабатывались для того, чтобы решение могло продаваться на рынке государственных компаний и структур (в основном для обороны и разведки) по этому нужно лишь провести оценку по такому набору стандартов. Эти стандарты вырабатывались государственными органами Канады, Франции, Германии, Нидерландов, Англии и США.
-
Руководства по технической реализации ИБ (STIGs)
- Стандарты конфигурации для DOD IA и использующих IA систем и устройств. С 1998 года DISA FSO играет критическую роль повышения уровня ИБ для систем безопасности DoD (Департамента обороны). В свою очередь STIG содержит указание на блокировку ИС и ПО которые могут быть уязвимы для хакерских атак.
-
Стандарт FIPS 140-2
- Стандарт FIPS 140-2 стандарт ИБ по аккредитации модулей криптографии производимых частными организациями для государственных учреждений и регулируемых отраслей (здоровье и финансы) которые используются при агрегации, хранении, передаче или распространении конфиденциальной, но не секретной информации.
-
Соответствие TAA
- Закон о заключении торговых соглашений в соответствии с законом о торговле от 1974 года. Продукт для государственных органов и предприятий должен иметь страну происхождения США.
Автоматизация Управления Конфигурацией Безопасности (SCMA)
Подсистема безопасности работает на постоянной основе, с момента запуска кластера. Проверка выполняется без вмешательства пользователя, проверяя соответствие уровня ИБ для CVM/AHV на протяжении всего жизненного цикла. Такой механизм проверок постоянно проверяет все ли настройки соответствуют STIG и если находит несоответствие - исправляет ситуацию автоматически.
Примечание
Специальное выполнение SCMA
По умолчанию задачи SCMA запускаются по расписанию, однако могут быть запущены и по требованию пользователя. Для запуска SCMA необходимо выполнить следующие команды в рамках любой CVM:
# Запуск на одной CVM sudo salt-call state.highstate # Запуск на всех CVM allssh "sudo salt-call state.highstate"
Командная строка Nutanix, позволяет пользователям управлять конфигурацией платформы, а так же включать дополнительные параметры безопасности для усиления ИБ.
Настройки безопасности CVM
Для настройки политик SCMA были добавлены специальные консольные команды. Ниже перечислены основные команды:
Просмотр текущих настроек ИБ CVM
ncli cluster get-cvm-security-config
Упомянутая выше команда вернет текущие настройки кластера. Ниже представлен перечень настроек:
Enable Aide : false Enable Core : false Enable High Strength P... : false Enable Banner : false Enable SNMPv3 Only : false Schedule : DAILY
Установка сообщения отображаемого при входе на CVM
Данная команда включает или выключает сообщение со стандартными условиями входа в CVM.
ncli cluster edit-cvm-security-params enable-banner=[yes|no] #Default:no
Примечание
Настройка сообщения
Отображаемое при входе сообщение может быть изменено, путем выполнения следующих действий на любой из CVM:
-
Создаем резервную копию стандартного сообщения:
- sudo cp -a /srv/salt/security/KVM/sshd/DODbanner /srv/salt/security/KVM/sshd/DODbannerbak
- Используйте редактор vi для изменения сообщения:
- sudo vi /srv/salt/security/KVM/sshd/DODbanner
- Повторите шаги на всех CVM или скопируйте измененный файл посредством SCP
- Включите сообщения, используя команду указанную выше.
Настройка пароля для CVM
Данная команда принудительно увеличит требования к сложности пароля (minlen=15,difok=8,remember=24).
ncli cluster edit-cvm-security-params enable-high-strength-password=[yes|no] #Default:no
Настройка системы обнаружения вторжений (AIDE)
Данная команда включает или выключает подсистему обнаружения вторжений. Сервис будет запускаться еженедельно.
ncli cluster edit-cvm-security-params enable-aide=true=[yes|no] #Default:no
Принудительное включение SNMPv3
Данная команда включает принудительное использование SNMPv3 для отправки трапов.
ncli cluster edit-cvm-security-params enable-snmpv3-only=[true|false] #Default:false
Установка расписания для SCMA
Данная команда позволяет настроить периодичность выполнения запуска SCMA.
ncli cluster edit-cvm-security-params schedule=[HOURLY|DAILY|WEEKLY|MONTHLY] #Default:HOURLY
Настройки безопасности для Гипервизора
Для настройки политик SCMA были добавлены специальные консольные команды. Ниже перечислены основные команды:
Просмотр настроек безопасности для гипервизора
ncli cluster get-hypervisor-security-config
Данная команда вернет стандартный перечень настроек:
Enable Aide : false Enable Core : false Enable High Strength P... : false Enable Banner : false Schedule : DAILY
Настройка сообщения отображаемого при входе
Данная команда позволяет включить или выключить сообщение для отображения при входе в консоль гипервизора:
ncli cluster edit-hypervisor-security-params enable-banner=[yes|no] #Default:no
Настройка сложности пароля для гипервизора
Данная команда принудительно увеличит требования к сложности пароля (minlen=15,difok=8,remember=24).
ncli cluster edit-hypervisor-security-params enable-high-strength-password=[yes|no] #Default:no
Настройка системы обнаружения вторжений (AIDE)
Данная команда включает или выключает подсистему обнаружения вторжений. Сервис будет запускаться еженедельно.
ncli cluster edit-hypervisor-security-params enable-aide=true=[yes|no] #Default:no
Установка расписания для SCMA
Данная команда позволяет настроить периодичность выполнения запуска SCMA.
ncli cluster edit-hypervisor-security-params schedule=[HOURLY|DAILY|WEEKLY|MONTHLY] #Default:HOURLY
Блокировка Кластера
Блокировка Кластера - операция блокировки доступа к CVM посредством пароля. При этом доступ на основе ключа может быть разрешен.
Конфигурация данного режима доступна через меню Настройки интерфейса Prism:
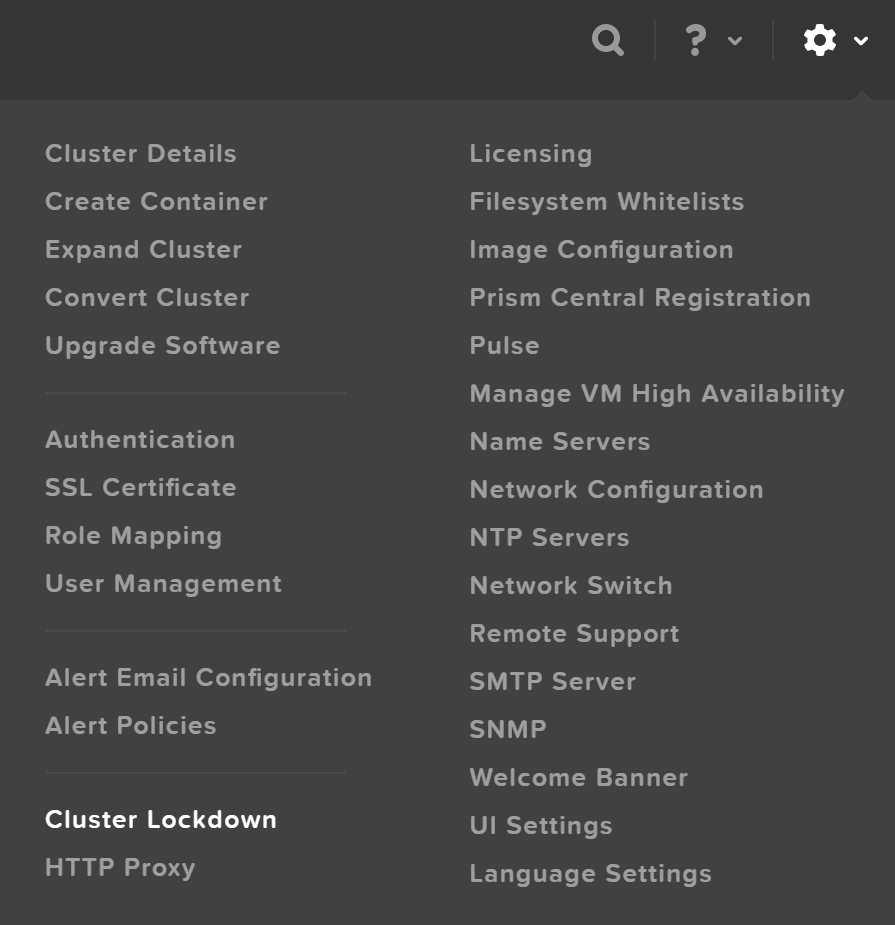
Данная станица отображает текущую конфигурацию блокировки и позволяет добавить/удалить SSH ключи:
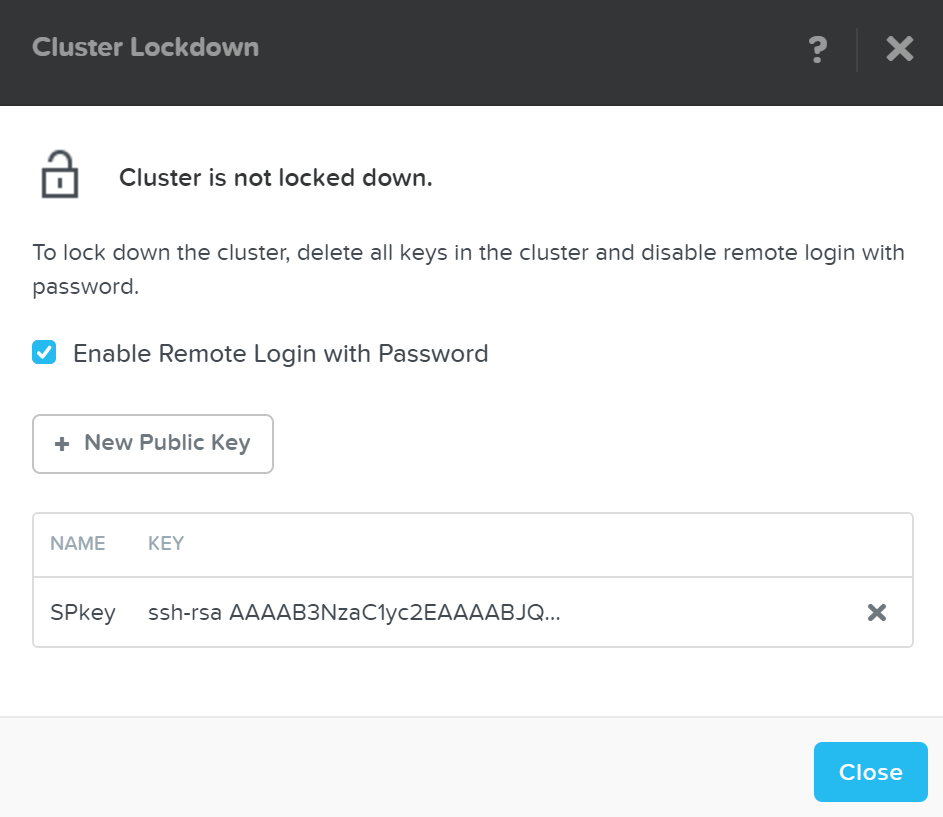
Для добавления нового ключа - нажмите кнопку 'New Public Key':
Примечание
Работа с ключами SSH
Для генерации ключа SSH выполните команду:
ssh-keygen -t rsa -b 2048
Эта команда сгенерирует пару ключей:
- id_rsa - приватный ключ
- id_rsa.pub - публичный ключ, который будет использоваться для доступа к кластеру
После добавления ключей и проверки доступа с их использованием вы можете отключить доступ по паролям. Для этого нужно снять галочку - 'Enable Remote Login with Password.' Появится всплывающее окно, где требуется подтвердить действие, нажав ОК.
Шифрование данных и управление ключами
Шифрование данных подразумевает, что возможность расшифровать данные есть только у авторизованных пользователей платформы. Это означает, что все другие пользователи доступ к данным получить не смогут.
Например, если у меня есть сообщение, которое я хочу отправить кому-то, и быть уверенным, что только они смогут его прочитать. Я могу зашифровать сообщение (открытый текст) с помощью шифра (ключа) и отправить им зашифрованное сообщение (зашифрованный текст). Если это сообщение украдено или перехвачено, злоумышленник может видеть только зашифрованный текст, который в основном бесполезен, не имея шифра для расшифровки сообщения. Как только доверенная сторона получила сообщение, они могут расшифровать сообщение, используя ключ, который мы им дали.
Вот несколько методов шифрования данных:
- Симметричное шифрование (шифрование с закрытым ключом):
- Один и тот же ключ используется для шифрования и расшифровки данных
- Пример: AES, PGP*, Blowfish, Twofish, etc.
- Асимметричное шифрование (шифрование с открытым ключом):
- Один ключ используется для шифрования (открытый ключ), другой-для дешифрования (закрытый ключ)
- Пример: RSA, PGP*, etc.
Примечание: PGP (или GPG) использует оба типа шифрования.
О шифровании данных говорят в двух основных контекстах:
- Онлайн шифрование: данные, передаваемые между двумя сторонами (например, передача данных по сети)
- Оффлайн шифрование: статические данные (например, данные хранимые на устройстве)
Начиная с версии 5.8 шифрование данных происходит в режиме оффлайн
В следующих разделах описывается, как Nutanix управляет шифрованием данных и параметрами управления ключами.
Шифрование данных
Nutanix предоставляет три варианта шифрования данных:
- Встроенная в ПО функциональность шифрования (FIPS-140-2 Level-1) *начиная с версии 5.5
- Использование дисков с самошифрованием (SED) (FIPS-140-2 Level-2)
- Шифрование на базе ПО и оборудования
Это шифрование настраивается на уровне кластера или контейнера и зависит от типа гипервизора:
- Шифрование на уровне кластера:
- AHV, ESXi, Hyper-V
- Шифрование на уровне контейнеров:
- ESXi, Hyper-V
Примечание: для инсталляций на базе шифрования SED фактически выполняется шифрование на уровне кластера, так как все устройства имеют встроенные механизмы шифрования.
Вы можете проверить текущий статус шифрования в разделе настроек 'Data-at-Rest Encryption'. Здесь же можно включить или выключить шифрование, если это применимо к текущей инсталляции.
В данном примере мы видим, что шифрование включено на уровне кластера:
В данном примере шифрование включено для определенных контейнеров:
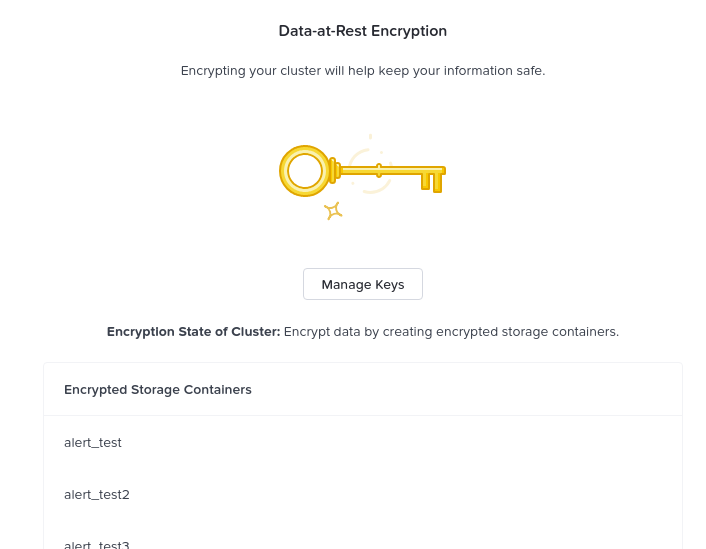
Вы можете включить или изменить конфигурацию, нажав на кнопку "edit configuration". Это вызовет меню для настройки KMS:
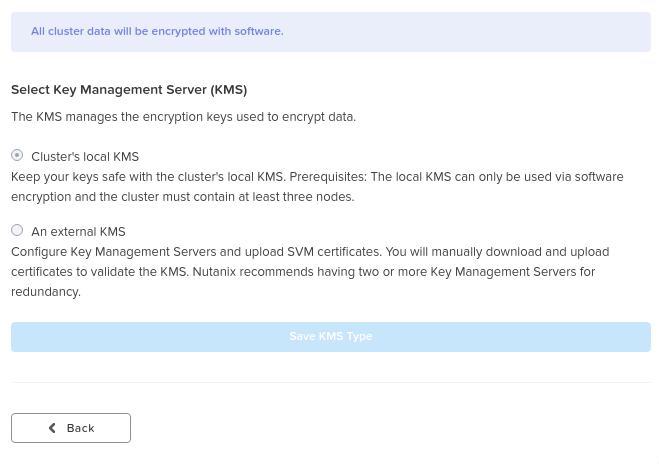
Для внешних KMS - меню проведет вас через процесс запроса CSR, который затем можно предоставить в центр сертификации для подписания.
Встроенные в ПО механизмы шифрования
ПО Nutanix обеспечивает оффлайн шифрование на базе AES-256. ПО может взаимодействовать с внешним KMS сервером совместимым с KMIP или TCG (Vormetric, SafeNet, и пр.) или же со встроенным KMS для версии ПО 5.8 или выше. Для шифрования / дешифрования система использует Intel AES-NI, чтобы свести к минимуму любое потенциальное влияние на производительность программного обеспечения.
При записи в OpLog или на диск данные шифруются до снятия контрольной суммы.
Шифрование - последняя операция с данными, которая выполняется до их записи на диск:
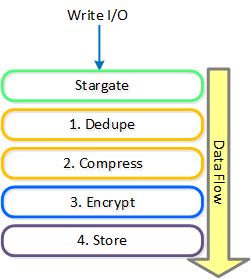
Примечание
Шифрование и эффективность данных
Так как мы шифруем данные после применения дедупликации или сжатия, мы гарантируем, что эффективность методов сохранения свободного пространства сохраняется на прежнем уровне. Проще говоря, коэффициенты дедупликации и сжатия будут одинаковыми для зашифрованных или незашифрованных данных.
Когда выполняется чтение данных - осуществляется чтение данных с диска, дешифрация и предоставление их пользователю или ПО. При этом мы гарантируем, что объем данных не будет увеличен. Учитывая, что мы используем Intel AES NI процедура дешифрации не влечет за собой роста нагрузки на платформу.
Шифрование на основе SED
На рисунке показана верхнеуровневая архитектура:
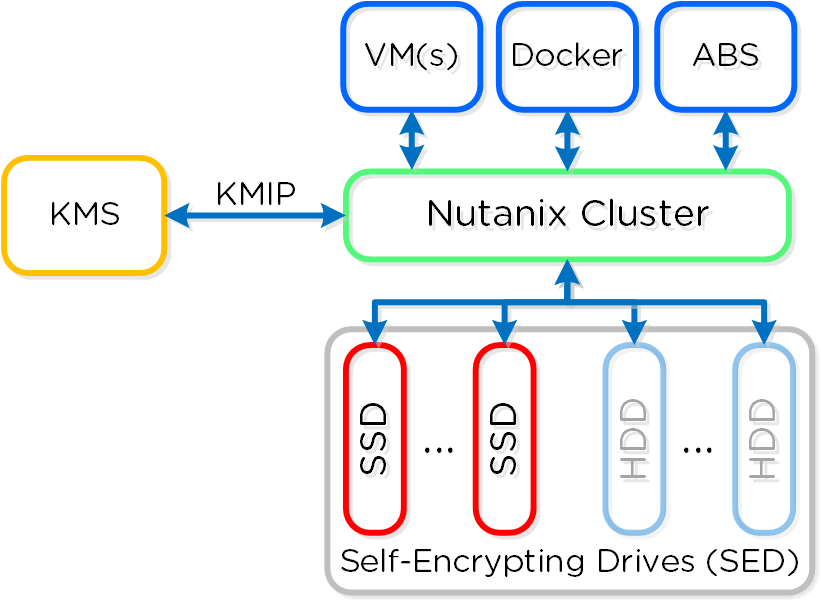
Шифрование на основе SED предполагает разделение устройств хранения на наборы данных, которые могут быть защищены или не защищены. В случае с Nutanix - загрузочный раздел и домашние директории ПО зашифрованы. Все устройства хранения данных зашифрованы при помощи больших ключей, согласно стандартам второго уровня.
Когда сервер запускается будет отправлен запрос ключей к серверу KMS для получения ключей, чтобы разблокировать доступ к дискам. Согласно политикам безопасности никаких ключи не кешируются на кластере. В случае холодной перезагрузки или спроса состояния сервера через IPMI узел должен обратиться к серверу KMS для получения доступа к дискам. Теплая перезагрузка не приведет к такому поведению.
Управление ключами (KMS)
Nutanix предоставляет встроенный сервис управления ключами (локальный менеджер ключей - LKM) и возможность их хранения (начиная с версии 5.8). Данный сервис является альтернативой выделенным, внешним системам управления ключами. Этот сервис был разработан, чтобы свести на нет необходимость в выделенном решении KMS и упростить среду, однако внешние KMS по-прежнему поддерживаются.
Как упоминалось в предыдущем разделе, управление ключами является очень важной частью любого решения для шифрования данных. Ключи используются на всех уровнях платформы, для предоставления максимально защищенное решение по управлению платформой.
В решении используются ключи трех типов:
- Ключ шифрования данных (DEK)
- Ключ, используемый для шифрования данных
- Ключ шифрования ключа (KEK)
- Ключ шифрования, используемый для шифрования DEK
- Мастер ключ шифрования (MEK)
- Ключ шифрования, используемый для шифрования KEK
- Применяется только при использовании локального менеджера ключей
На следующем рисунке показаны связи между различными ключами и параметрами KMS:
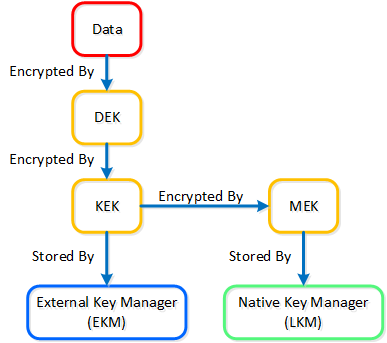
Служба локального диспетчера ключей (LKM) распределена между каждым узлом Nutanix и работает на каждом CVM. Сервис использует крипто-модуль FIPS 140-2, а управление ключами совершенно прозрачно для конечного пользователя.
При настройке шифрования данных, встроенный сервис управления ключами может быть выбран посредством выбора опции 'Cluster's local KMS':
Мастер-ключ распределен между всеми узлами в кластере с использованием алгоритма Shamir's Secret Sharing для обеспечения отказоуствойчивости и безопасности. Минимум ROUNDUP(N/2) узлов должно быть доступно для получения ключей, где N = количество узлов в кластере.
Примечание
Резервное копирование и ротация ключей
После включения шифрования рекомендуется создать резервную копию ключа (ключей) шифрования данных (DEK). Если резервная копия создана, она должна быть защищена надежным паролем и храниться в безопасном месте.
Система обеспечивает возможность ротации (rekey) как KEK, так и MAK. Он автоматически ротирует мастер-ключ (MEK) каждый год. Однако, это может быть выполнено и по запросу пользователя. В случае добавления/удаления узла мы также выполняем ротацию главного ключа.
Распределенное хранилище данных
Для гипервизора распределенное хранилище данных выглядит как единая система хранения данных, при этом все операции ввода-вывода обрабатываются локально для обеспечения максимальной производительности. Более подробную информацию о том, как узлы кластера образуют распределенную систему можно найти в следующем разделе.
Структура данных
Распределенное хранилище данных включает в себя следующие объекты:
Пул хранения (Storage Pool)
- Роль: Группа физических устройств
- Описание: Пул хранения - это группа физических устройств хранения данных, включая PCIe SSD, SSD и HDD. Пул хранения может охватывать несколько узлов Nutanix и расширяется по мере масштабирования кластера. В большинстве конфигураций используется только один пул хранения.
Контейнер (Container)
- Роль: Группа ВМ или файлов
- Описание: Контейнер - логический сегмент пула хранения, в рамках контейнера размещаются группы ВМ или файлов (vDisks). Некоторые настройки (например RF) определяются на уровне контейнера, при этом некоторые могут применяться непосредственно к файлам или ВМ. К емкости контейнера может быть предоставлен доступ посредством SMB/NFS.
Файл (vDisk)
- Роль: vDisk
- Описание: vDisk это файл, имеющий минимальный размер 512KB, например .vmdks или образ диска VM. vDisks представляет собой набор экстентов, которые в свою очередь формируют собой группы экстентов.
Примечание
Максимальный размер файла (vDisk)
Со стороны распределенного хранилища данных и ПО к файлам не предъявляется никаких искусственных ограничений. Начиная с версии 4.6 размер файла - это 64 битное целое число, которое определяет и хранит размер в байтах. Это означает, что теоретический максимальный размер файла - 2^63-1 или 9E18 (9 Экзабайт). Любые ограничения ниже этого значения будут связаны с ограничениями на стороне клиента, например максимальный размер vmdk определяемый ESXi.
На следующем рисунке показано, как они сопоставляются между хранилищем данных и гипервизором:
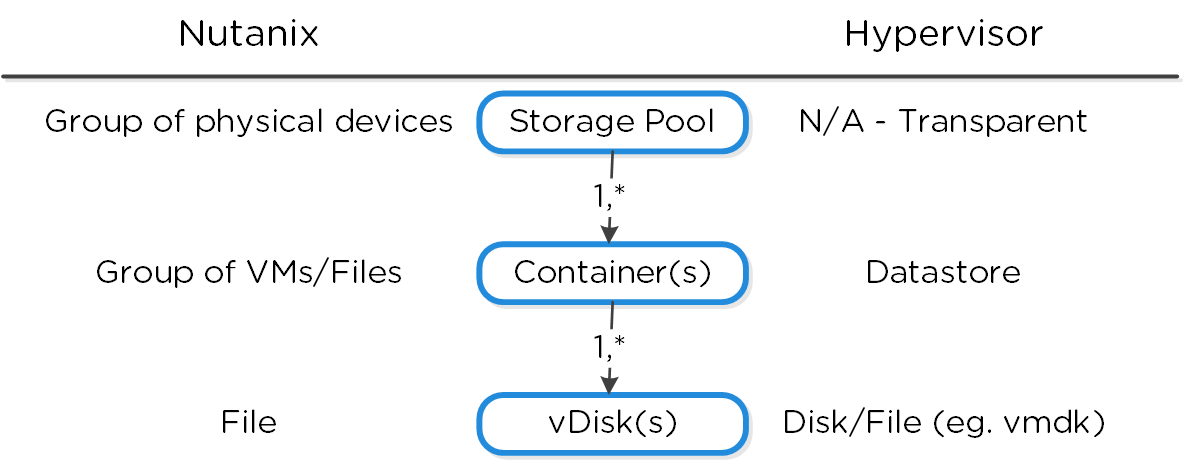
Экстент
- Роль: Логически непрерывные хранимые данные
- Описание: Экстент - это логический сегмент данных, размером 1MB который состоит из n последовательных блоков данных (N - зависит от размера блока ФС в гостевой ОС). Все изменения экстентов осуществляются на базе суб-экстентов (слайсов) для большей гранулярности операций и эффективности. Каждый суб-экстент может быть перемещен в кеш, в зависимости от объема считываемых/кешируемых данных.
Группа экстентов
- Роль: Физически непрерывные хранимые данные
- Описание: Группа экстентов - непрерывный набор данных размером 1MB или 4MB. Данные хранятся как файлы на физических дисках, которыми управляет CVM. Экстенты динамически распределяются по группам для обеспечения равномерного распределения данных по узлам и дискам, для улучшения производительности. Примечание: начиная с версии 4.0, группы могут иметь размер как 1MB, так и 4MB в зависимости от дедупликации.
На следующем рисунке показано, как эти структуры связаны между различными файловыми системами:
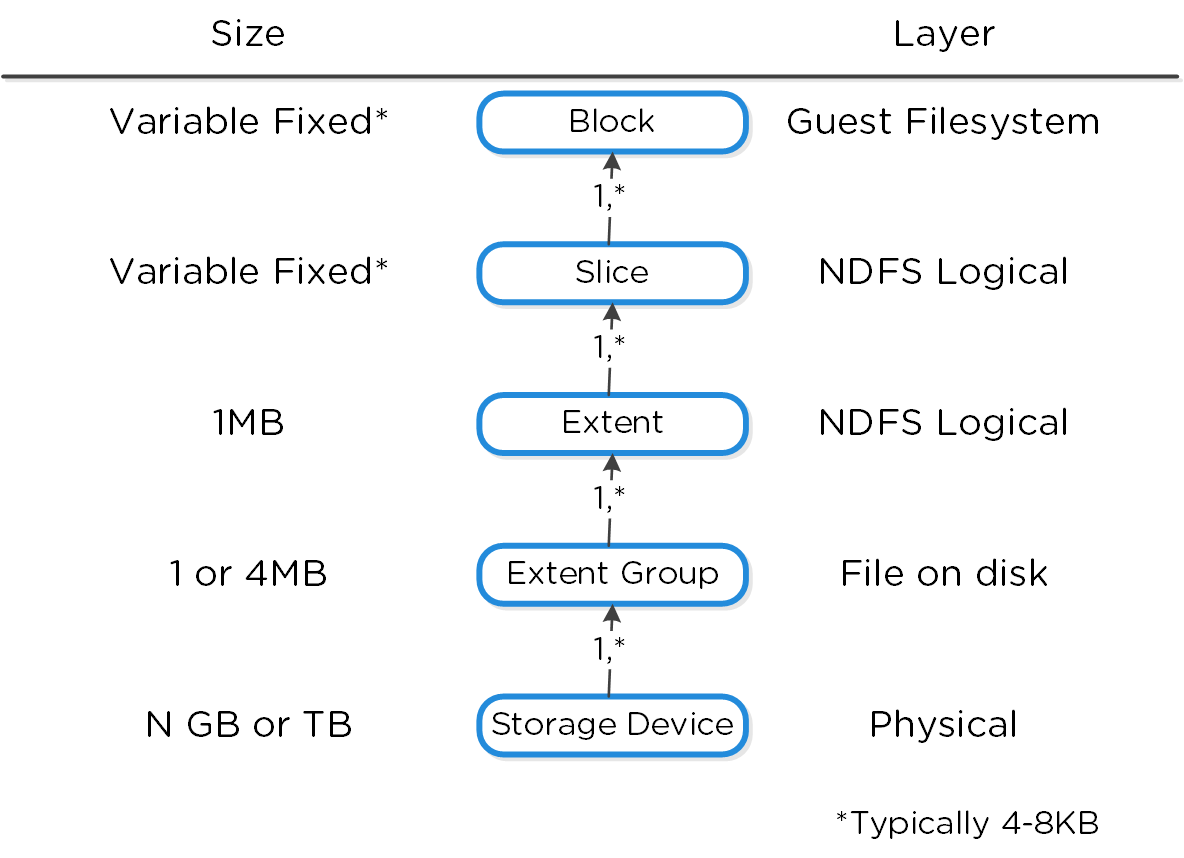
Вот еще одно графическое представление того, как эти элементы связаны:
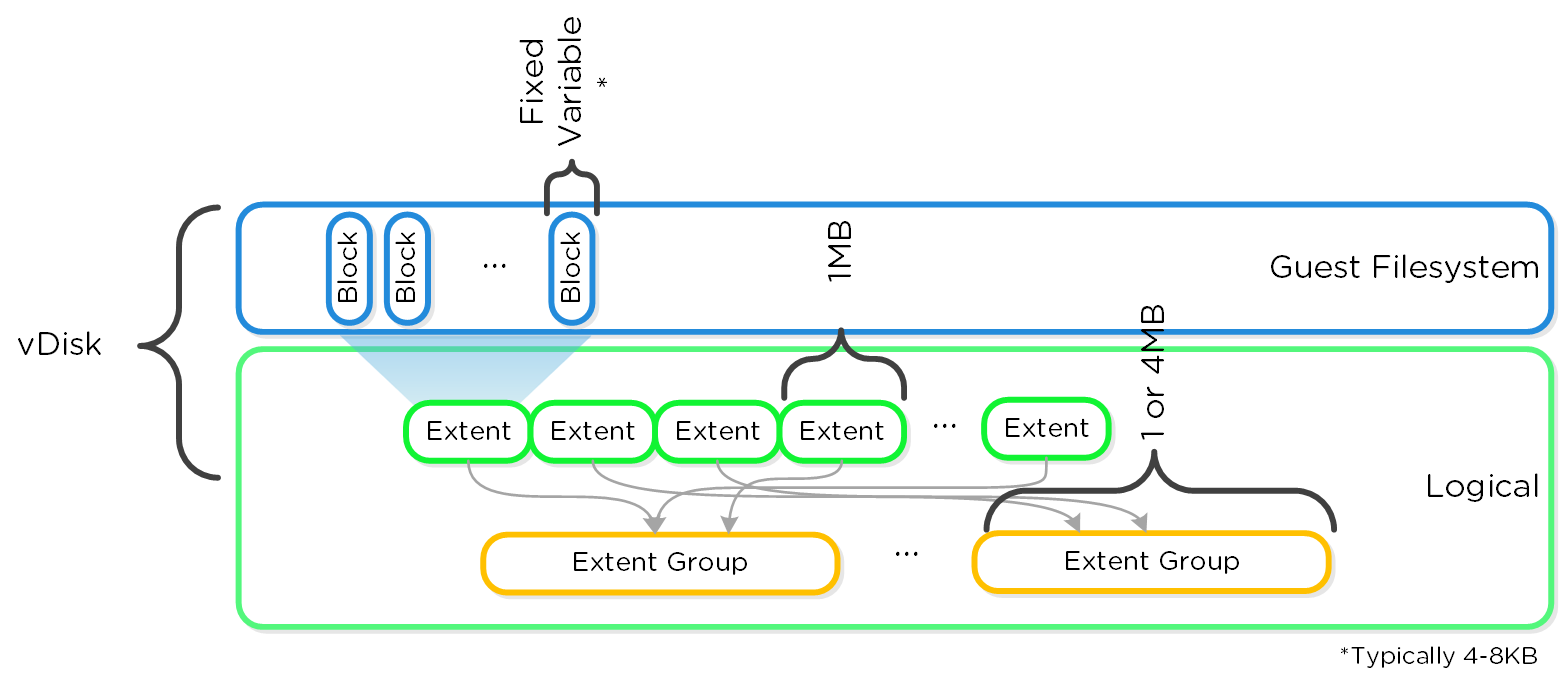
Процесс I/O и кэширование
Краткий рассказ на английском языке доступен по ссылке
Процесс I/O выглядит следующим образом:
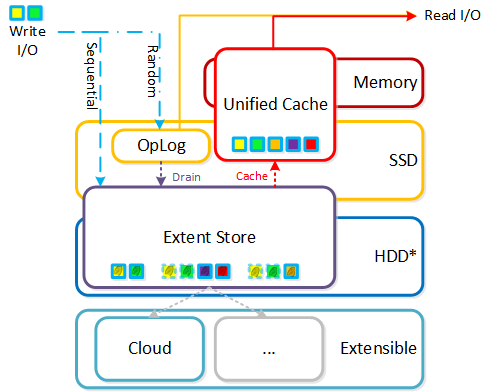
В конфигурации на базе SSD все данные будут располагаться на этих дисках, дополнительные операции по переносу данных между HDD и SSD выполняться не будут.
OpLog
- Роль: Постоянный буфер записи
- Описание: Буфер OpLog похож по своей сути на журнал файловой системы, и разработан как промежуточная область для обработки всплесков операций случайной записи. Такие операции обрабатываются, объединяются и затем последовательно записываются на распределенное хранилище данных (Extent Store). Данные OpLog постоянно синхронизируются между N служебных ВМ Nutanix (CVM), только после завершения записи и репликации для обеспечения высокой доступности данных.. Все экземпляры компонента OpLogs участвуют в процессе работы с данными, таким образом достигается равномерное распределение нагрузки между узлами кластера. OpLog всегда размещается на SSD для обеспечения максимальной производительности для операций I/O, особенно если они случайные. Таким образом, все устройства SSD участвуют в работе OpLog. В случае последовательный операций I/O - запись выполняется сразу в распределенное хранилище данных, минуя OpLog. Пока данные находятся в OpLog и не сброшены на РХД, все операции с ними будут выполнятся прямо в OpLog. Для контейнеров с активированными настройками дедупликации все операции записи будут дедуплицироваться на основе хешей, это позволит дедуплицировать их в универсальном кеше.
Примечание
Распределение OpLog
OpLog является общим ресурсом, он распределяется между всеми файлами, для обеспечения равных возможностей и обеспечения высокого уровня производительности. Для этого существует лимит который определяет максимальный размер OpLog на файл РХД. соответственно ВМ с несколькими дисками получат емкость OpLog для каждого из них.
Начиная с версии 4.6 данный лимит 6Gb, в более ранних версиях 2GB.
Данный Gflag отвечает за настройку лимита: vdisk_distributed_oplog_max_dirty_MB.
Хранилище экстентов
- Роль: Постоянное хранилище данных
- Описание: Хранилище экстентов - по своей сути является масштабируемым постоянным хранилищем данных, объединяет в себе уровни хранения SSD и HDD. Данные попадают в данное хранилище двумя путями: A) сбросом из OpLog или B) напрямую, при последовательных операциях, минуя OpLog. Nutanix динамически распределяет данные между SSD и HDD на основе типов шаблонов операций I/O.
Примечание
Последовательная запись
Операции записи определяются как последовательные когда более 1.5Мб данных находятся в очереди на запись в файл. Такие операции будут переданы напрямую в хранилище экстентов, минуя OpLog. Так как данные уже объединены в непрерывные цепочки и не требуют дополнительной обработки.
Это настраиваемый параметр - Gflag: vdisk_distributed_oplog_skip_min_outstanding_write_bytes.
Все остальные операции I/O, включая большие (например >64K) будут предварительно обрабатываться OpLog.
Единый Кэш (Unified Cache)
- Роль: Динамический кэш на чтение
- Описание: Единый кэш представляет собой кэш на чтение, к которому применяется механизм дедупликации. Он располагается в оперативной памяти CVM и на SSD устройствах. Работа с данными в кэш происходит с использованием алгоритма LRU (least recently used). Во время выполнения запроса на чтение, данные будут помещены в часть единого кэш, которая располагается в оперативной памяти. Любой следующий запрос инициализирует кеширование запрашиваемых данных в разделе кэш размещенном на SSD и оперативной памяти. Таким образом работа с данными происходит в два этапа, с применением LRU - первичный запрос к данным и повторный запрос данных. После выполнения первого и второго этапа - счетчик LRU будет сброшен и операция повторится снова, при повторном запросе данных.
Работа механизма единого кеша выглядит следующим образом:
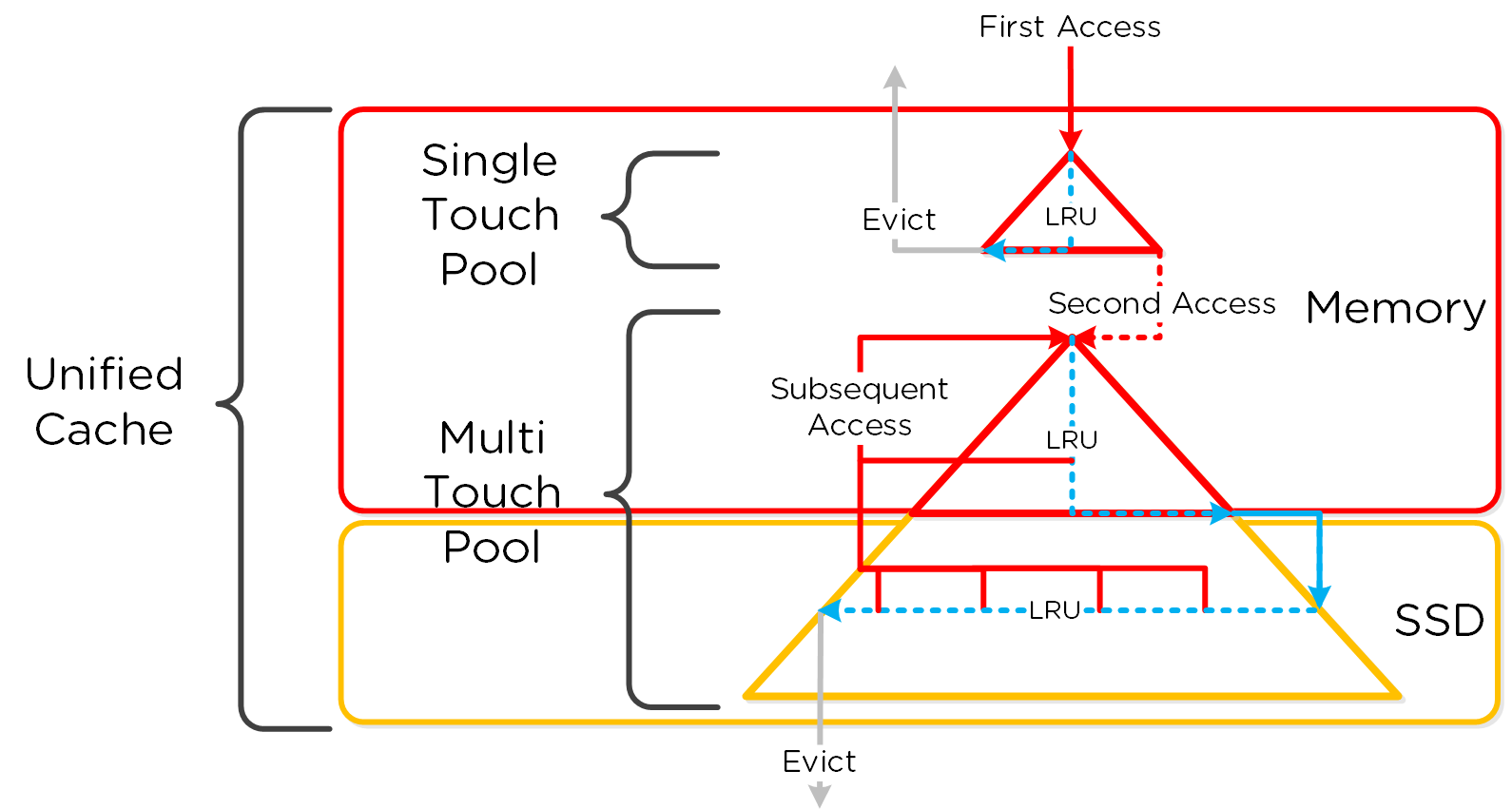
Примечание
Гранулярность кэширования и логика
Данные попадают в кэш с гранулярностью 4K, кеширование выполняется в реальном времени.
Каждая CVM имеет свой собственный локальный кэш, который используется при работе с дисками ВМ и файлами (vDisk). Каждый диск ВМ, при клонировании получает собственную карту блоков. Исходный диск помечается как неизменяемый. Так каждая ВМ имеет свою собственную закэшированную копию исходного образа.
В случае перезаписи данных - операция будет перенаправлена в новый экстент, согласно собственной карте блоков ВМ. Такой подход гарантирует целостность кэша и сохраняет его неповрежденным.
Кэш экстентов
- Роль: Кэш на чтение расположенных в ОЗУ
- Описание: Кэш экстентов - кэш на чтение целиком расположенный в ОЗУ служебных ВМ - CVM. Этот кэш хранит в себе данные для которых не применяется дедупликация и компрессия. С версии ПО 3.5 он отделен от универсального кэша (Unified Cache), однако с версии 4.5 был снова объединен с ним.
Масштабируемые метаданные
Краткий рассказ на английском языке доступен по ссылке
Метаданные являются ядром любой интеллектуальной платформы, особенно они важны для файловых систем и хранилищ данных. С точки зрения РХД, есть несколько моментов имеющих ключевое значение:
- Должен быть целостным на 100%, в каждый момент времени
- Должен соответствовать модели ACID
- Должен иметь неограниченную масштабируемость
- Должен не иметь узких мест при любом масштабировании (должен масштабироваться линейно)
Как упоминалось ранее - для хранения метаданных РХД использует хранилище типа ключ-значение, работающую в структуре "кольцо". Для обеспечения избыточности и высокой доступности данных используется фактор репликации, а метаданные размещаются по всем нечетным узлам кластера. В случае записи или обновления метаданных операция происходит на одном узле, а затем реплицируется по N узлов (N-зависит от размера кластера). Большинство узлов должны дать подтверждение, перед осуществлением записи, для реализации такого механизма используется алгоритм Paxos. Таким образом обеспечивается строгая согласованность всех данных и метаданных, хранящихся в рамках платформы.
На рисунке ниже отображена схема размещения метаданных в кластере из 4х узлов:
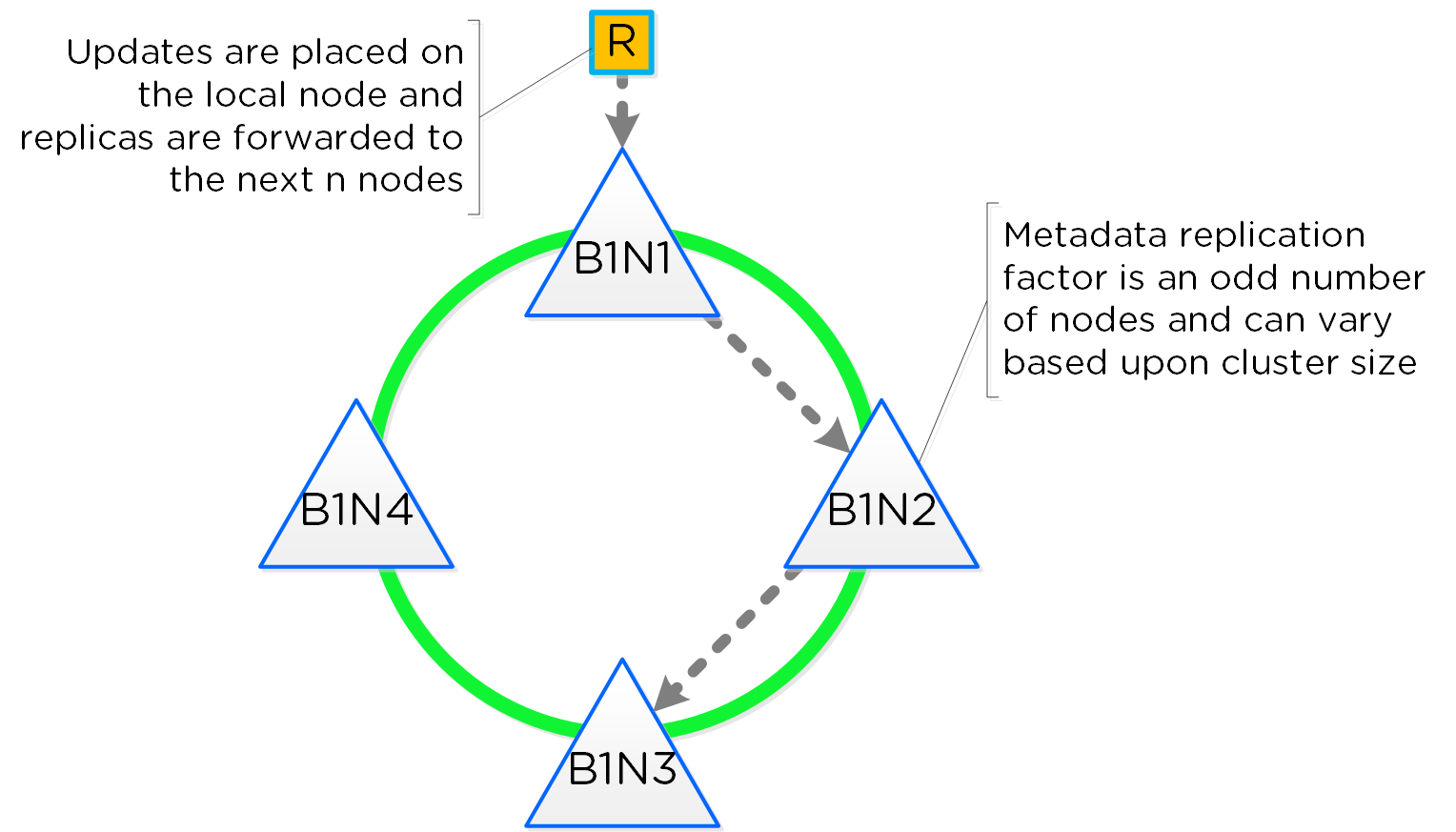
Производительность при масштабировании - еще один важный момент. В отличие от классической модели двух контроллеров (“master/slave”), каждый узел Nutanix отвечает за набор метаданных. Это исключает стандартные узкие места, распределяя нагрузку между узлами кластера. Консистентная схема хэширования используется для партиционирования ключей, для минимизации перераспределения ключей в случае изменения размеров кластера. Новые узлы встраиваются в кольцо существующего кластера между существующими участниками кластера, хранящих на себе метаданные. Кроме того, применяется механизм "block awareness" для повешения надежности.
Ниже на рисунке показан пример масштабирования "кольца"
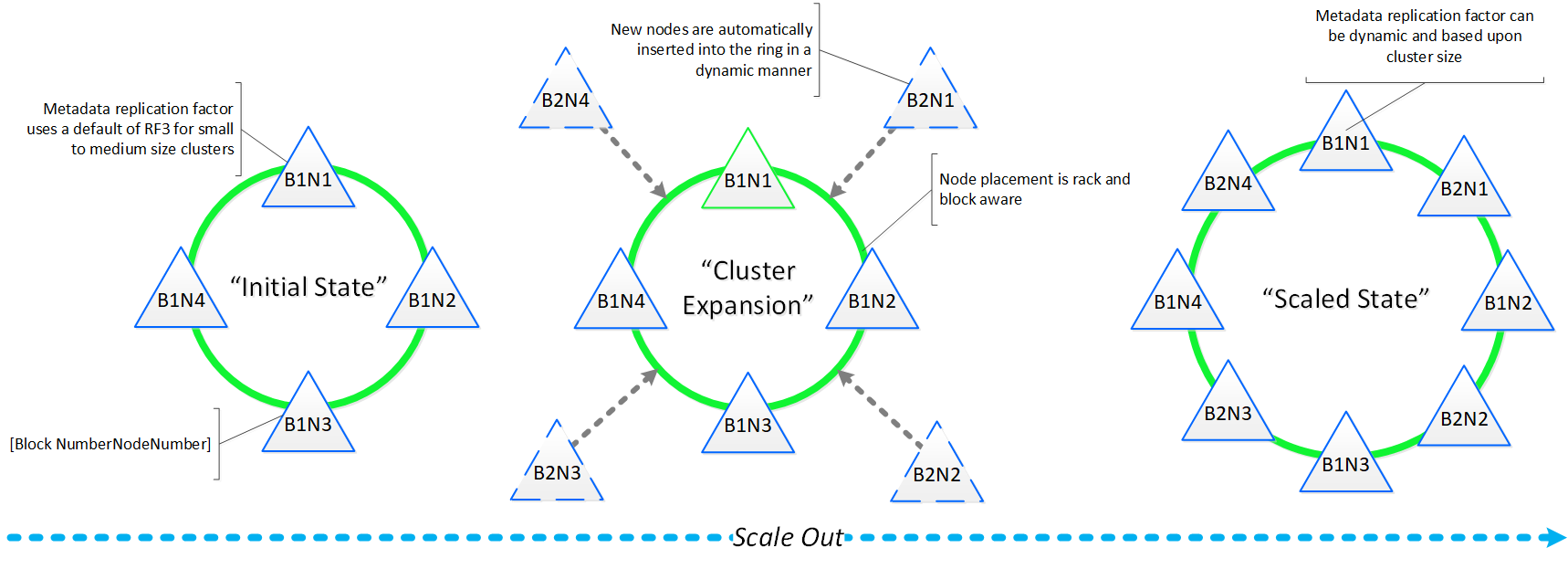
Защита данных
Краткий рассказ на английском языке доступен по ссылке
Платформа Nutanix использует фактор репликации (RF), и систему контрольных сумм,для обеспечения резервирования и доступности в случае отказа узлов или дисков. Как объяснялось выше, OpLog выступает в роли промежуточной области для обработки входящих операций записи на уровне SSD с низкой задержкой. После записи в локальный OpLog данные синхронно реплицируются на одну или две CVM в зависимости от фактора репликации, прежде чем вернуть подтверждение успешной записи (ack) на узел. Это позволяет быть уверенным, в том что данные существуют как минимум на двух или трех независимых узлах и находятся в безопасности. Примечание: Для фактора репликации RF3, минимальное количество узлов - 5, а значит метаданные будут иметь фактор репликации RF5.
Узлы OpLog выбираются каждый раз при записи следующего 1GB данных, в процессе участвуют все узлы кластера. Множество факторов влияет на выбор следующих узлов - время отклика, загруженность, утилизация ресурсов и так далее. Это исключает любую фрагментацию и гарантирует, что каждый CVM/OpLog может использоваться одновременно.
Обеспечение RF настраивается на уровень контейнера, через интерфейс Prism. Все узлы участвуют в репликации OpLog для исключения горячих точек и обеспечения линейной масштабируемости. Когда данные начинают записываться для них рассчитывается контрольная сумма и сохраняется как часть метаданных. Затем данные ассинхронно сбрасываются в хранилище экстентов где для них применяется политика резервирования. В случае выхода из строя узла или диска данные перераспределяются по оставшимся узлам/дискам, с учетом уровня RF. Каждый раз, когда происходит запрос к данным контрольная сумма пересчитывается, чтобы убедиться, что данные валидны. Если контрольные суммы на совпадают - будет осуществлено чтение из резервной копии, а невалидные данные перезаписаны.
Данные постоянно находятся под наблюдением системы, чтобы даже в случае отсутствия операций I/O следить за их целостностью. Служба Stargate будет постоянно проверять контрольные суммы групп экстентов, когда нет сильной нагрузки на РХД. Таким образом данные защищены для случаев выхода из строя секторов на накопителях и так далее.
Ниже представлена логическая схема этих процессов:
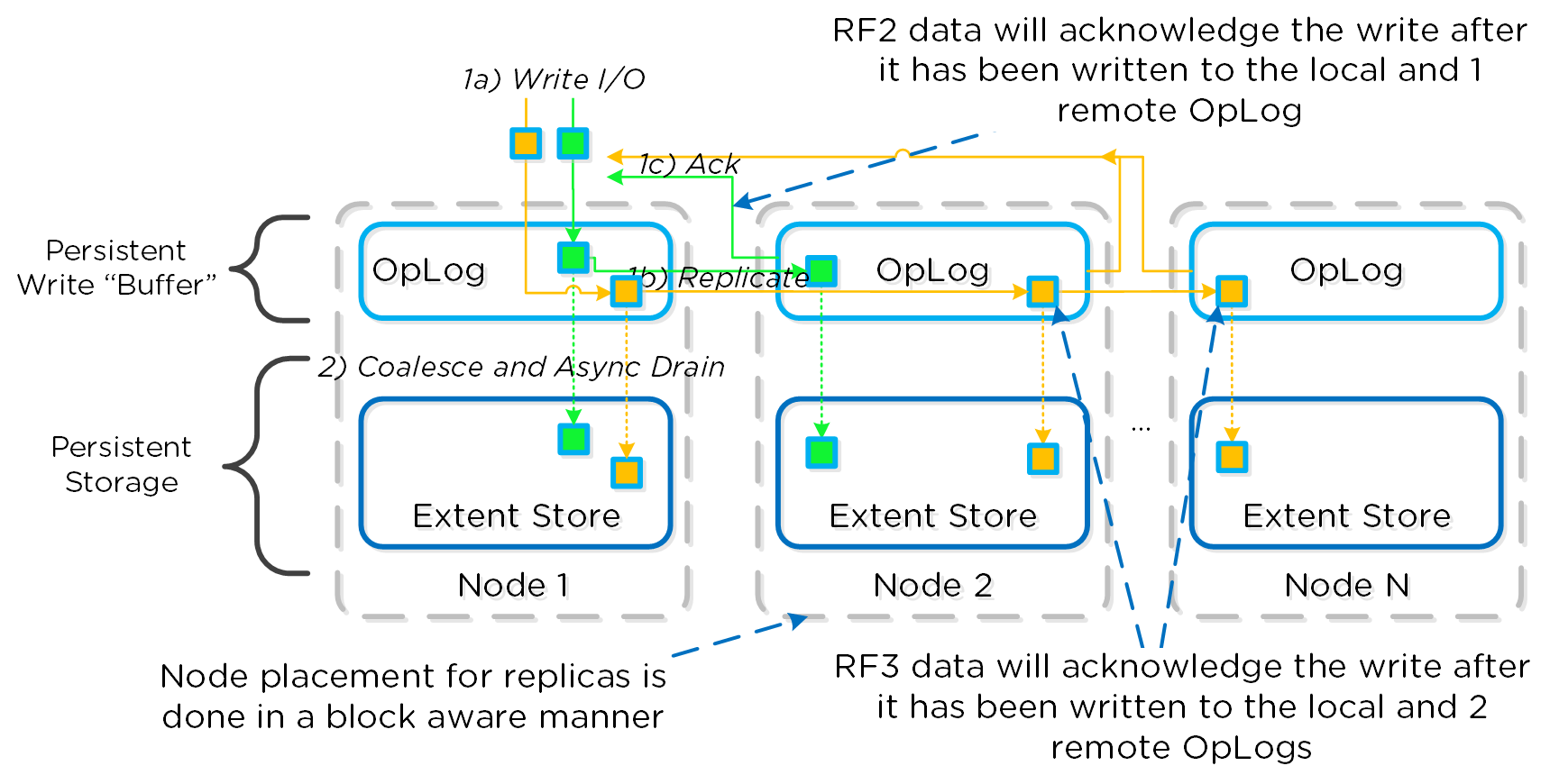
Домены доступности
Краткий рассказ на английском языке доступен по ссылке
Домены доступности (node/block/rack awareness) один из ключевых компонентов в распределенной системе, позволяющих правильно размешать данные относительно компонент, для обеспечения надежности. На текущий момент РХД может обеспечивать распределение между узлами и блоками, так чтобы выход из строя целого блока не приводил к потере данных. Для больших кластеров есть возможность обеспечить выход из строя одного серверного шкафа целиком. Блок - это серверное шасси, в котором может быть установлено один, два или четыре узла. Примечание: Кластер должен включать минимум 3 блока, для обеспечения выхода их строя одного блока.
Для обеспечения нормального функционирования домена доступности на базе блоков рекомендуется использовать однотипные блоки. Стандартные сценарии использования доменов доступности можно найти в нижней части этого раздела. Три блока требуется для того, чтобы собрать кворум. Это могут быть три блока 3450 по 4 узла каждый. При настройке домена доступности выход из строя блока целиком не влияет на работу ВМ и кластера. Примечание: Внутри блока только БП и вентиляторы являются общими компонентами.
Домены доступности сфокусированы на следующих компонентах:
- Данные (Диски ВМ)
- Метаданные (Cassandra)
- Конфигурация кластера (Zookeeper)
Данные
Данные на РХД постоянно дублируются и остаются доступными в случае выхода из строя или планового отключения узлов или блоков. Это актуально как для RF2 и RF3, так и для случае выхода из строя блоков, при использовании доменов доступности. Если сравнить домен доступности на уровне узлов и блоков, то мы увидим, что при отказе узла данные потерявшие резервную копию будут скопированы на оставшиеся узлы в кластере. Такая же модель работы распространяется и на уровень блоков - все данные будут копированы на оставшиеся блоки.
На схеме ниже изображен пример работы репликации для инсталляции из трех блоков:
В случае выхода из строя блока, данные потерявшие свою резервную копию будут дублированы на оставшихся узлах:
Домены доступности и отказоустойчивость
Рассмотрим некоторые стандартные сценарии и уровни отказоустойчивости:
| Обрабатываемые отказы | |||
|---|---|---|---|
| Количество блоков | Правила размещения | Кластер FT1 | Кластер FT2 |
| <3 | Узел | Один узел | Два узла |
| 3-5 | Узел+Блок | Один блок (до 4х узлов) |
Один блок (до 4х узлов) |
| 5+ | Узел+Блок | Один блок (до 4х узлов) |
Два блока (до 4х узлов) |
Начиная с версии ПО 4.5 включение доменов доступности на уровне блоков не является обязательным требованием. Это было сделано, чтобы ассиметричные кластеры не отключали эту функцию. Однако лучше иметь одинаковые блоки, для использования этой функции и избежания ситуации с неравномерно распределенными данными.
До версии ПО 4.5 следующие рекомендации должны выполняться:
- Если количество SSD или HDD отличаются между блоками > возможна организация домена доступности на базе: Узлов
- Если количество SSD и HDD отличаются между блоками < возможна организация домена доступности на базе: Блоков + Узлов
Максимальное расхождение рассчитывается по формуле: 100 / (RF+1)
- Например: 33% для RF2 или 25% для RF3
Метаданные
Как упомяналось в разделе Масштабируемые метаданные - Платформа использует серьезно модифицированную СУБД Cassandra для хранения метаданных и другой информации. Cassandra использует структуру "кольцо" и репликацирует метаданные по N узлов для обеспечения отказоустойчивости и доступности данных.
На следующем рисунке показан пример кольца Cassandra для кластера с 12 узлами:
Репликация между узлами Cassandra выполняется по часовой стрелке, по всему кольцу. Если настроены домены доступности на уровне блоков, то узлы кластера Cassandra размещаются так, чтобы находиться в разных блоках.
Ниже представлен пример размещения узлов кластера по блокам:
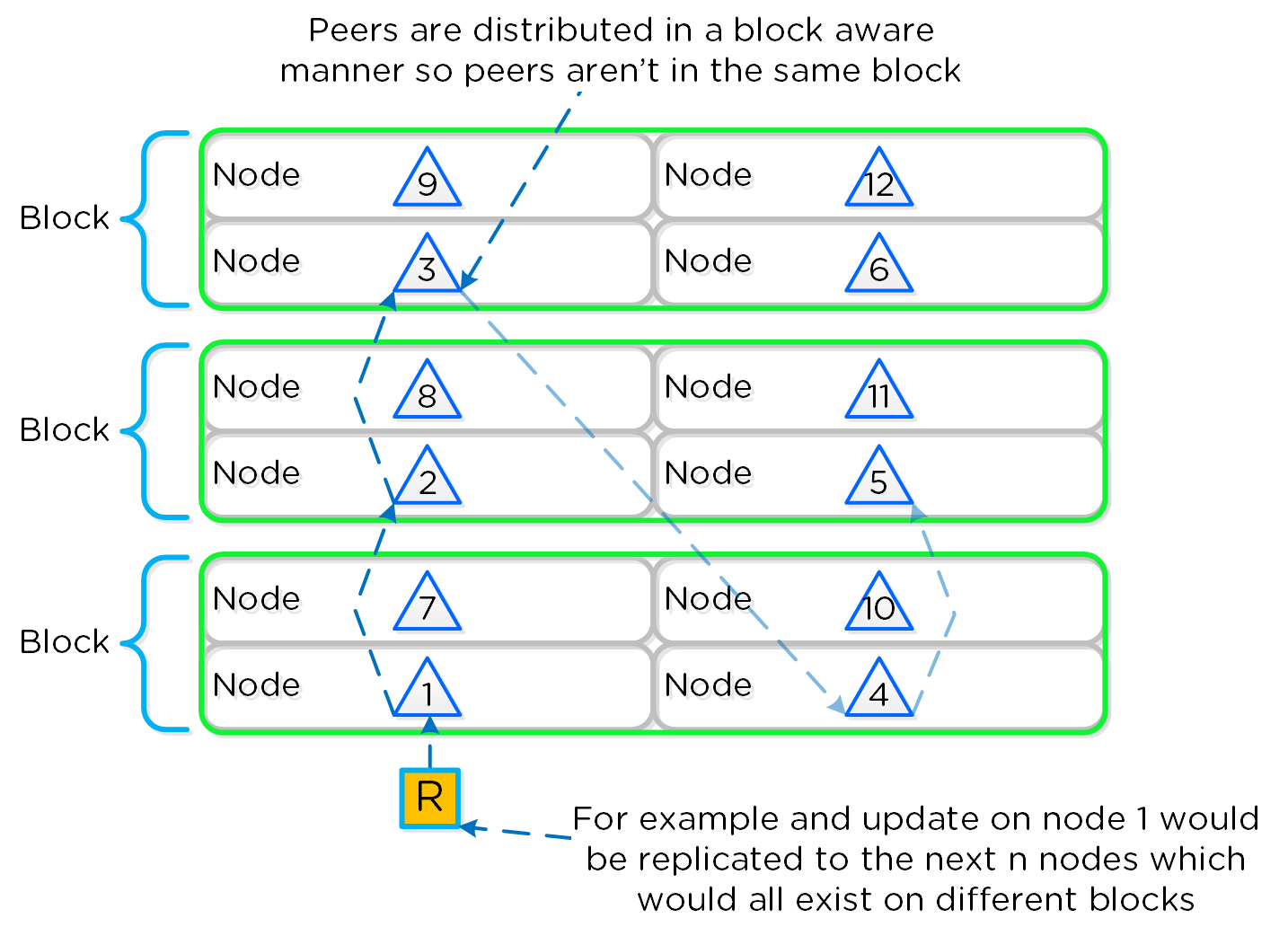
При отказе или выводе на обслуживание блока Nutanix как минимум две копии данных будут доступны.
Ниже отображена топология репликации между узлами, для объединения в кольцо:
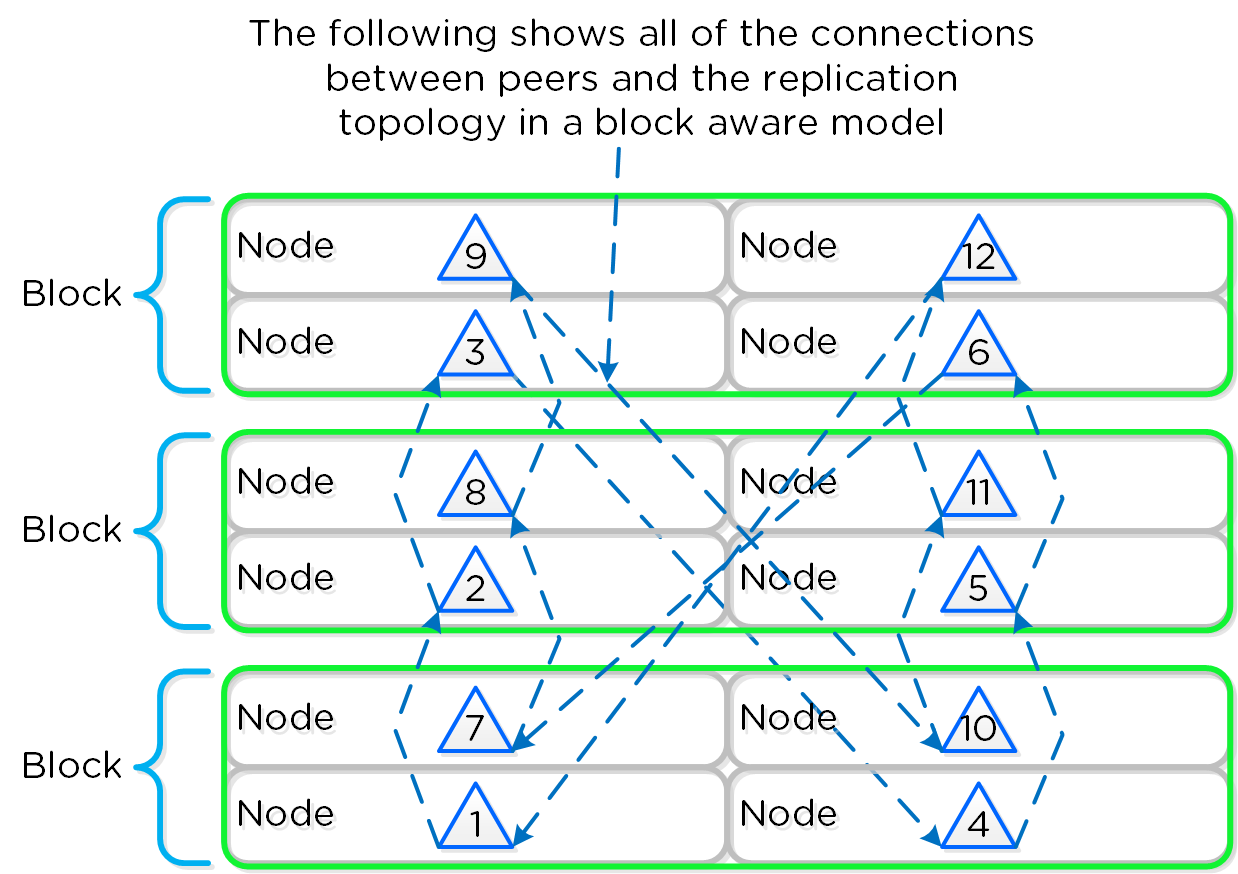
Примечание
Уровни доступности метаданных
Ниже рассмотрены сценарии и уровни доступности метаданных для них:
- Отказоустойчивость. Уровень 1 - FT1 (Данные RF2 / Метаданные RF3) будет доступен выход из строя одного блока если:
- >= 3 блока
- Где X - количество узлов в блоке, с максимальной плотностью. Тогда, оставшиеся блоки должны включать в себя не менее 2х узлов.
-
Например: 4 блока с 2,3,4,2 узлов на блок соответственно.
- В этой конфигурации максимальное количество узлов на блок - 4, это значит что в оставшихся трех блоках должно быть 2x4 (8) узлов. В этом случае реализовать отказ одного блока без влияния на кластер невозможно, так как в оставшихся узлах всего 7 узлов.
-
Например: 4 блока с 3,3,4,3 узлов на блок соответственно.
- В этой конфигурации максимальное количество узлов на блок - 4, это значит что в оставшихся трех блоках должно быть 2x4 (8) узлов. В этом случае реализовать конфигурацию позволяющую обеспечить отказ блока без влияния на кластер можно. Так как остается еще 9 узлов. Что выше нашего минимума.
-
Например: 4 блока с 2,3,4,2 узлов на блок соответственно.
- Отказоустойчивость. Упровень 2 - FT2 (Data RF3 / Metadata RF5) будет доступен выход из строя одного блока если:
- >= 5 блоков
- Где X - количество узлов в блоке, с максимальной плотностью. Тогда, оставшиеся блоки должны включать в себя не менее 4х узлов.
-
Например: 6 блоков с 2,3,4,2,3,3 узлов на блок соответственно.
- В этой конфигурации максимальное количество узлов на блок - 4, это значит что в оставшихся трех блоках должно быть 4x4 (16) узлов. В этом случае реализовать конфигурацию позволяющую обеспечить отказ блока без влияния на кластер невозможно. Так как остается только 13 узлов.
-
Например: 6 блоков с 2,4,4,4,4,4 узлов на блок соответственно.
- В этой конфигурации максимальное количество узлов на блок - 4, это значит что в оставшихся трех блоках должно быть 4x4 (16) узлов. В этом случае реализовать конфигурацию позволяющую обеспечить отказ блока без влияния на кластер можно. Так как остается еще 18 узлов. Что выше нашего минимума.
-
Например: 6 блоков с 2,3,4,2,3,3 узлов на блок соответственно.
Данные о конфигурации кластера
Nutanix использует Zookeeper для хранения основных настроек кластера. Эта роль так же является распределенной между узлами, и может функционировать при отказе блока целиком.
Ниже изображена пример схемы размещения 3 ролей Zookeeper для обеспечения отказа одного блока без влияния на кластер:
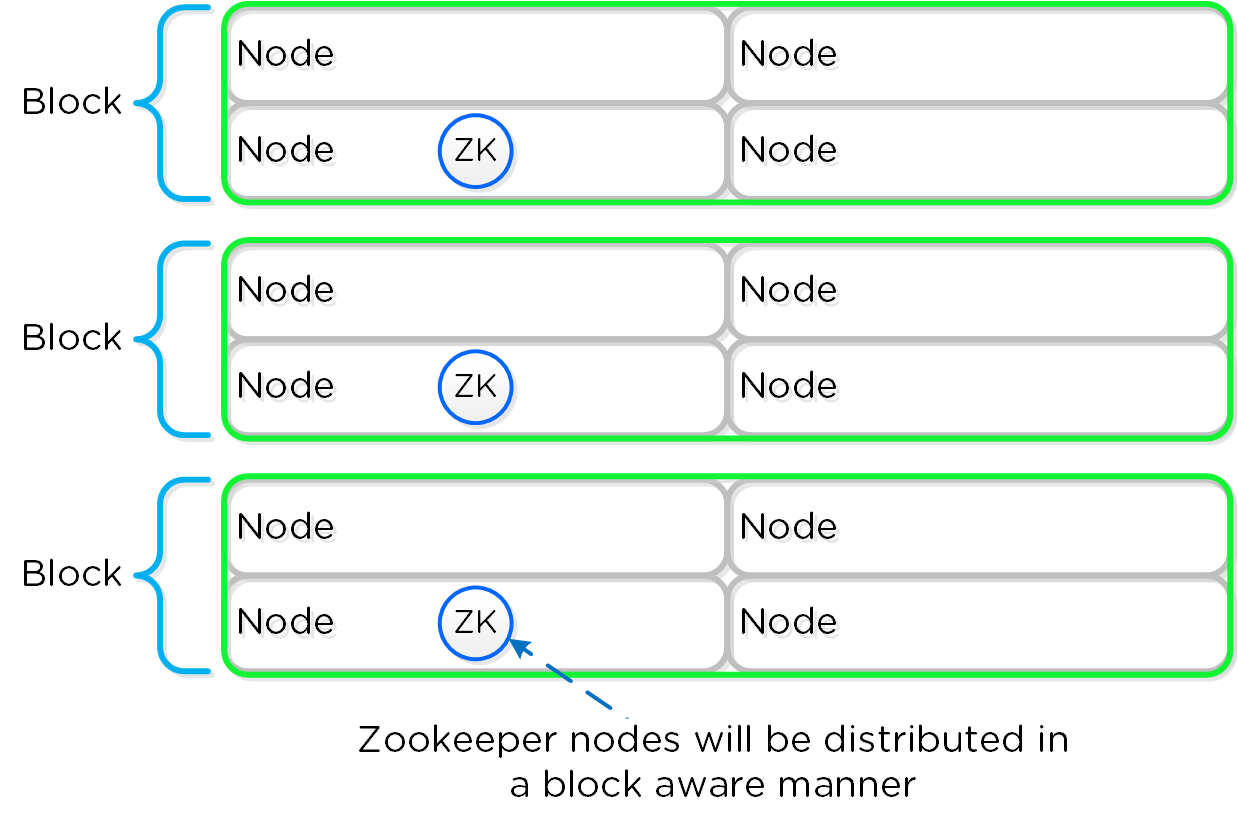
В случае отказа блока и потери одного из активных сервисов Zookeeper - сервис будет запущен на другом узле кластера, как показано ниже:
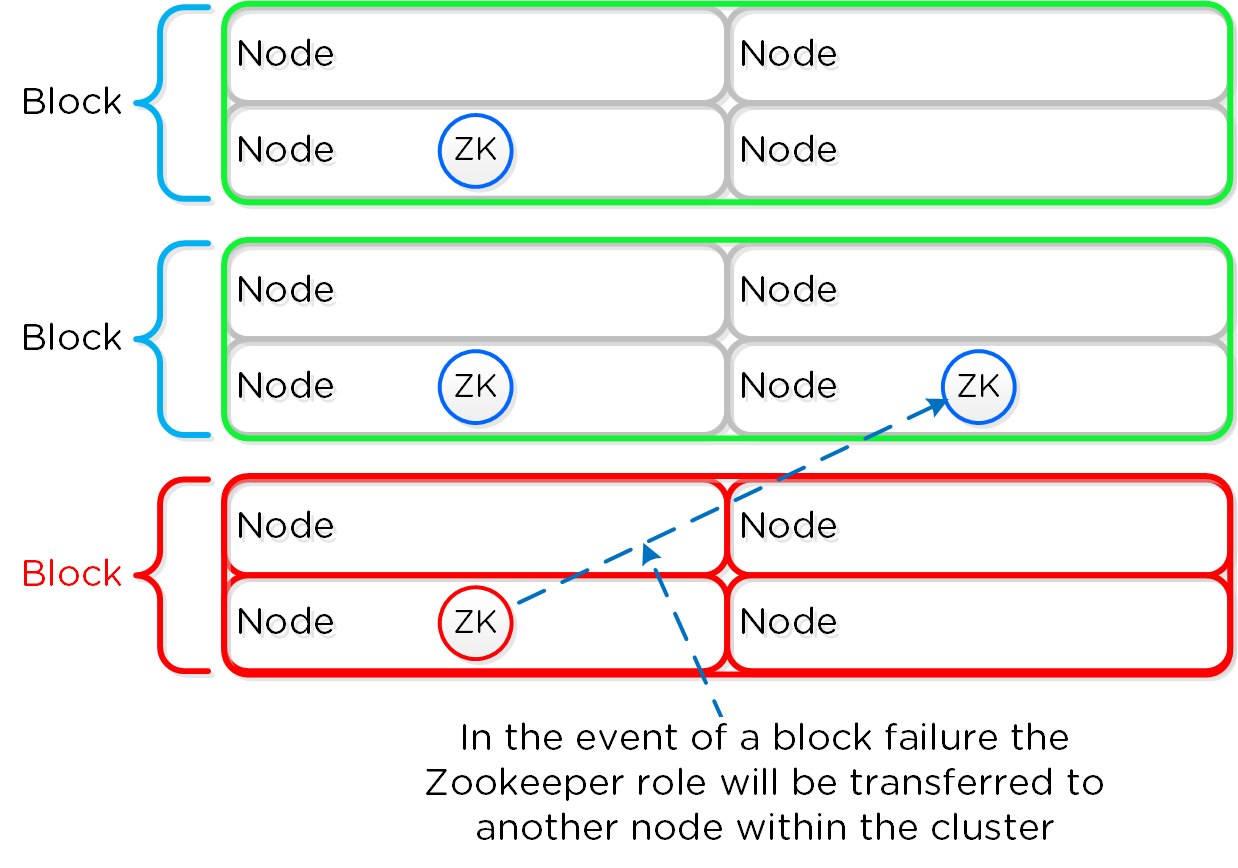
Когда блок будет снова доступен - сервис Zookeeper будет перемещен обратно, где он находился до отказа блока.
Примечание: До версии 4.5 такой перенос не выполнялся автоматически и требовал ручного вмешательства.
Отказоустойчивость путей данных
Краткий рассказ на английском языке доступен по ссылке
Надежность и отказоустойчивость является ключевыми частями концепции любого классического и распределенного хранилища данных.
Но в отличие от классических архитектур которые строятся вокруг отказоустойчивого оборудования, Nutanix считает, что оборудование в какой-то момент может сломаться. Учитывая это, система спроектирована так, чтобы решать проблемы с оборудование без прерывания сервисов.
Примечание: Мы не считаем, что все оборудование имеет низкое качество. Это всего лишь условный концепт. Команды компании, которые занимаются оборудованием и тестированием имеют высочайшую квалификацию.
Как упоминалась в предыдущих главах данные и метаданные защищаются путем дублирования, согласно уровню RF на базе глобального уровня FT. Начиная с версии ПО 5.0 поддерживаются FT1 и FT2, которые обеспечивают RF3 для метаданных и RF2 для данных, а так же RF5 для метаданных и RF3 для данных соответственно.
Более подробно защита метаданных описана в разделе "Масштабируемые метаданные". Механизмы защиты данных подробно описаны в разделе "Защита данных".
В нормальном состоянии данные по кластеру будут размещены следующим образом:
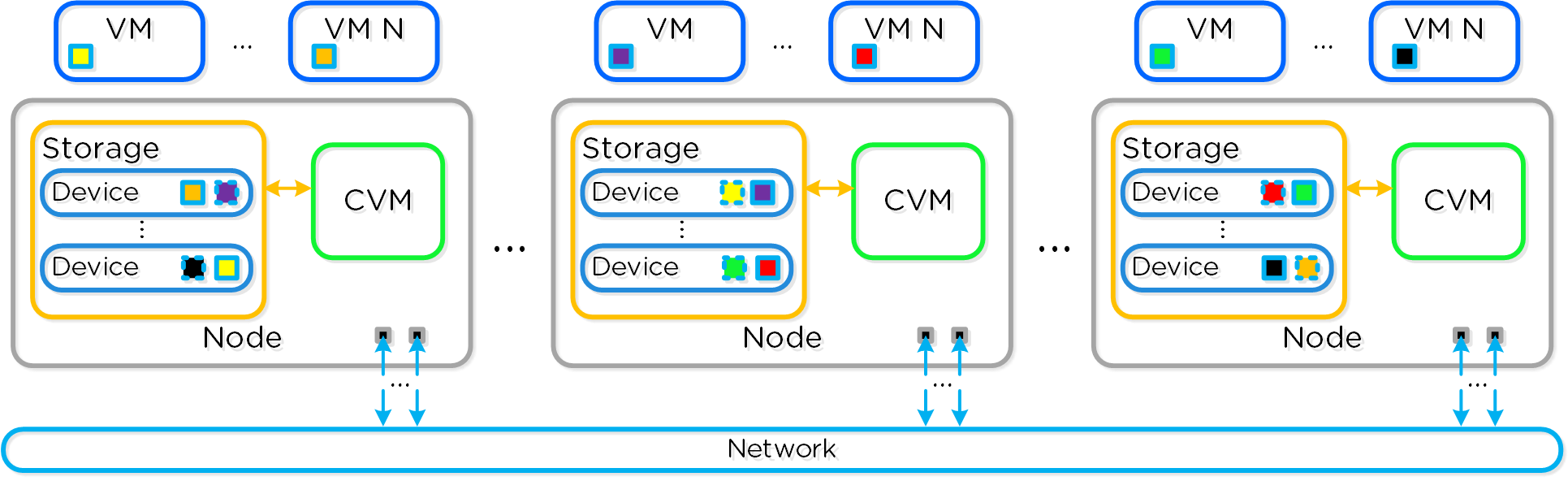
Как вы видите виртуальные машины и их диски имеют две или три копии на хранилище данных и распределены между узлами и физическими устройствами хранения.
Примечание
Распределение данных
Обеспечивая распределение метаданных и данных по всем узлам и дисковым устройствам, мы можем обеспечить максимально возможную производительность при обычном потоке данных их повторной защите.
По мере поступления данных в систему их первичные копии и копии реплик будут распределяться между локальными и всеми остальными удаленными узлами. Тем самым мы можем устранить любые потенциальные горячие точки (например, медленно узел или диск) и обеспечить согласованную производительность записи.
В случае сбоя диска или узла, когда данные должны быть повторно защищены - вся мощность кластера может быть использована для перераспределения данных. В этом случае сканирование метаданных (чтобы определить местоположение данных на отказавших устройствах и найти их реплики) будет равномерно распределено по всем CVM. Как только реплики данных найдены, все работоспособные CVM, их дисковые устройства (SSD+HDD) и сетевые интерфейсы узла будут одновременно использоваться, чтобы восстановить данные.
Например, если в кластере из 4х узлов, где вышел из строя один диск - каждая CVM возьмет на себя 25% нагрузки по сканированию метаданных и восстановления данных. Для кластера из 10 узлов - каждая CVM возьмет на себя 10% нагрузки по сканированию метаданных и восстановления данных. Для кластера из 50 узлов - каждая CVM возьмет на себя 2% нагрузки по сканированию метаданных и восстановления данных.
Ключевой момент: Используя встроенные механизмы распределения данных и нагрузки по кластеру мы можем быть уверенными, что мы предоставляем максимальную производительность и обеспечиваем минимальное время на восстановление данных. А так же все остальные процессы на кластере проистекают максимально оптимальными путями, за минимальные промежутки времени. Это касается EC, компрессии, дедупликации и так далее.
Классические решения, при этом имеют важнейшее отличие - при наличии двух контроллеров, либо дисков с зеркалированием - так или иначе при росте нагрузки страдает вся система. Нагрузка на любой парный компонент приводит к увеличению нагрузки на его пару, увеличивается время отклика, появляются узкие места.
Так же в классическом решении выход из строя одного из контроллеров, или любого парного устройства снижают отказоуствойчивость решения, а так часто влияют на его производительность. Так, в случае сбоя, система теряет в производительности и находится в крайне нестабильном состоянии до момента замены компонента, а иногда и после. Балансировка данных происходит медленнее, так как производительность ограничена оставшимся в паре компонентом. Кроме того есть риск потери данных, если возникнет какая-то еще неиспра вность.
Потенциальные уровни отказа
Распределенная Платформа Nutanix может обеспечивать отказоуствойчивость на базе компонент, сервисов, и служебных ВМ (CVM). Итак Платформа обслуживает отказы на следующих уровнях:
- Отказ диска
- "Отказ" CVM
- Отказ узла
Примечание
Когда начинается перераспределение данных?
В случае незапланированного сбоя восстановление данных начинается незамедлительно. В некоторых случаях мы будем пытаться выключать компоненты автоматически, если они работают некорректно.
В отличие от некоторых других поставщиков решений, которые ждут 60 минут до того как начать процесс репликации данных и держат всего одну копию в течении этого времени, мы не готовы идти на риск потери данных даже если мы увеличим использование объема хранилища.
Мы можем восстанавливать данные сразу потому, что: 1. гранулярность наших метаданных позволяет это делать, 2. платформа сразу же, динамически, определяет узлы для RF (в случае сбоя любого компонента мы продолжаем писать данные согласно уровню RF), 3. мы определяем восстановление сбойных компонент и после их восстановления проверяем актуальность данных, если они актуальны - мы не будем восстанавливать их повторно. В таких случаях данные могут бы "пере-реплицированы", и Curator найдет лишние копии и удалит их.
Отказ диска
Отказом диска считается ситуация, когда диск был удален, на нем растет количество ошибок, или же он перестал отвечать или генерирует ошибки I/O. Когда Stargate идентифицирует ошибки I/O или отсутствие ответов от дисков в определенный промежуток времени - диск помечается как отключенный. После того, как произошло одно из перечисленных событий система запустит S.M.A.R.T. и проверит статус устройства. Если все тесты будут выполнены, диск будет помечен как работоспособный. В обратном случае его статус не изменится. Если Stargate пометил диск как отключенный несколько раз (сейчас это три раза в час), Hades не будет восстанавливать статус диска, даже если проверка S.M.A.R.T. выполнена успешно.
Влияние на ВМ:
- Событие HA: Нет
- Прерывание I/O: Нет
- Задержки: Без влияния
В случае сбоя диска немедленно будет выполнено сканирование сервисом Curator. Он проверит метаданные и постарается найти копии данных вышедшего из строя диска на других узлах и дисках кластера.
Как только они будут найдены - запуститься процесс репликации этих копий, для восстановления нужного количества согласно RF.
В это время будут запущены тесты Drive Self Test (DST) для наблюдения за ошибками в журналах SMART.
Ниже изображена схема, на которой показан отказ диска и повторная репликация данных:
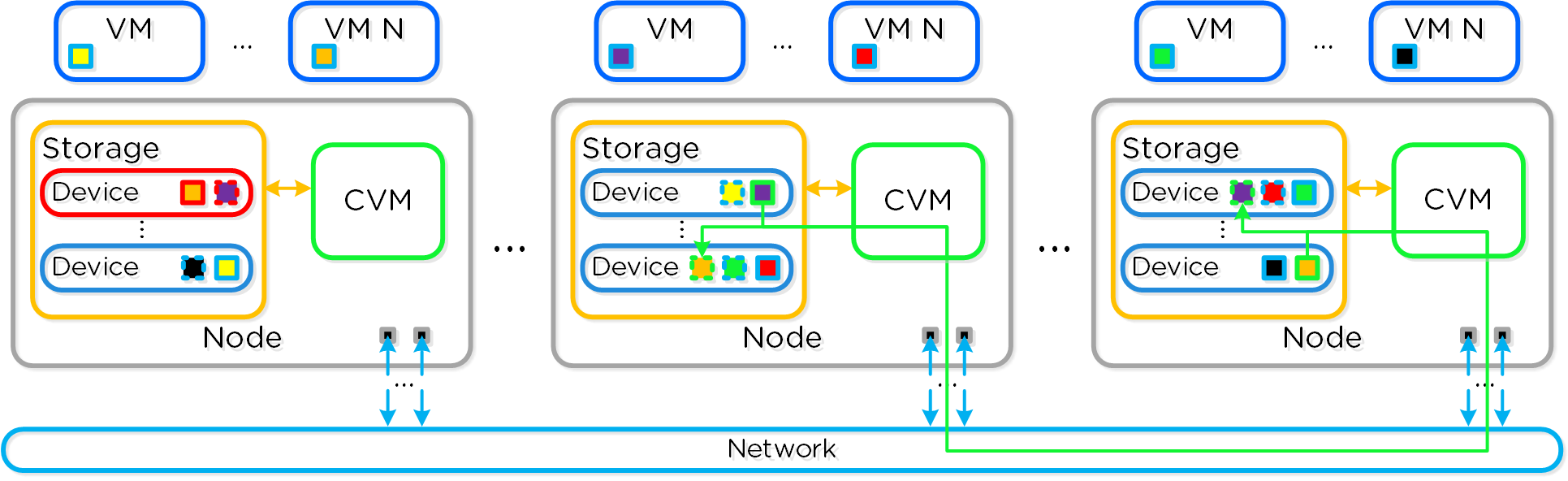
Важно отметить как Nutanix распределяет данные между всеми узлами / CVM / дисками; все узлы / CVM / диски будут участвовать в повторной репликации данных.
Это существенно снижает время требуемое для защиты данных, так как вся мощность кластера используется; чем больше кластер - тем быстрее будут защищены.
Отказ узла
Влияние на ВМ:
- Событие HA: Да
- Прерывание I/O: Нет
- Задержки: Без влияния
Выход из строя узла является отправной точкой для запуска события HA, ВМ размещаемые на сбойном узле будут перезапущены на других узлах кластера. После перезапуска, ВМ продолжат выполнять операции I/Os, и как обычно они будут обслуживаться локальными CVM.
Почти как и при сбое диска, Curator выполнит сканирование данных и найдет их копии на работающих узлах/дисках. Как только данные будут найдены - будет запущен процесс повторного их клонирования.
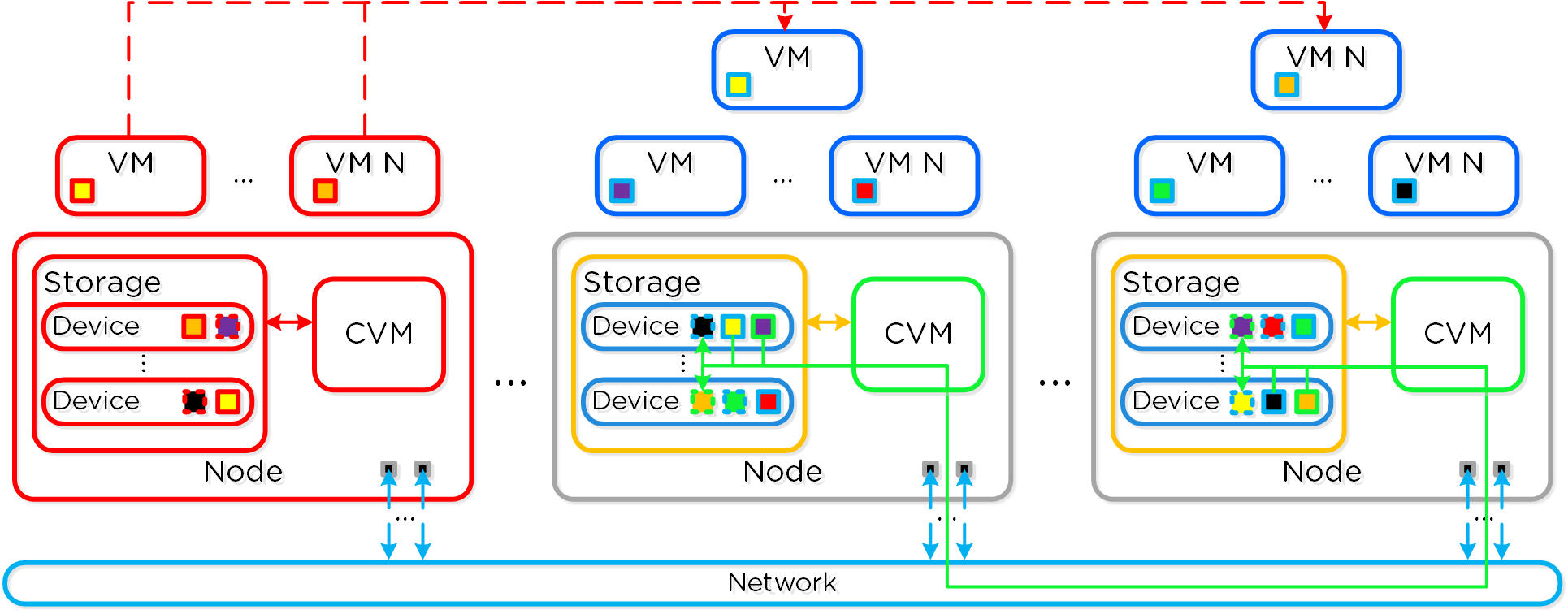
В случае если узел продолжает быть недоступным длительный период (начиная с версии ПО 4.6 - 30 минут) CVM этого узла будет удалена из кольца метаданных. Она будет подключена назад, как только снова станет доступной и проработает некоторое время.
Примечание
Совет от создателей
Состояние высокой доступности данных будет представлено в интерфейсе Prism.
Вы так же можете проверить состояние высокой доступности данных через cli:
# Статус на уровне узлов
ncli cluster get-domain-fault-tolerance-status type=node
# Статус на уровне блоков
ncli cluster get-domain-fault-tolerance-status type=rackable_unit
Информация о состоянии высокой доступности данных должны быть всегда актуальны, однако вы можете обновить их принудительно запустив задачу сервиса Curator.
"Отказ" CVM
"Отказ" CVM может возникать при перезагрузке CVM, которая будет временно недоступна на время перезагрузки. Система спроектирована таким образом, чтобы обрабатывать такие перезагрузки без проблем. В случае недоступности CVM все локальные операции I/O будут временно перенаправлены на другие CVM в кластере. Этот механизм может отличаться между разными гипервизорами.
Штатное обновление ПО кластера задействует функцию обеспечения HA для CVM, т.е. на время обновления CVM все I/O обрабатывают остальные CVM в кластере.
Влияние на ВМ:
- Событие HA: Нет
- Прерывание I/O: Нет
- Задержки: Потенциально могут вырасти, так как I/O осуществляется по сети
В случае "отказа" одной из CVM все обслуживаемые ей операции I/O будут распределены между остальными служебными ВМ в кластере. Для гипервизоров ESXi и Hyper-V обработка событий HA для CVM выполняется через операцию "CVM Autopathing", которая вызывается через HA.py (как “happy”), которая изменит пути для трафика идущего к внутреннему адресу (192.168.5.2) на внешние адреса других CVM в кластере. Это позволяет обеспечить доступ хранилищу и данным, перенаправив, I/O к другим CVM кластера.
Как только CVM вернется в рабочее состояние, пути будут удалены и все локальные операции I/O снова будут обрабатываться на локальной CVM.
В случае с AHV используется iSCSI multi-pathing где приоритетный путь - путь к CVM и два дополнительных указывают на другие CVM в кластере. В случае ошибок на основном пути - трафик будет переключен на один из запасных.
Как и в случае с ESXi и Hyper-V, если CVM вернется в рабочее состояние - будет снова выбран путь к локальной CVM.
Оптимизация емкости
Платформа Nutanix включает в себя широкий спектр технологий для оптимизации ресурсов хранения, которые эффективно используются при любом доступном пространстве хранения и типах нагрузки. Эти технологии являются интеллектуальными и адаптируются для различных типов нагрузок, исключая необходимость в ручной настройке и оптимизации.
Следующие типы оптимизации емкости используются:
- Избыточное кодирование
- Компрессия
- Дедупликация
Более подробно с каждой из этих функций можно ознакомиться в следующих разделах.
В таблице расписано какие виды оптимизации применяются к различным типам нагрузки:
| Преобразование Данных | Наиболее подходящие типы приложений | Комментарии |
|---|---|---|
| Избыточное кодирование | Большинство | Обеспечивает высокую доступность и сокращает перерасход пространства, в отличие от классического RF. Не влияет на производительность стандартных операций I/O. Есть небольшой перерасход в случае выхода из строя диска/узла/блока, когда данные должны быть декодированы. |
| Сжатие входящих данных | Все | Не влияет на случайные операции I/O, помогает увеличить утилизацию ресурсов хранения. Данный уровень сжатия обеспечивает прирост производительности для больших или последовательных операций I/O уменьшая количество данных для репликации и сокращая чтение с диска. |
| Фоновое сжатие данных | Не применимо | Данный уровень сжатия данных обеспечит эффективное сжатие и пост-процессинг для случайных и коротких операций I/O. |
| Дедупликация кэшируемых данных | P2V/V2V,Hyper-V (ODX),Клонирование между контейнерами | Повышение эффективности кэша для данных, которые не были созданы или склонированны при помощи ПО Acropolis |
| Дедупликация хранимых данных | Все | Преимущества перечисленных выше видов оптимизации и снижение накладных расходов на диск |
Избыточное кодирование
Платформа Nutanix использует фактор рекпликации для защиты и обеспечения доступности данных. Такой подход позволяет высочайший уровень производительности, так как не требует чтения более чем из одной копии данных и не требует пересчета контрольных сумм в случае отказов. Однако, он увеличивает стоимость хранения, так как объем хранимых данных увеличивается за счет хранения дополнительных полных копий данных.
Для обеспечения баланса между доступностью и сохранением полезного объема хранения DSF предоставляет возможность использования технологии избыточного кодирования (EC).
Концепция EC похожа на RAID (например 4, 5, 6, и пр.) где производится контроль четности, EC кодирует срез блоков данных на разных узлах и осуществляет расчет четности. В случае недоступности узла и/или диска четность используется для расчета потерянных блоков данных (происходит декодирование данных). На РХД блок данных - это группа экстентов, и каждый такой блок находится и принадлежит разным файлам (vDisk).
Количество данных и блоков контроля четности в срезе - настраивается на базе уровня устойчивости к сбоям. Конфигурация определяет количество <блоков данных> и количество <блоков четности>.
Например, доступность уровня “RF2 like” (т.е. N+1) может содержать 3 или 4 блока данных и 1 блок для контроля четности на срез данных (т.е. 3/1 или 4/1). Уровень “RF3 like” (т.е. N+2) может содержать 3 или 4 блока данных и 2 блока для контроля четности (т.е. 3/2 или 4/2).
Примечание
EC + домены доступности
Начиная с версии 5.8, EC может размещать блоки данных и блоки контроля четности так, чтобы обеспечивать отказ блоков согласно идее доменов доступности. (До версии 5.8 данные размещались так, чтобы отказ узлов не приводил к потере данных).
Уже созданные контейнеры с включенной функцией EC не будут незамедлительно перенастроены согласно доменам доступности на уровне блоков сразу после обновления до версии 5.8. Только если блоков и узлов в кластере достаточно (strip size (k+n) + 1) режим обработки отказов на уровне узлов будет перенастроен в режим обработки отказов блоков. Новые контейнеры с включенным EC будут сразу размещаться для обработки отказов на уровне блоков.
Ожидаемый перерасход ресурсов может быть рассчитан как <кол-во блоков четности> / <кол-во блоков данных>. Например, срез данных с соотношением 4/1 имеет 25% перерасхода пространства, или 1.25X в сравнении с 2X для RF2. Срез данных 4/2 будет иметь 50% перерасхода, или 1.5X в сравнении с 3X для RF3.
В таблице ниже расписаны примеры перерасхода ресурсов при разных уровнях избыточности:
| Размер кластера (Узлы) |
Размер среза данных EC (data/parity blocks) |
Перерасход ресурсов при EC (vs. 2X of RF2) |
Размер среза данных EC (data/parity) |
Перерасход ресурсов при (vs. 3X of RF3) |
| 4 | 2/1 | 1.5X | N/A | N/A |
| 5 | 3/1 | 1.33X | N/A | N/A |
| 6 | 4/1 | 1.25X | 2/2 | 2X |
| 7 | 4/1 | 1.25X | 3/2 | 1.6X |
| 8+ | 4/1 | 1.25X | 4/2 | 1.5X |
Примечание
Совет от создателей
Рекомендуется иметь хотя бы один дополнительный узел (или блок) в кластере, чем требуемое количество узлов/блоков для настройки EC. Это необходимо, для штатной обработки отказа устройства и нормального перераспределения данных. Никакой дополнительной нагрузки на чтение не будет, как только срез данных будет восстановлен и данные будут перераспределены. Например, для среза данных 4/1 необходимо иметь как минимум 6 узлов в кластере для обеспечения отказа узла или же 6 блоков, для обеспечения отказа блока целиком. Таблица выше описывает наиболее оптимальные конфигурации кластеров для использования избыточного кодирования данных.
Кодирование происходит в фоновом режиме и использует возможности сервиса Curator MapReduce для распределения нагрузки по узлам кластера. Так как это фоновая операция - влияние на производительность активных операций I/O не происходит.
Стандартная среда с использованием RF будет выглядеть следующим образом:
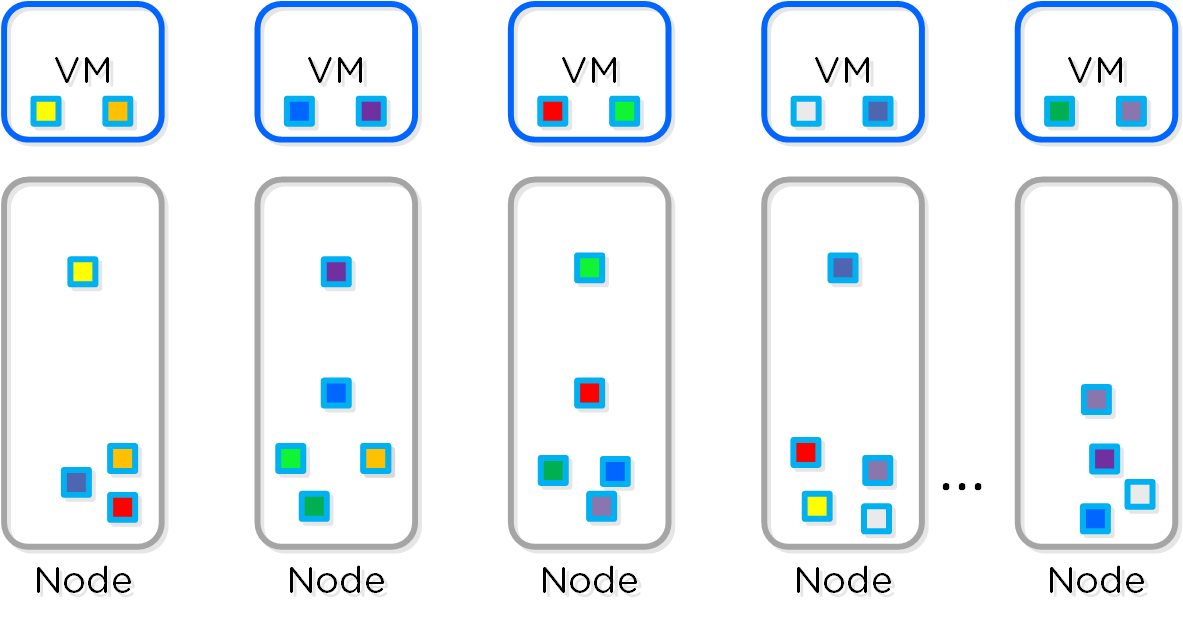
В этом случае у нас есть данных для которых выполняется и RF2 и RF3, основные копии которых размещаются локально, а реплики - распределяются по всему кластеру.
Когда Curator выполняет полное сканирование он найдет подходящие группы экстентов, к которым можно применить кодирование. Подходящие - значит, что эти группы экстентов должны быть "холодными", т.е. их записали какое-то время назад. Платформа считает данные "холодными" согласно настройке сервиса Curator - Gflag: curator_erasure_code_threshold_seconds. После того как подходящий кандидат был найден задача кодирования будет распределена при помощи подсистемы Chronos.
Ниже изображены два типа срезов данных с которыми работает EC - 4/1 и 3/2 :
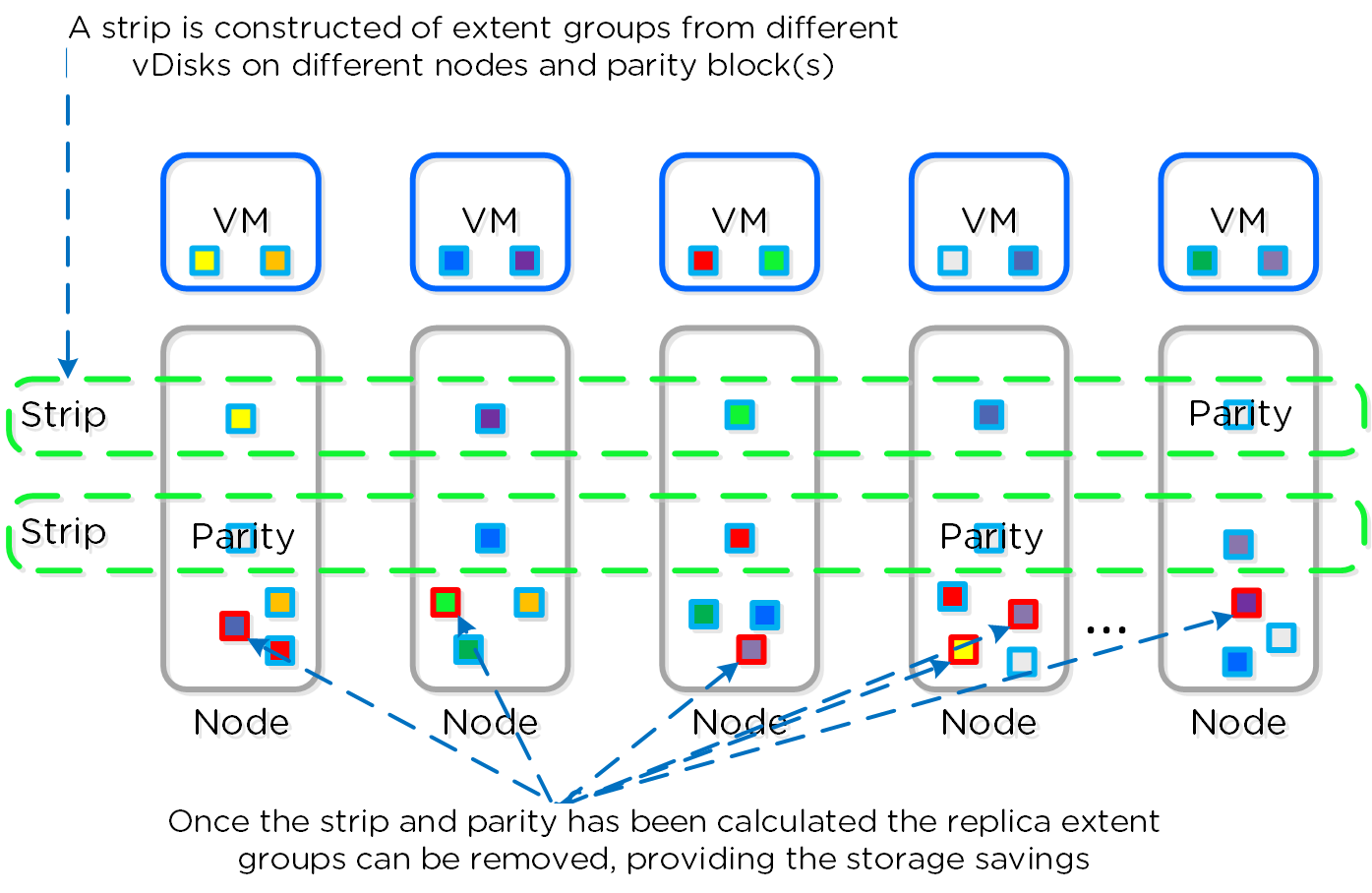
После успешного кодирования среза данных и вычисления четности лишние реплики групп экстентов удаляются.
На следующем рисунке показана среда после запуска EC и эффективном хранении :
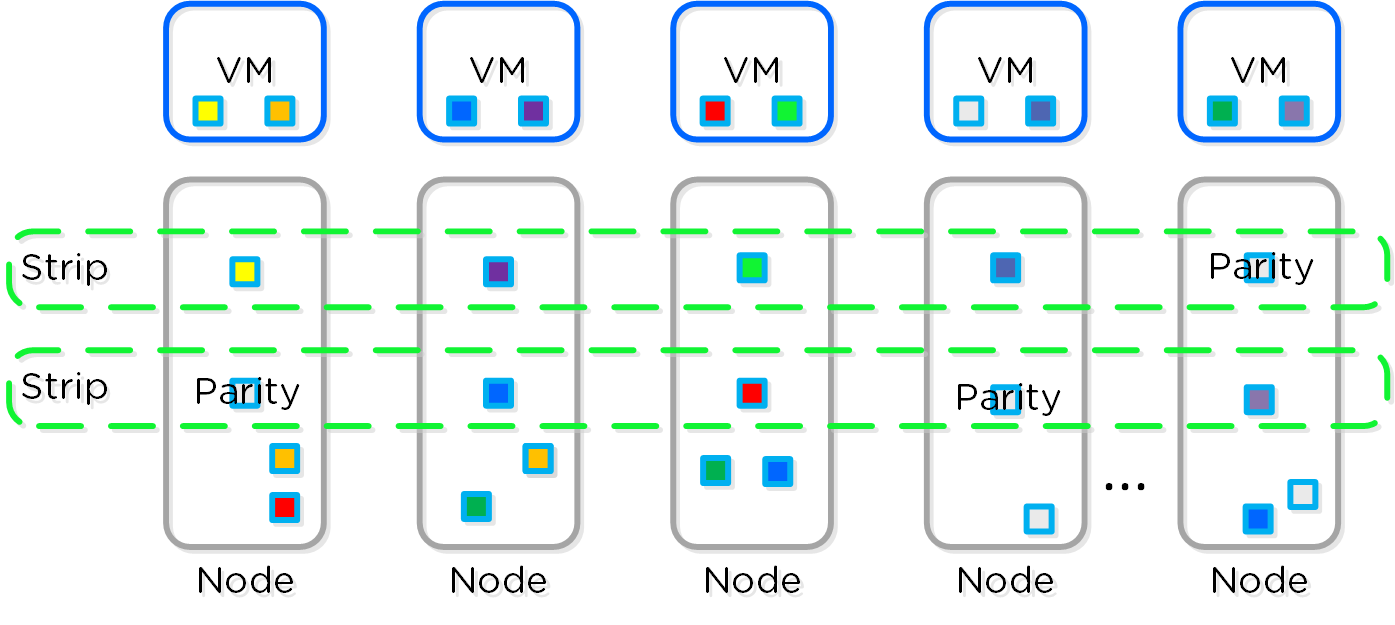
Примечание
Совет от создателей
EC прекрасно работает с сжатием входящих данных, что обеспечит дополнительный уровень экономии пространства. Я использую такой подход в моих средах.
Компрессия
Краткий рассказ на английском языке доступен по ссылке
Платформа Nutanix использует собственный механизм оптимизации пространства - Capacity Optimization Engine (COE). Он отвечает за выполнение преобразования данных для увеличения эффективности использования дисков. На текущий момент компрессия - одна из основных возможностей COE обеспечивающая оптимизацию хранения данных. DSF обеспечивает компрессию входящих и хранимых данных, чтобы максимально отвечать запросам пользователей. Начиная с 5.1 компрессия хранимых данных используется по умолчанию.
Компрессия входящих данных будет выполняться для последовательных потоков данных или больших операций I/O (>64K) в момент записи на хранилище экстентов (SSD + HDD). Сюда включен так же процесс сброса данных из OpLog, и пропущенную им последовательную запись.
Примечание
Компрессия OpLog
С версии 5.0, OpLog будет выполнять компрессию всех входящих потоков записи >4K, которые показывают хороший уровень сжатия (Gflag: vdisk_distributed_oplog_enable_compression). Это обеспечивает большую эффективность использования емкости OpLog и способствует стабильной производительности.
Когда происходит перемещение данных из OpLog в хранилище экстентов данные будут декомпрессированны, объединены и снова сжаты до объектов объемом 32K (начиная с 5.1).
Эта функция постоянно включена и не требует пользовательской настройки.
Компрессия хранимых данных будет применяться уже после записи данных на РХД, посредством запуска задач Curator. Задачи выполняются равномерно по всему кластеру. Когда включена компрессия для входящих данных, а операции I/O в основном случайные, то данные будут записаны в OpLog без компрессии, консолидированы и только потом для них выполнится компрессия перед записью на хранилище экстентов.
Nutanix использует LZ4 и LZ4HC для компрессии данных Asterix и за его пределами. До Asterix используется библиотека Google Snappy которая предоставляет хороший коэффициент сжатия данных с минимальным перерасходом вычислительных ресурсов, а так же выполняет процедуры компрессии/декомпрессии максимально быстро.
Нормальные данные будут сжиматься с использованием LZ4 который предоставляет отличное соотношение компрессии и производительности. Для "холодных" данных будет использоваться LZ4HC для увеличения коэффициента сжатия.
Храктеристики "холодных" данных:
- Нормальные данные: Не было запросов R/W более 3 дней (Gflag: curator_medium_compress_mutable_data_delay_secs)
- Неизменные данные (снимки):Не было запросов R/W более 1 дня (Gflag: curator_medium_compress_immutable_data_delay_secs)
Ниже приведен пример того, как происходит взаимодействие компрессии входящих данных и путей данных РХД:
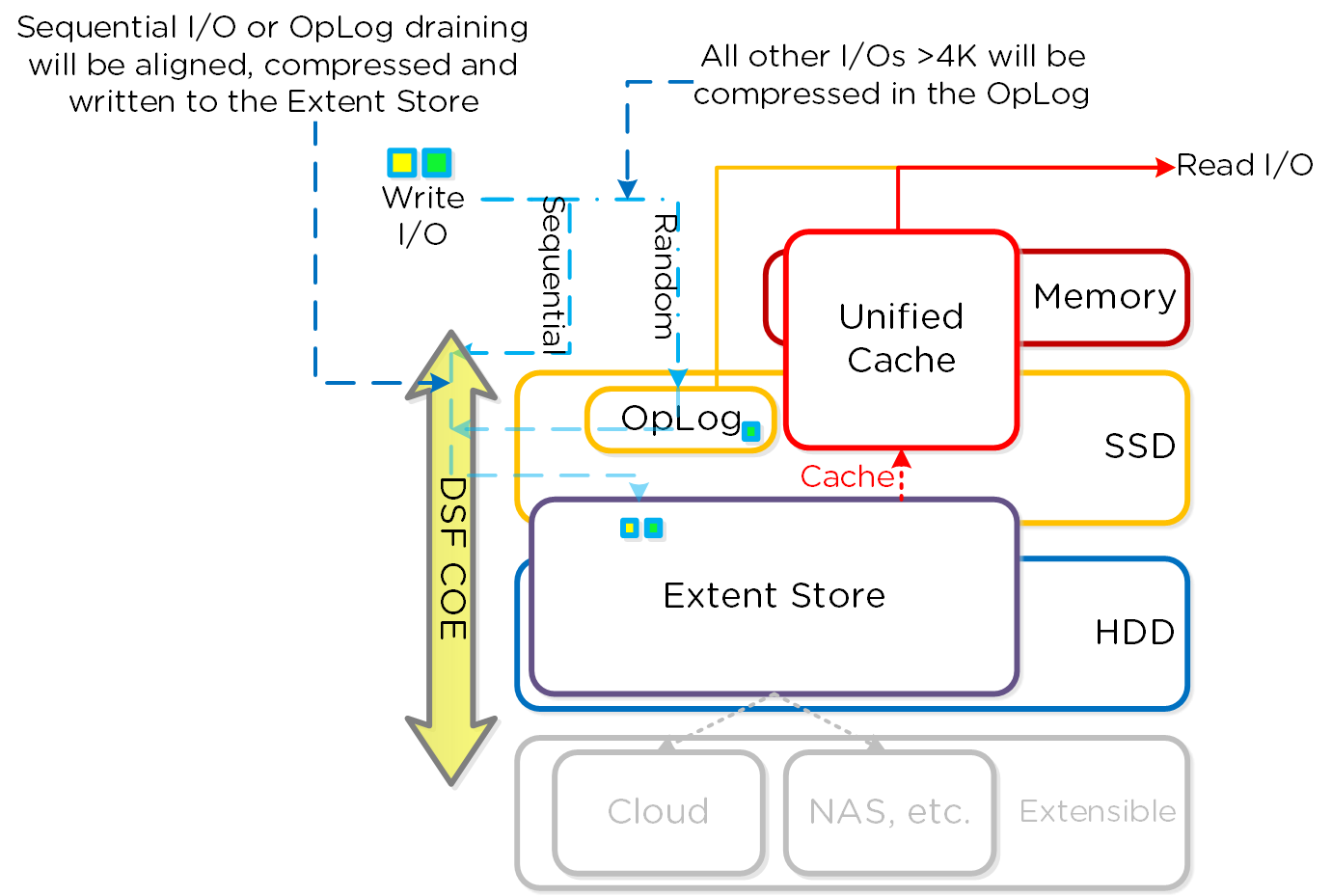
Примечание
Совет от создателей
Старайтесь всегда использовать компрессию входящих данных, так как происходит сжатие только больших операций или последовательных потоков записи, это никак не влияет на производительность при случайной записи.
Это так же позволит увеличить доступную для использования емкость на уровне SSD, при этом увеличив производительность и позволит большему количеству данных находиться на SSD. А так же, сжимая большие или последовательные данные сразу на входе достигается большая производительность при выполнении репликации, так как репликация будет выполняться для уже сжатых данных. Это значит что внутри кластера будет копироваться меньший объем данных, чем без использования компрессии.
Компрессия входящих данных также хорошо сочетается с технологией избыточного кодирования.
Для автономного сжатия все новые операции I/O записываются в несжатом состоянии и следуют обычному пути операций I/O на DSF. После настраиваемой задержки данные могут быть сжаты. Сжатие может происходить в любом месте хранилища экстентов. Автономное сжатие использует Curator MapReduce, чтобы все узлы участвовали в процессе сжатия данных. Сервис Cronos будет следить за задачами по сжатию данных.
Ниже показан пример как компрессия хранимых данных взаимодействует с путями I/O:
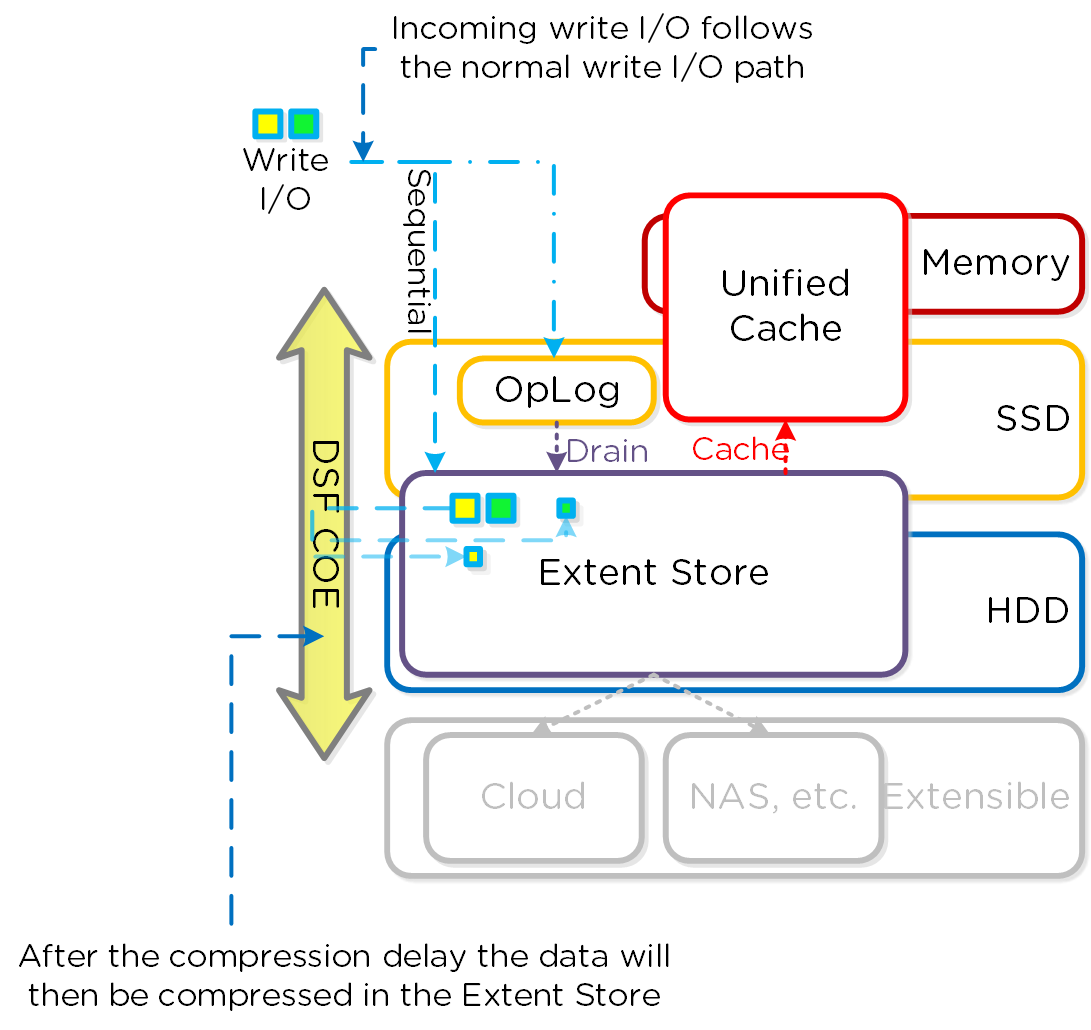
Для операций I/O на чтение данные сначала проходят декомпресиию в памяти и затем выполняется непосредственно операция I/O.
Вы можете посмотреть текущий коэффициент сжатия данных через пользовательский интерфейс Prism в секции "Storage" главного экрана.
Эластичная дедупликация
Краткий рассказ на английском языке доступен по ссылке
Механизм The Elastic Dedupe Engine - реализован на программном уровне и позволяет обеспечивать дедупликацию на уровне Хранилища экстент, а так же повышать производительность Универсального Кэша. Потоки данных хэшируются с использованием SHA-1 хешей с гранулярностью в 16K. Хэш создается на этапе попадания данных в систему и сохраняется как часть метаданных. Примечание: Изначально мы использовали гранулярность в 4K, однако затем тесты 16K показали лучшее соотношение эффективности дедупликации и перерасход при работе метаданных. Дедуплицированные данные попадают в Универсальный кеш с гранулярностью в 4K.
Классические решения выполняют расчет хэшей в фоновом процессе после того, как данные записаны. Такой подход требует выполнять повторное чтение. Платформа Nutanix выполняет расчет хэшей на лету. Для копий данных, которые могут быть дедуплицированы на уровне хранения выполнять повторное чтение или их сканирование. Более того - лишние копии данных можно удалить.
Чтобы сделать работу с метаданными более эффективной пересчет хешей постоянно мониторится для проверки на возможность дедуплицирования. хэши с низким значением счетчика будут сброшены для минимизации перерасхода при работе с метаданными. Для минимизации фрагментации полные экстенты будут дедуплицированы в первую очередь.
Примечание
Совет от создателей
Используйте дедупликацию для базовых образов (вы можете рассчитать для них хэши вручную используя vdisk_manipulator), чтобы воспользоваться преимуществами единого кэша.
Используйте дедупликацию для P2V / V2V, когда используется Hyper-V с ODX копирует данные целиком, или при клонировании между контейнерами (рекомендуется использовать один контейнер).
В большинстве других случаев сжатие даст наибольшую экономию мощности и должно использоваться вместо дедупликации.
На следующем рисунке показан пример того, как модуль Elastic Dedupe масштабирует и обрабатывает локальные запросы I/O:
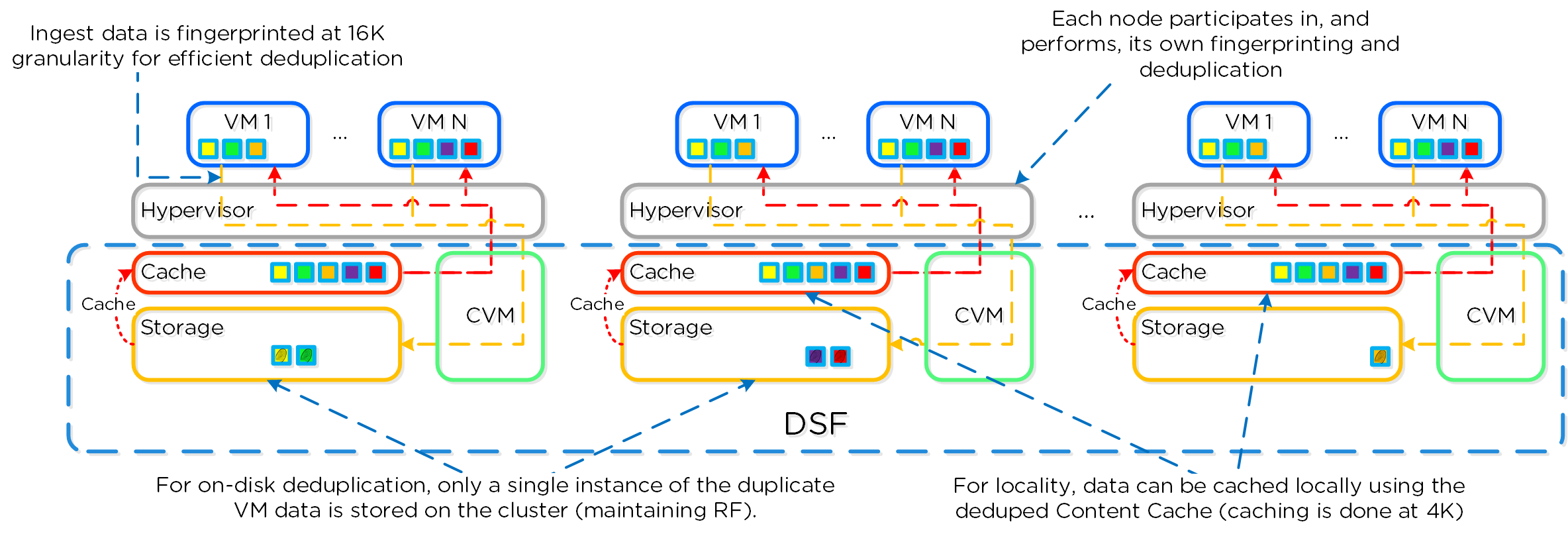
Снятие хэшей выполняется в процессе попадания данных на кластер для операций IO более 64K (при начале операции I/O или при сбросе из OpLog). Intel помогает ускорить процесс расчета SHA-1, с минимальным перерасходом процессорного времени. В случаях, когда хэши не были сняты для входящих I/O (например, имеют размер менее 64K) хэши будут сняты в фоновом процессе. Механизм Elastic Deduplication Engine охватывает как хранилище экстентов, так и универсальный кэш. По мере определения дедуплицированных данных, на основе копий с одинаковыми хэшами, фоновый процесс будет удалять "лишние" дубликаты используя сервис Curator, построенный на базе механизмов MapReduce. Для считываемых данных, выполняется передача данных в Универсальный кэш, который является многоуровневым. Любые последующие запросы к данным, имеющие тот же хэш, будут извлекаться непосредственно из кэша. Подробную информацию о структуре единого кэша смотрите в подразделе "Единый кэш" обзора путей ввода-вывода.
Примечание
Fingerprinted vDisk Offsets
Начиная с версии 4.6.1, в ПО отсутствуют какие-либо огранчения на количество файлов (vDisk) которые могут быть дедуплицированы или сжаты.
До версии 4.6.1 это количетсво было увеличено до 24GB благодаря более эффективной работе с метаданными. До версии 4.5 только первые 12GB файла/vDisk могли быть сжаты. Это было сделано, чтобы поддержать небольшой размер метаданных, и предполагалось, что в первых 12Gb может находится ОС - это очень похожие данные.
На рисунке ниже изображена схема отношений Elastic Dedupe Engine и путей ввода-вывода:
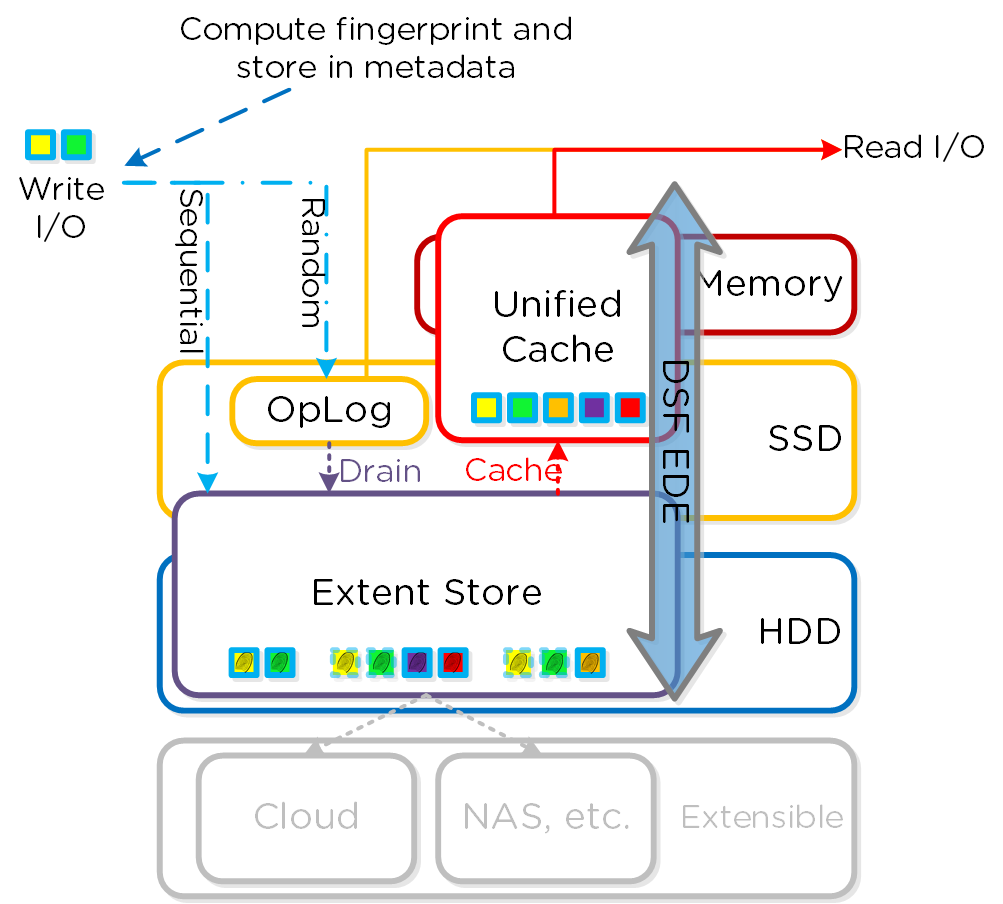
Текущий уровень дедупликации можно посмотреть через интерфейс Prism, в разделе Storage.
Примечание
Дедупликация + компрессия
Начиная с версии 4.5 и дедупликация и компрессия могут быть включены для одного и того же контейнера. В случае, если данные не могут быть дедуплицированны, продолжайте использовать компрессию.
Распределение уровней хранения
В главе посвященной распределению нагрузки по дискам, говорилось, что вся емкость распределена между всеми узлами и дисками в кластере Nutanix и ILM будет использоваться для хранения горячих данных локально. Похожая концепция используется для работы с разными уровнями хранения, так для переноса данных между уровнями SSD и HDD механизм ILM будет отвечать за управление событиями перемещения данных. Локальный уровень хранения SSD всегда будет иметь более высокий приоритет, для всех операций ввода-вывода ВМ запущенных на конкретном узле, при этом ресурсы всех SSD всего кластера так же доступны для всех узлов. Уровень SSD всегда обеспечивает максимальную производительность и очень важен для гибридных хранилищ.
Приоритеты различных уровней хранения могут быть классифицирована следующим образом:
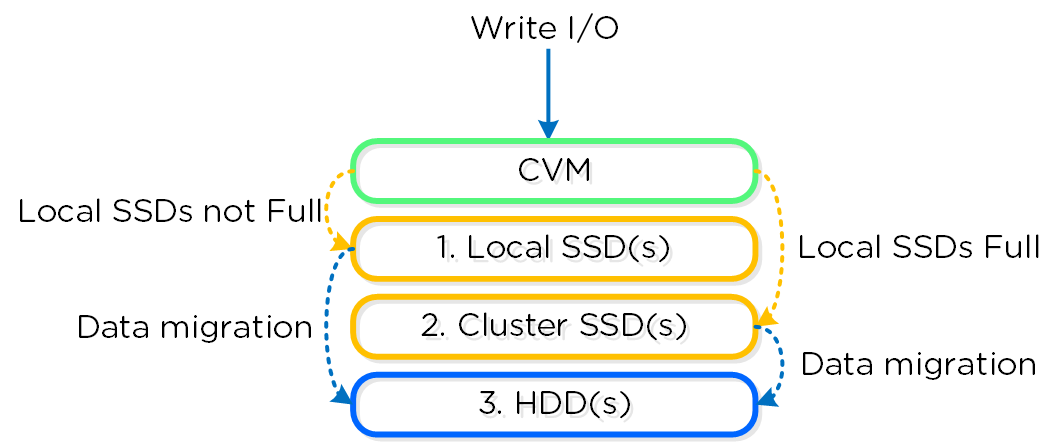
Специфические типы ресурсов (например SSD, HDD) собраны вместе и формируют уровень хранения на уровне всего кластера. Это значит, что любой узел кластера может использовать всю емкость хранилища, в независимости локальная эта емкость или нет.
На следующем рисунке показан высокоуровневый пример того, как выглядит общее хранилище:
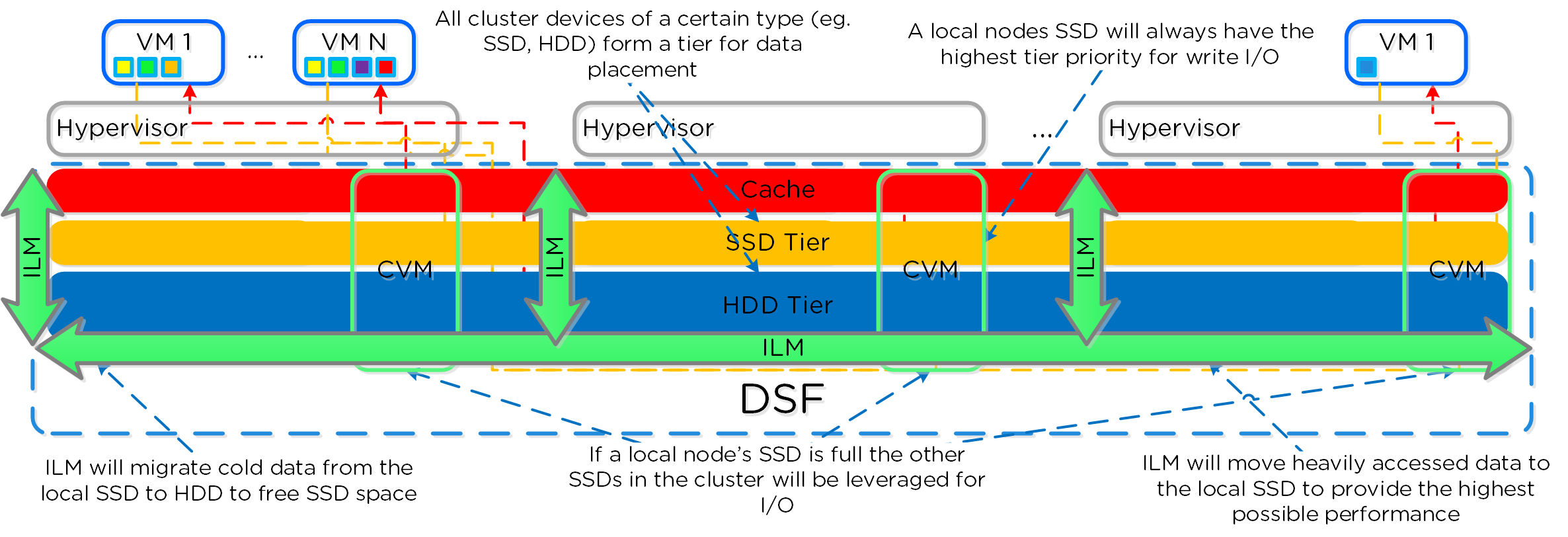
Стандартный вопрос - что будет, если локальные SSD будут заполнены? Как и говорилось в разделе о балансировке нагрузке между дисками - ключевая идея состоит в том, чтобы постараться сохранить равномерную нагрузку между всеми дисками/узлами кластера. В случае высокой нагрузки на локальные SSD, механизм балансировки начнет перемещать самые холодные данные на уровень HDD и другие SSD в кластере. Таким образом количество свободного пространства на локальных SSD будет увеличено и позволит продолжить запись на локальные SSD и избежать передачи лишних данных по сети. Ключевой момент - CVM будут использовать локальные SSD пока это возможно, для устранения любых потенциальных узких мест, и станут передавать данные по сети только в крайних случаях.
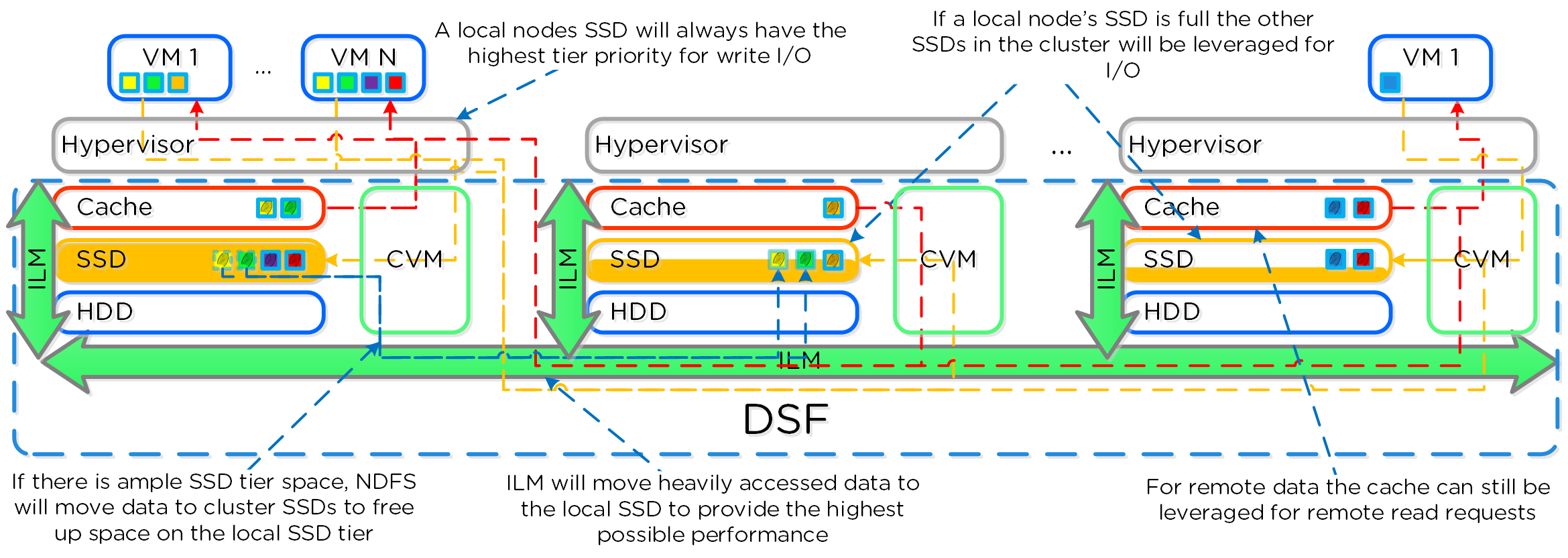
Другой случай - когда общий уровень загрузки превышает определенное пороговое значение [curator_tier_usage_ilm_threshold_percent (Default=75)] когда DSF ILM выполнит запуск задания Curator, которое начнет перенос данных с уровня SSD на уровень HDD. Данный процесс будет выполняться каждый раз, чтобы обеспечить нужное количество свободного пространства в соответствии с указанным пороговым значением [curator_tier_free_up_percent_by_ilm (Default=15)]. Данные для принудительного переноса на уровень HDD будут выбраны в соответствии с датой/временем последнего доступа к ним. В случае, когда уровень SSD загружен на 95%, 20% данных на этом уровне хранения подлежат переносу на уровень HDD (95% –> 75%).
Однако, если уровень загрузки равен 80%, только 15% данных будут перенесены на уровень HDD.
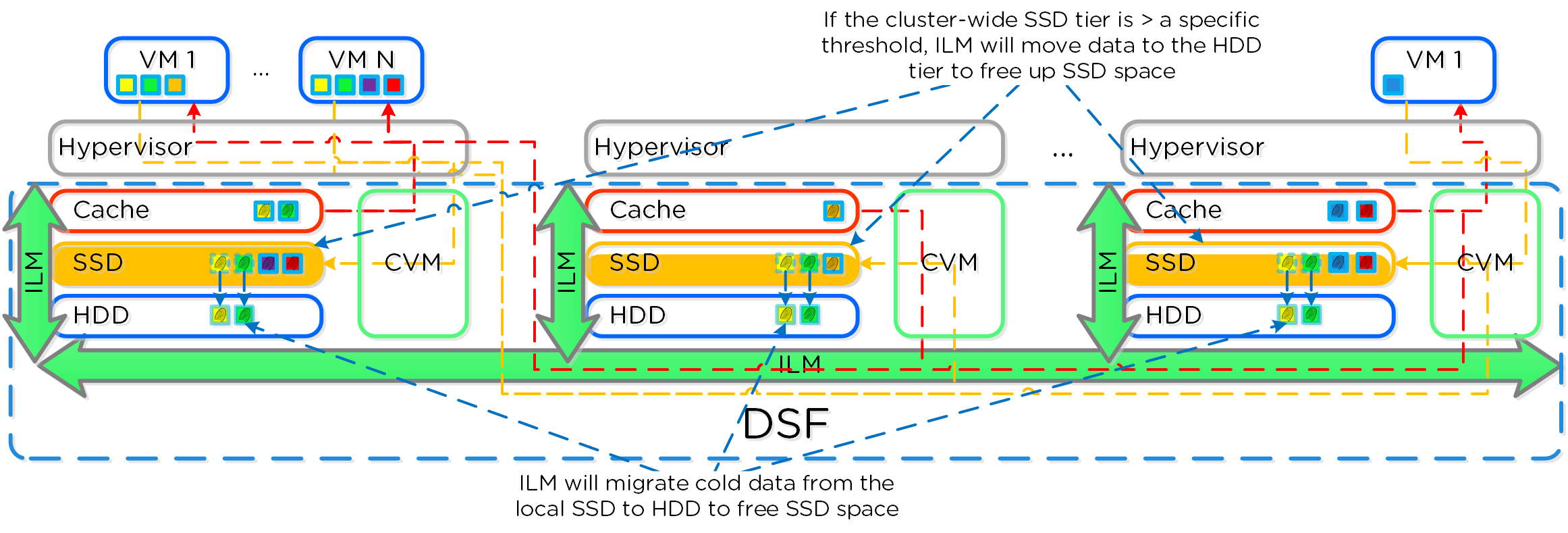
DSF ILM постоянно ведет наблюдение за профилем операций ввода-вывода и выполняет перенос данных по мере необходимости.
Балансировка дисков
Краткий рассказ на английском языке доступен по ссылке
DSF разработан так, чтобы быть очень динамичной платформой, которая может реагировать на разные типы нагрузки и работать с разными типами узлов. Чтобы иметь возможность собирать в кластере узлы рассчитанные под высокие вычислительные нагрузки (3050, и пр.) и рассчитанные на большие объемы хранения (60X0 и т.д.) Обеспечение равномерного распределения данных является важным элементом при смешивании узлов с большими объемами хранения. DSF имеет стандартную функцию, которая называется Балансировка дисков, и используется для равномерного распределения данных между дисками в кластере. Балансировка дисков работает на узлах, с локальными данными на локальных дисках этих узлов и интегрирована с DSF ILM. Цель - сохранять равномерное распределение данных между узлами, и следить за пороговыми значениями.
На следующем рисунке показан пример смешанного кластера (3050 + 6050) в "несбалансированном" состоянии:
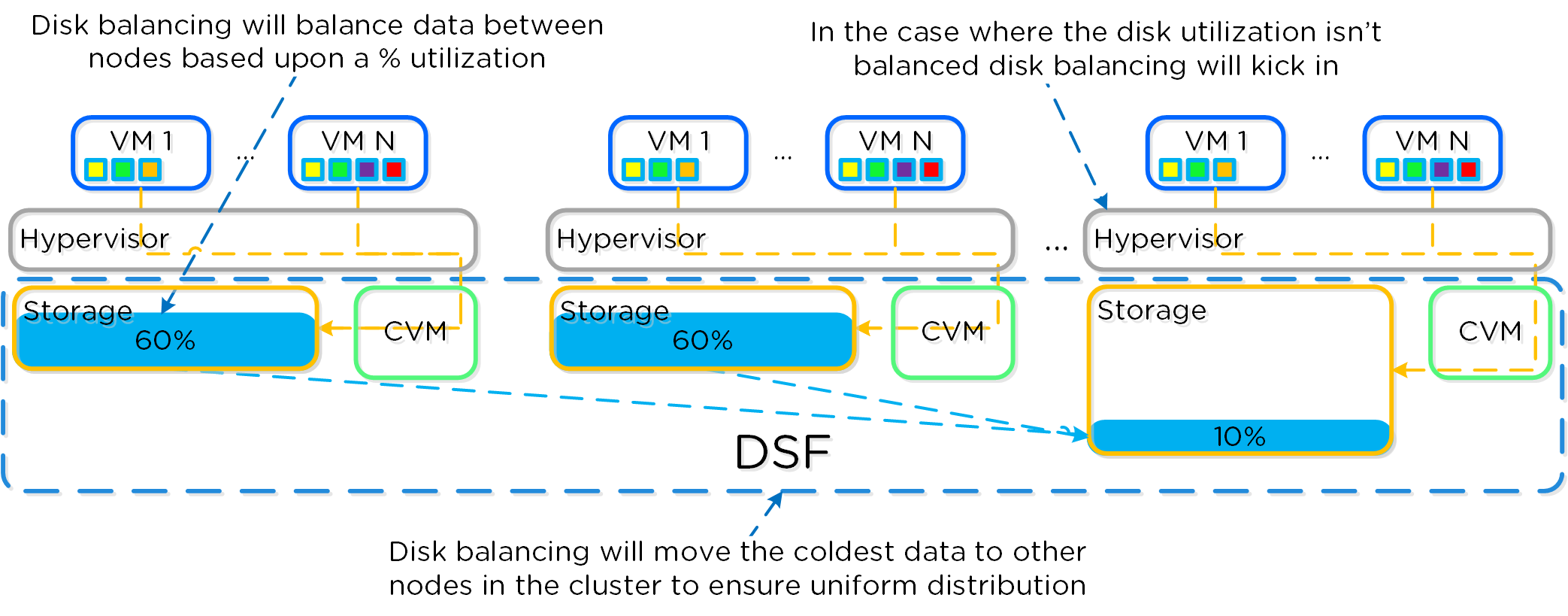
Балансировка дисков использует Curator и запускает процесс балансировки в случае если достигнуто пороговое значение (например, загрузка локальных дисков узла достигла > n %). В случае, если данные не сбалансированы, Curator определит, какие данные должны быть перемещены, и распределит задачу по распределению между узлами кластера. В случае, если кластер является однородным (например только из 3050), использование должно быть достаточно равномерным. Однако, если определенные ВМ имеют больше данных чем остальные, то в распределении емкости между узлами может возникнуть перекос. В этом случае, механизм балансировки запустит процесс перемещения холодных данных этого узла на остальные узлы в кластере. В случае, если кластер неоднородный (например 3050 + 6020/50/70), или если узлы используется в режиме "только хранение", то, скорее всего возникнет необходимость в перемещении данных.
На следующем рисунке показан пример смешанного кластера после выполнения операции балансировки:
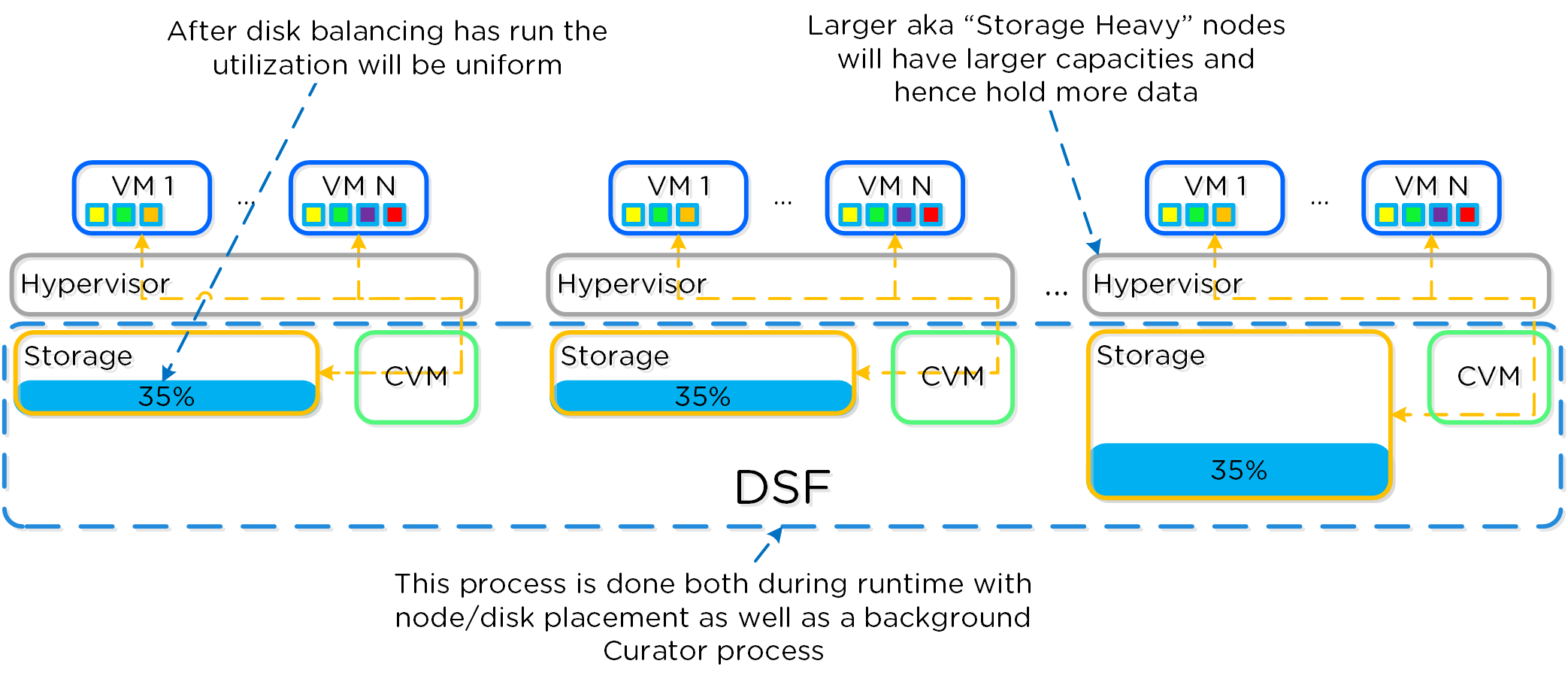
В некоторых случаях, зазкачик может запускать узлы в режиме “storage-only”. В этом случае CVM будет выполнять задачи работы с хранилищем. В этом случае, вся емкость ОЗУ узла будет отдана под большой кэш на чтение.
На следующем рисунке показана схема, в которой выделенный для хранения узел будет выглядеть в смешанном кластере, после балансировки, когда на него перемещаются данные одной из активных ВМ:
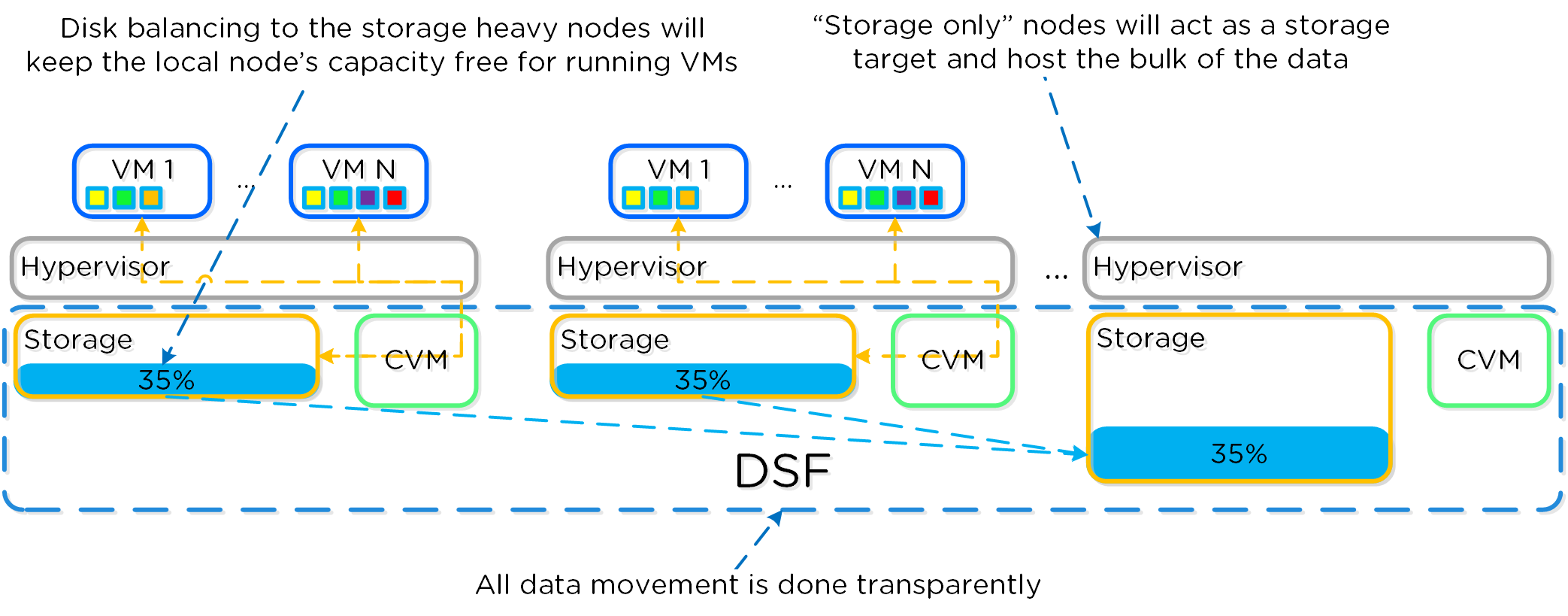
Снимки и клоны
Краткий рассказ на английском языке доступен по ссылке
DSF имеет встроенную поддержку создания снимков и клонов, которые могут быть сделан посредством VAAI, ODX, ncli, REST, Prism, и так далее. Снимки и клоны использую алгоритм redirect-on-write, который является наиболее эффективным и действенным. Как пояснялось в главе Структура Данных, ВМ состоит из файлов (vmdk/vhdx) которые именуются vDisk в Платформе Nutanix.
vDisk состоит из эктсентов, которые являются логическими непрерывными последовательностями кусочков данных, которые хранятся в группах экстентов, которые являются физически непрерывными данными, хранящимися в виде файлов на устройствах хранения. Когда снимок или клон сделаны, базовый vDisk помечается как неизменяемый, и для записи/чтения создается другой vDisk. В этот момент, оба vDisks имеют одинаковые карты блоков, которые представляют собой сопоставление метаданных виртуального диска с соответствующими экстентами. В отличие от традиционных подходов, использующие цепочки снимков (которые увеличивают задержки), каждый vDisk имеет собственную карту блоков. Это позволяет избежать перерасхода ресурсов при работе с большой глубиной снимков, и позволяют создавать еще снимки без влияния на производительность.
На следующем рисунке показан пример того, как это работает при создании моментального снимка (Примечание: Я должен упомянуть, что использовал в качестве прототипа схемы NTAP, так как они показались мне достаточно детальными и понятными):
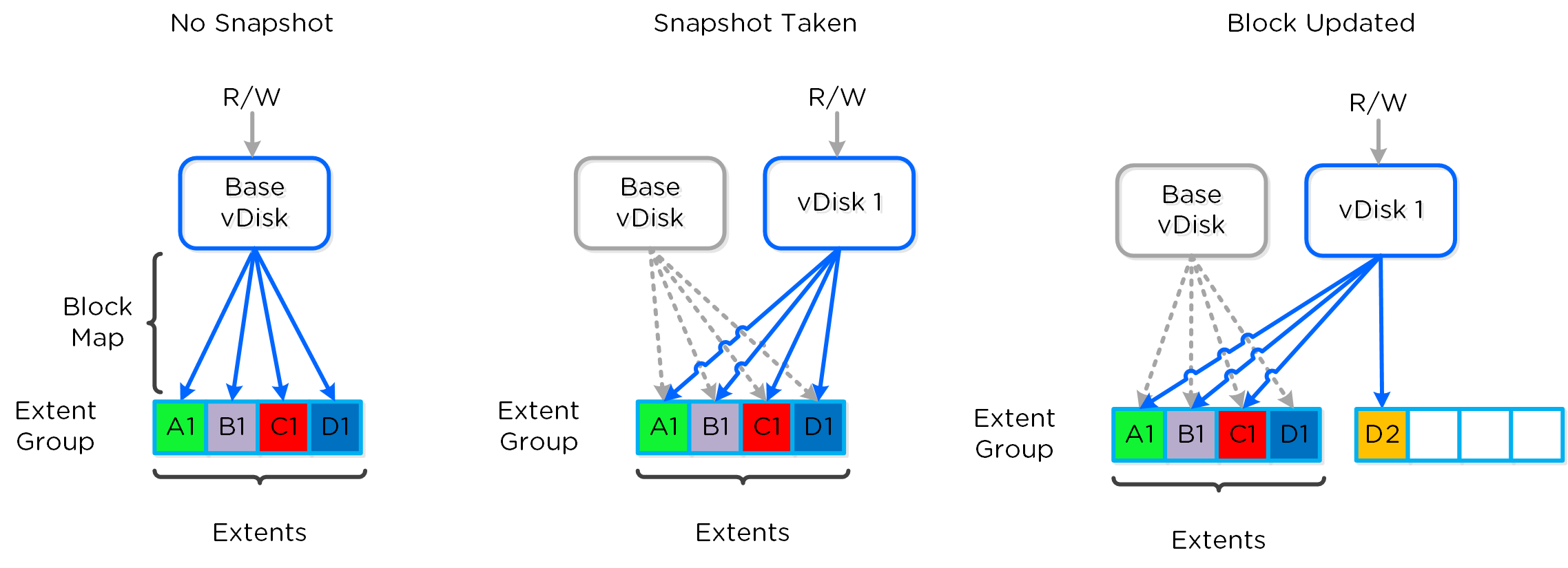
Тот же метод применяется при выполнении моментального снимка или клонирования ранее привязанного или склонированного vDisk:
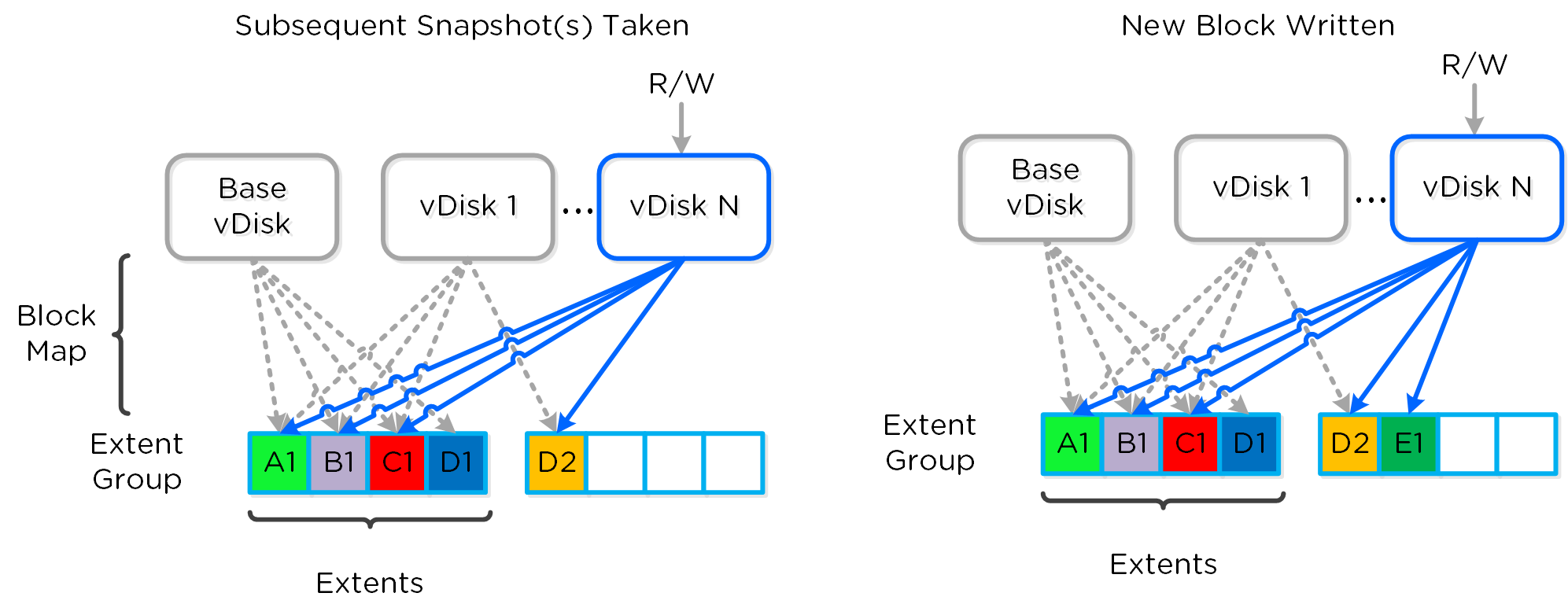
Те же методы используются для снимков и/или клонов дисков ВМ или vDisk. Когда ВМ или vDisk клонируются, текущая карта блоков блокируется и создается клон. Эта процедура изменяет метаданные, но никаких процедур ввода-вывода при этом не выполняется. Такой же метод при клонировании клонов; по существу, ранее клонированная виртуальная машина действует как "базовый vDisk" и при клонировании, эта карта блоков заблокирована и созданы два " клона: один для клонируемой виртуальной машины, а другой для нового клона. Максимальное количество клонов не ограничено.
Они оба наследуют предыдущую карту блоков, и любые новые записи/обновления будут происходить на их отдельных картах блоков.
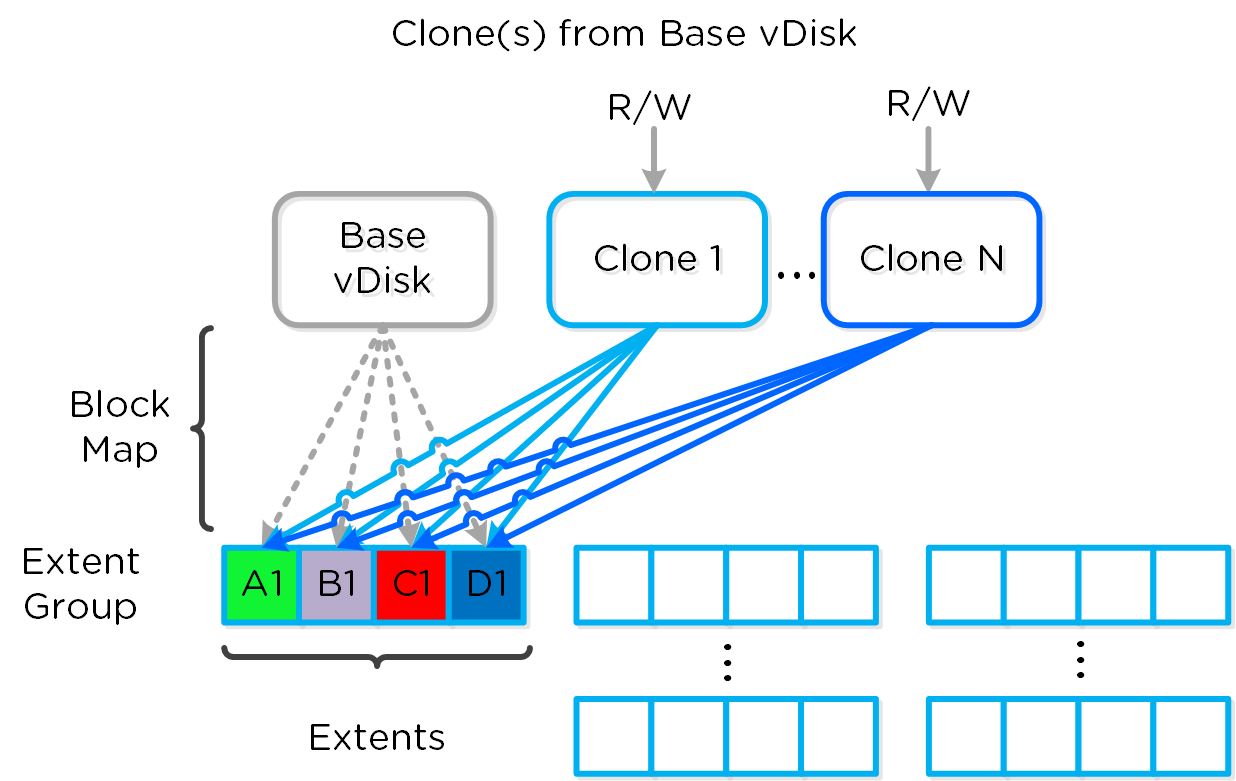
Как упоминалось ранее, каждая виртуальная машина/vDisk имеет свою собственную карту блоков. Таким образом, в приведенном выше примере все клоны из базовой виртуальной машины теперь будут владеть своей картой блоков, и любая запись/обновление будет происходить там.
На следующем рисунке показан пример того, как это выглядит:
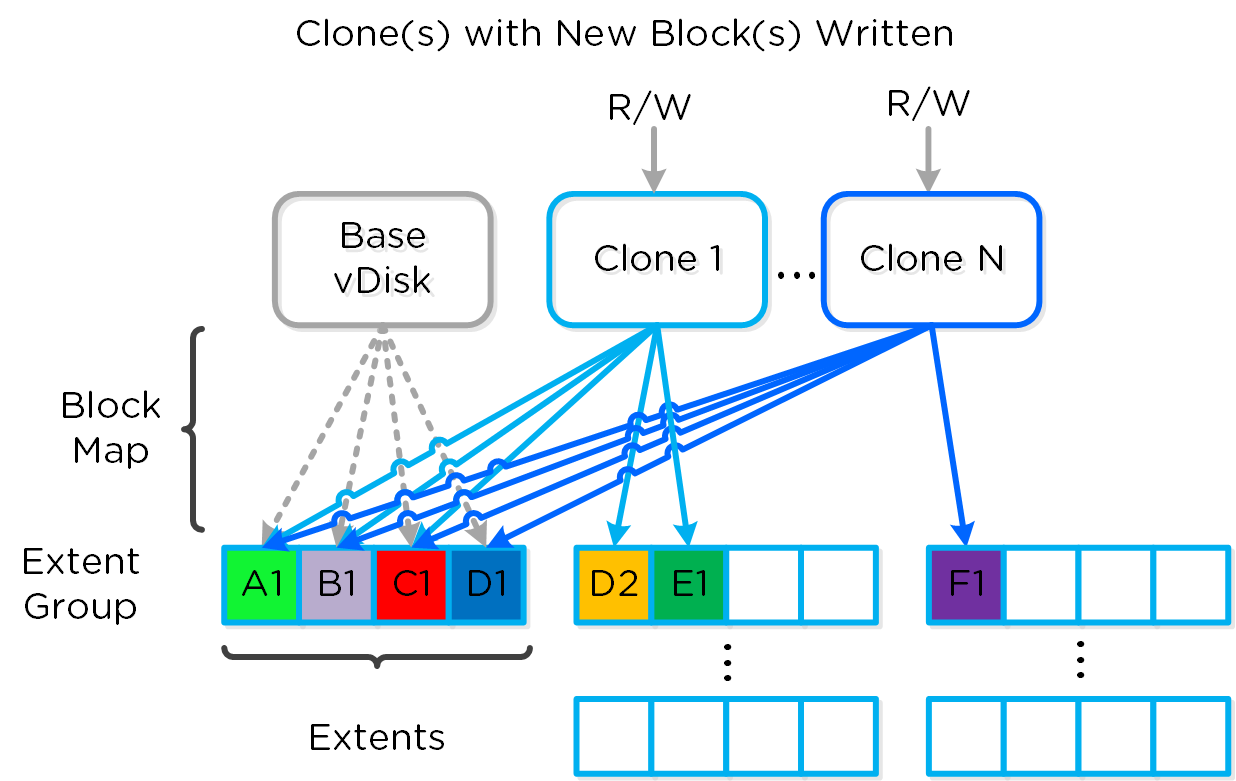
Любые последующие клоны или моментальные снимки виртуальной машины или виртуального диска приведут к блокировке исходной карты блоков и созданию новой для R/W-доступа.
Сеть и ввод-вывод
Краткий рассказ на английском языке доступен по ссылке
Платформа Nutanix не использует никаких специальных средств для обеспечения коммуникации между узлами, вместо этого используется стандартная сеть 10G. Все операции ввод-вывода ВМ запущенных в рамках кластера обслуживаются гипервизором в выделенной приватной сети. Запрос ввода-вывода будет обрабатываться гипервизором, который передаст запрос к приватному IP на локальной CVM. CVM выполнит репликацию записанных данных с другими узлами Nutanix, используя их внешние IP-адреса в публичной сети 10G. Для всех операций чтения, обработка будет осуществляться локально, и в большинстве случаев никаких дополнительных запросов по сети передаваться не будет. Это значит, что только по сети передается только трафик касающийся репликации данных между узлами кластера. CVM будет передавать запросы на запись другим CVM только в случае, если CVM не работает или локальные копии данных недоступны. Так же все задачи, запускаемые на всем кластере, такие как балансировка дисков будут временно создавать всплески нагрузки на сеть.
На следующем рисунке показан пример взаимодействия пути ввода-вывода виртуальной машины с приватной и общей сетью 10G:
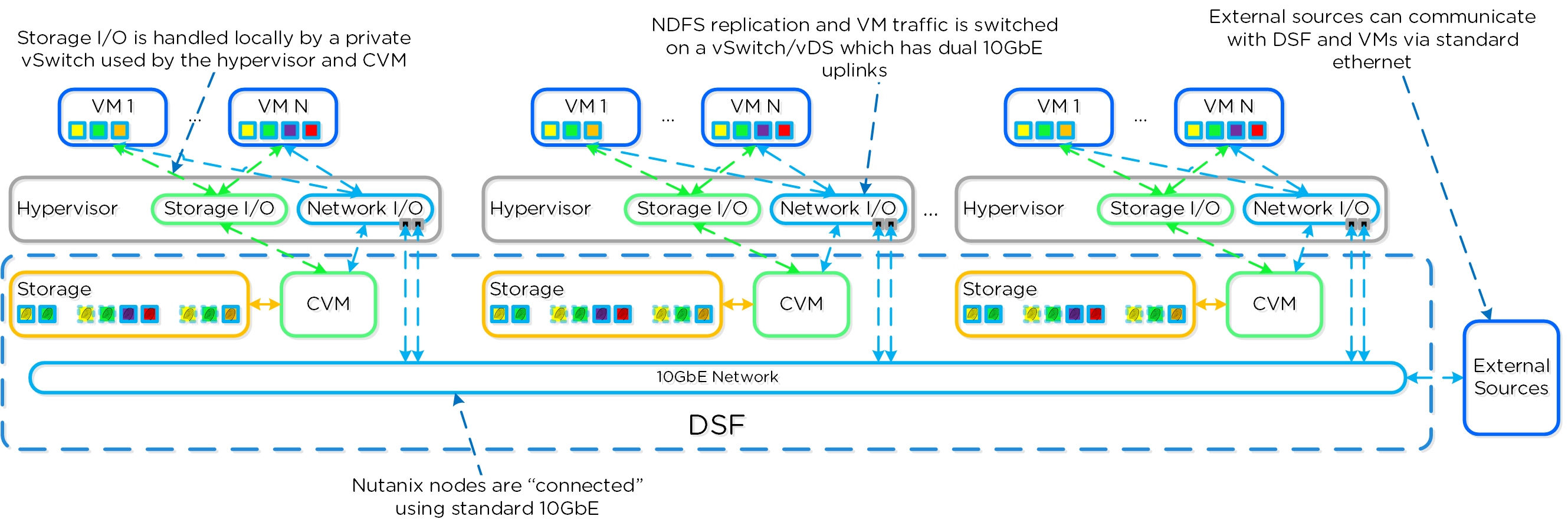
Локальное размещение данных
Краткий рассказ на английском языке доступен по ссылке
Для конвергентной платформы, ввод-вывод и локальное размещение данных является критическими для кластера и производительности ВМ. Как было описано в главе Пути ввода-вывода все операции чтения/записи обслуживаются локальной CVM, которая размещена на каждом гипервизоре и обслуживает ВМ на этих узлах. Данные ВМ обслуживаются локально через CVM и размещаются на локальных дисках под управлением CVM. При перемещении виртуальной машины с одного узла гипервизора на другой (например в случае события HA), недавно перенесенные данные ВМ будут обслуживаться так же - локальной CVM. Когда осуществляется чтение старых данных (хранимых теперь на удаленном узле/CVM), все операции ввод-вывода будут перенаправлены локальной CVM на удаленную. Все операции записи будут выполняться локально. DSF определит, что ввод-вывод происходит с другого узла, и перенесет данные локально в фоновом режиме, позволяя всем операциям чтения обслуживаться локально. Данные будут перенесены только при чтении, чтобы не генерировать дополнительной нагрузки на сеть.
Локальное размещение данных имеет два типа:
-
Локальное размещение кэша
- Данные vDisk хранятся локально в Универсальном кэше. При этом экстенты vDisk могут находится на удаленном узле.
-
Локальное размещение экстентов
- Экстенты vDisk находятся там же, где и сама ВМ
На следующем рисунке показан пример того, как данные будут "следовать" за виртуальной машиной при перемещении между узлами гипервизора:
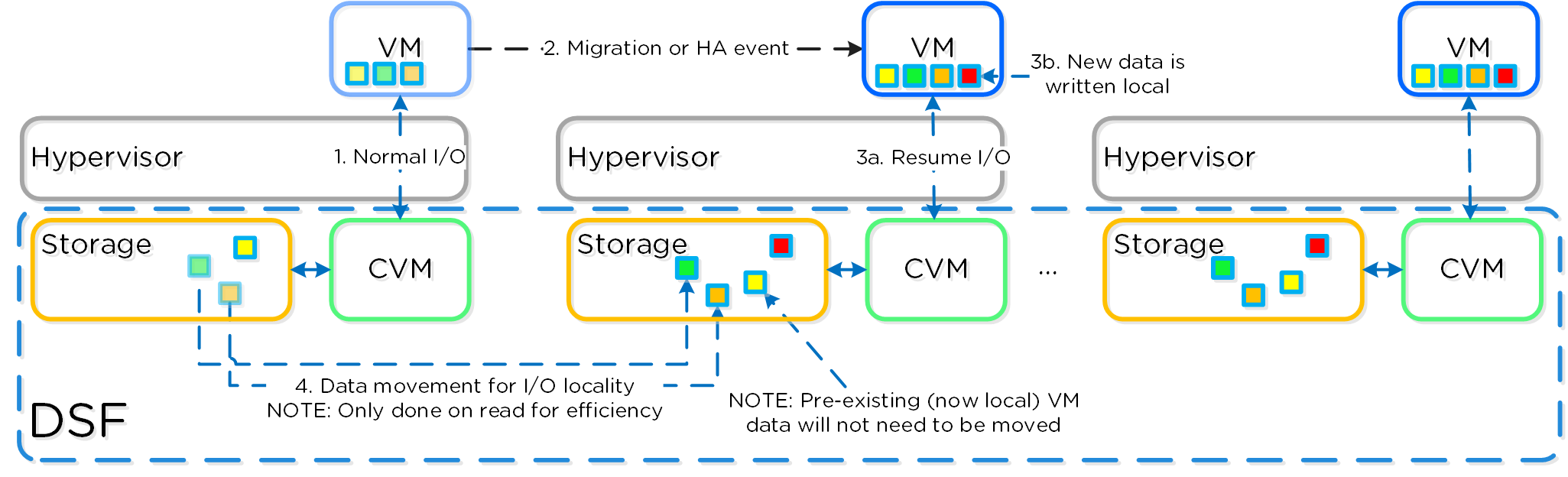
Примечание
Пороговое значение для миграции данных
Локализация кэша происходит в режиме реального времени и определяется на основе данных о владении vDisk. Когда vDisk или ВМ перемещается от одного узла к другому, владельцем vDisk станет новая локальная CVM. После передачи прав новому владельцу - данные можно кэшировать локально в Едином кэше. Кэширование будет выполнятся на текущем владельце ВМ (например на новом удаленном узле). Копия сервиса Stargate который ранее работал с этими данными отдает токен vDisk, когда получает удаленные запросы ввода-вывода 300 или более секунд. Данный токен будет получен локальной копией Stargate. Согласованность кэша обеспечивается по мере необходимости, на стороне текущего владельца данных vDisk.
Локальность экстента является выборочной операцией, и группа экстентов будет перенесена при выполнении следующих действий: "3 запроса для случайных операций ввода-вывода, 10 запросов для последовательных в течении 10 минут, при этом множественные операции чтения каждые 10 секунд считаются как один запрос".
Теневые клоны
Краткий рассказ на английском языке доступен по ссылке
Распределенное хранилище данных Платформы имеет функцию, которая называется ‘Shadow Clones’ / 'Теневые клоны', которая позволяет обеспечить распределенное кэширование конкретных vDisk или ВМ, соответствующих сценарию множественного чтения. Хороший пример - когда для VDI используются слинкованные копии (‘linked clones’), и запросы на чтение передаются основному образу или базовой ВМ. В случае использования VMware View, это называется 'replica disk' и его чтение выполняется при работе со всеми слинкованными копиями, в случае с XenDesktop это называется - MCS Master VM. Этот механизм будет так же использоваться для других сценариев множественного чтения данных (например серверы развертывания, репозитории и так далее.). Данные или локализация ввода-вывода является критическими для достижения максимальной производительности ВМ и является ключевой структурой DSF.
При использовании теневых клонов, DSF будет вести наблюдение за трендами доступа к vDisk, как это делается для локализации данных. Однако, в случае если запросы приходят более чем от двух удаленных CVM (включая локальную CVM), и все эти запросы - запросы на чтение, vDisk будет помечен как неизменяемый. Как только диск будет помечен как неизменяемый, vDisk сможет быть закэширован локально каждой CVM, осуществляющей запросы на чтение (эта копия диска и называется - Теневым клоном). Что позволит направлять все запросы на чтение локально. В случае с VDI, это означает что базовая ВМ будет закеширована на каждом узле и доступ к ней будет осуществляться локально. Примечание: Данные будут перенесены только при чтении, чтобы не забивать сеть и обеспечить эффективное использование кэша. В случае изменения базовой виртуальной машины Теневые копии будут удалены, и процесс начнется заново. Механизм создания теневых копий включен по умолчанию (начиная с версии 4.0.2) и может быть включен/выключен посредством выполнения команды NCLI: ncli cluster edit-params enable-shadow-clones=<true/false>.
На следующем рисунке показан пример работы механизма Теневых клонов и возможности распределенного кэширования:
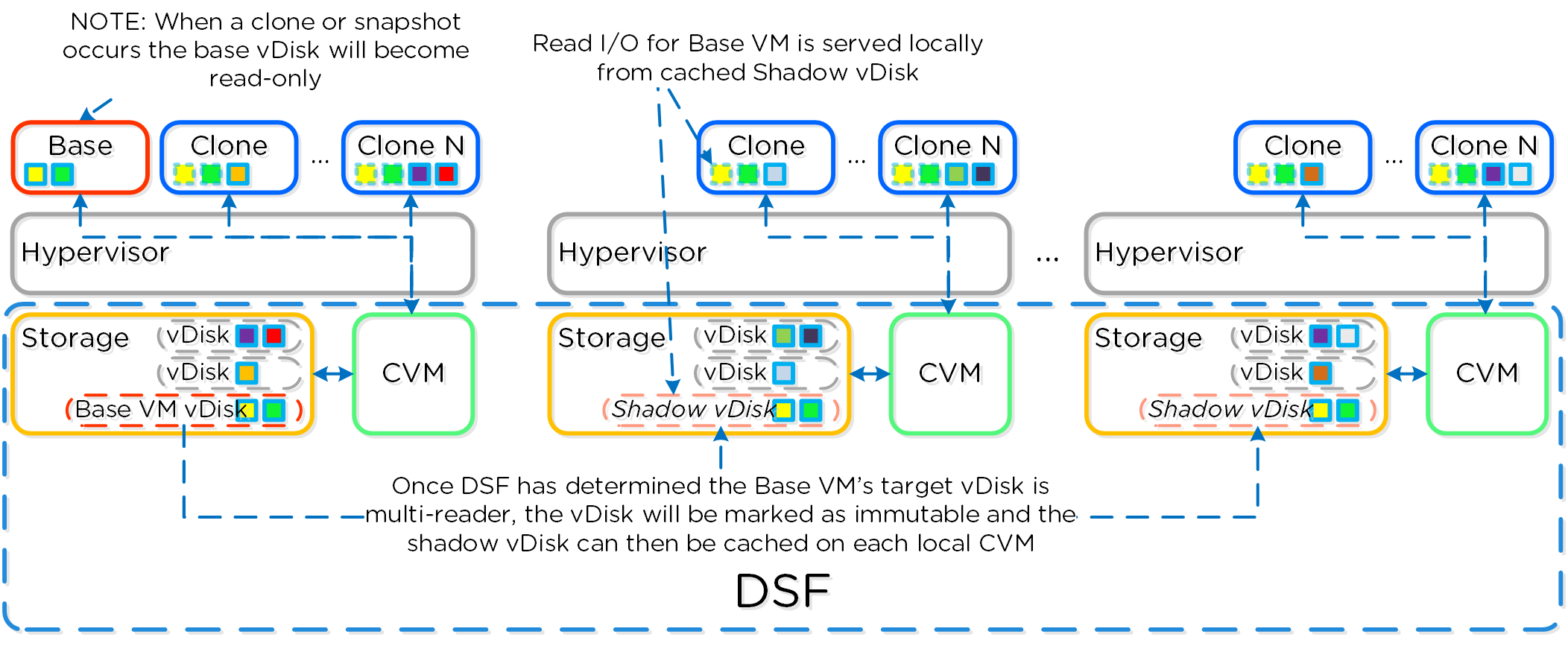
Уровни хранения и мониторинг
Платформа Nutanix выполняет мониторинг хранилища на разные уровнях, начиная с ВМ и гостевых ОС, заканчивая физическими устройствами хранения. Знание этих различных уровней и как они связаны между собой очень важно при работе с платформой, и позволяет лучше понять, что происходит в каждый момент времени. На следующем рисунке показаны различные уровни мониторинга операций с хранилищем:

Уровень виртуальных машин
- Роль: Метрики от гипервизора о виртуальной машине
- Описание: Метрики о ВМ или непосредственно с уровня гостевой ОС, которые напрямую передаются в систему от гипервизора, отображают информацию по производительности ВМ и операций ввода-вывода.
- Когда использовать: При устранении неполадок или поиске сведений об уровне ВМ
Уровень гипервизора
- Роль: Метрики от гипервизора
- Описание: Метрики с уровня гипервизора, передаваемые напрямую с гипервизора. Представляют наиболее точные метрики, отображаемые гипервизорами. Эти данные можно просмотреть для одного или нескольких узлов гипервизора или всего кластера целиком. Этот уровень обеспечит наиболее точные данные с точки зрения производительности платформы и должен быть использован в большинстве случаев. В некоторых сценариях гипервизор может объединять или разделять операции, поступающие от виртуальных машин, что может показать разницу в метриках, сообщаемых виртуальной машиной и гипервизором. Эти цифры также будут включать в себя хиты кэша, обслуживаемых Nutanix CVMs.
- Когда использовать: В большинстве случаев, так как это обеспечит наиболее подробные и ценные показатели.
Уровень контроллера
- Роль: Метрики от CVM
- Описание: Метрики уровня контроллеров которые поступают напрямую от CVM (например, страница Stargate 2009). Предоставляют информацию о фронт-энд операция NFS/SMB/iSCSI и любых бек-энд операциях (например, ILM, балансировка дисков, и пр.). Эти данные можно просмотреть для одной или нескольких виртуальных машин контроллера или кластера целиком. Метрики, которые видит уровень контроллера, обычно должны совпадать с метриками, которые видит уровень гипервизора, однако они будут включать любые бэк-энд операции . Эти цифры также включают и хиты кэша обслуживаемого в памяти. В некоторых случаях метрики (IOPS) могут не совпадать, так как клиент NFS / SMB / iSCSI может разделить большой ввод-вывод на несколько меньших операций ввода-вывода. Однако такие показатели, как пропускная способность, должны совпадать.
- Когда использовать: Подобно слою гипервизора, может использоваться, чтобы показать, сколько и каких бэк-энд операций происходит.
Уровень диска
- Роль: метрики от физических устройств хранения
- Описание: Метрики уровня диска извлекаются непосредственно из физических дисковых устройств (через CVM) и представляют то, что видит серверная часть. Они включают в себя данные, попадающие в OpLog или хранилище экстентов. Все операции, при которых выполняются операции ввода-вывода на диски. Эти данные можно просмотреть для одного из нескольких дисков, дисков для определенного узла или для всех дисков в кластере. В обычных случаях предполагается, что операции на диске должны соответствовать числу входящих операций записи, а также операций чтения, не выполняемых из кэша. Все операции чтения обсуживаемые кэшем не будут учтены, так как они не обслуживаются дисковыми устройствами.
- Когда использовать: Когда нужно понять, как много операций ввода-вывода обслуживаются дисками.
Примечание
Метрики и хранение статистики
Метрики и данные по ним хранятся локально в течение 90 дней в Prism Element. Для Prism Central и Insights, данные могут храниться бесконечно долго (это зависит от доступного пространства).
Сервисы
Гостевые утилиты (NGT)
Гостевые утилиты Nutanix (NGT) это гостевое ПО для размещения на уровне гостевых ОС, которое позволяет получить возможности расширенного управления ВМ через платформу Nutanix.
Решение поставляется в виде инсталлятора NGT который нужно установить на уровне гостевых ОС и фреймфорка Guest Tools который обеспечивает взаимодействие гостевых утилит и платформы.
Установщик NGT состоит из следующих компонент:
- Сервис агентского ПО
- Сервис самостоятельного восстановления (SSR) или восстановления на уровне файлов (FLR) CLI
- Драйверы мобильности - драйверы VirtIO для AHV
- Агент VSS и драйверы для ВМ с Windows
- Поддержка консистентных снимков на уровне приложений для Linux
Эта структура состоит из нескольких высокоуровневых компонентов:
-
Сервис взаимодействия с Гостевыми агентами
- Шлюз между ПО плафтормы Nutanix и Гостевым агентом. ПО распределено между всеми CVM, в качестве мастера выбирается экземпляр, где на текущий момент находится VIP кластера.
-
Гостевой агент
- ПО размещаемое внутри гостевой ОС виртуальной машины. Управляет локальными задачами, такими как VSS или SSR, взаимодействует с Сервисом Гостевых Инструментов
На рисунке показана высокоуровневая схема размещения компонент:
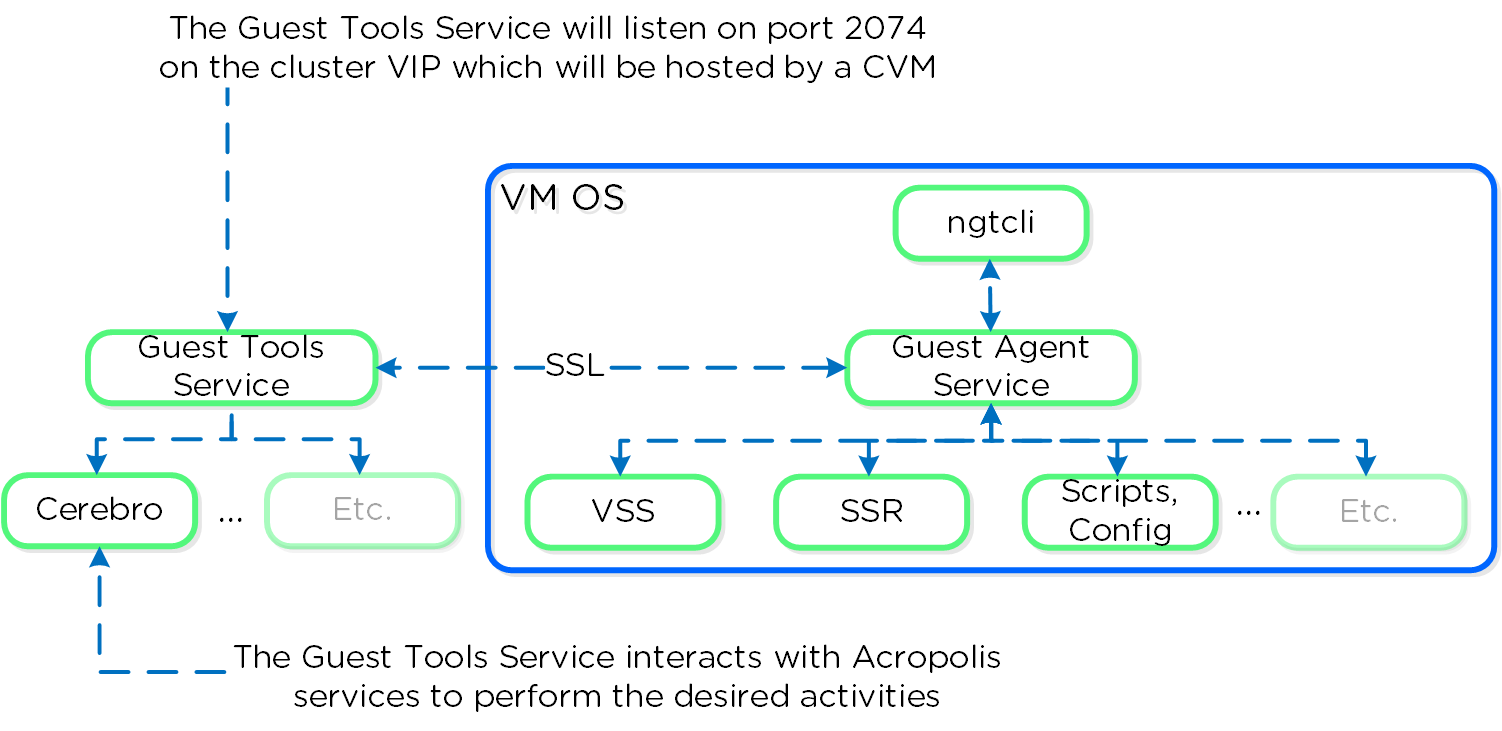
Гостевые утилиты
Сервис взаимодействия с Гостевым агентом (Guest Tools Service) состоит из двух основных компонент:
-
NGT-мастер
- Обслуживает запросы приходящие от NGT-прокси и интерфесов ПО Acropolis. NGT-мастер выбирается динамически среди узлов кластера, в случае отказа текущего мастера - выбирается новый. Сервис слушает внутренний порт 2073.
-
NGT-прокси
- Запускается на всех CVM и перенаправляет запросы к NGT-мастеру для выполнения желаемых действий. Текущая CVM работающая в режиме Prism Leader (там, где VIP) будет обрабатывать все запросы от Гостевых утилит. Сервис слушает внешний порт 2074.
Примечание
Текущий NGT-мастер
Вы можете определить IP-адрес CVM, на которой расположен сервис NGT-мастер, выполнив следующую команду на любой CVM:
nutanix_guest_tools_cli get_master_location
Размещение ролей показано на изображении ниже:
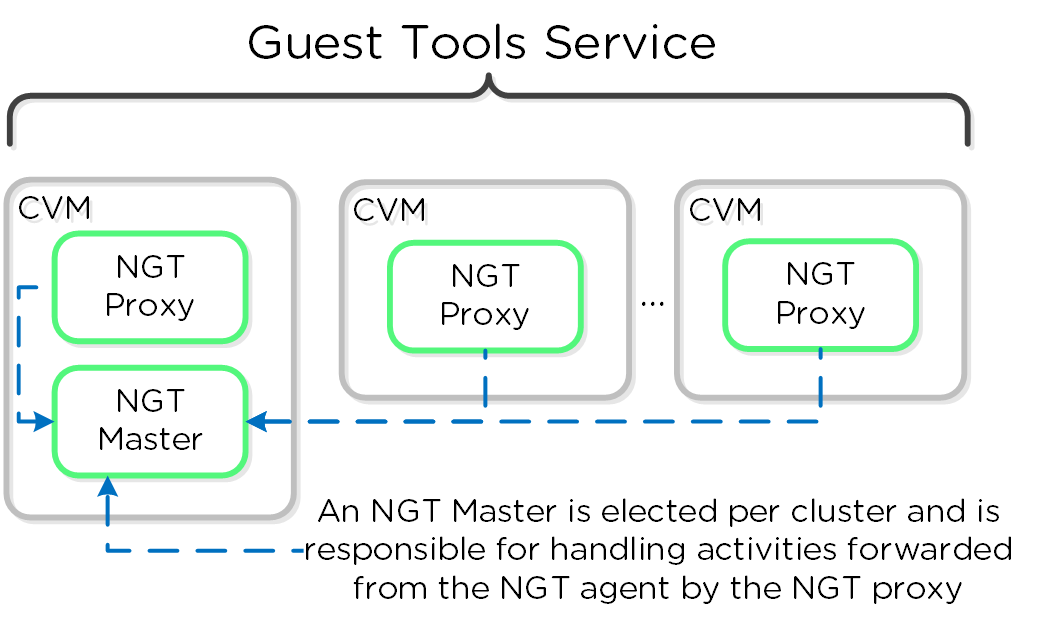
Гостевой агент
Гостевой агент состоит из следующих высокоуровневых компонентов, как упоминалось выше:
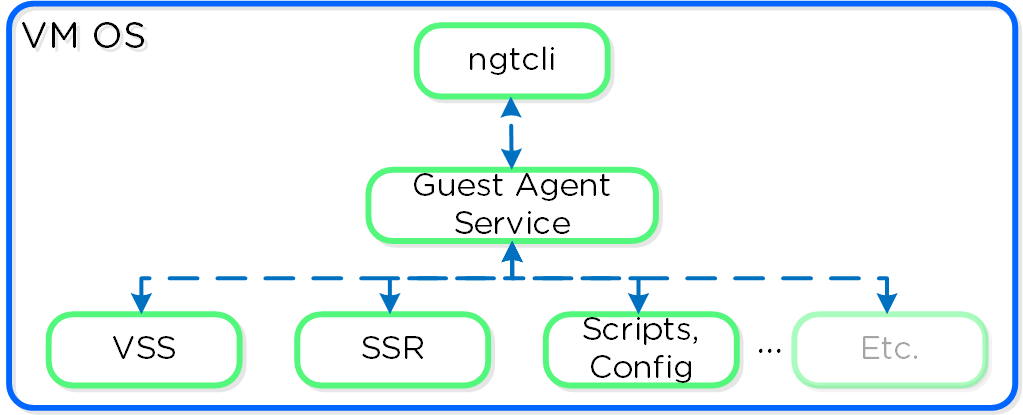
Связь и безопасность
Взаимодействие Гостевых агентов и Сервиса взаимодействия с Гостевыми агентами осуществляется через IP-адрес кластера с использованием SSL. Для инсталляций, где компоненты кластера Nutanix и пользовательские ВМ находятся в разных сетях, убедитесь, что возможно следующее:
- Убедитесь, что работает маршрутизация из сетей ВМ к адресу кластера или
- Создайте правило межсетевого экрана (NAT), обеспечивающее доступ для клиентских ВМ к IP-адресу кластера на порт 2074.
Сервис взаимодействия с Гостевыми агентами выступает в роли удостоверяющего центра (CA) и отвечает за создание пар сертификатов для каждой ВМ с установленным Гостевым агентом. Сертификат интегрируется в образ ISO, и подключается к ВМ. Далее он используется в процессе инсталляции Гостевого агента.
Установка NGT-агента
Установка NGT-агента может быть выпролнена через Prism или CLI/Scripts (ncli/REST/PowerShell).
Для инсталляции через Prism, нужно перейти на страницу 'VM', выбрать нужную ВМ и нажать кнопку 'Enable NGT':
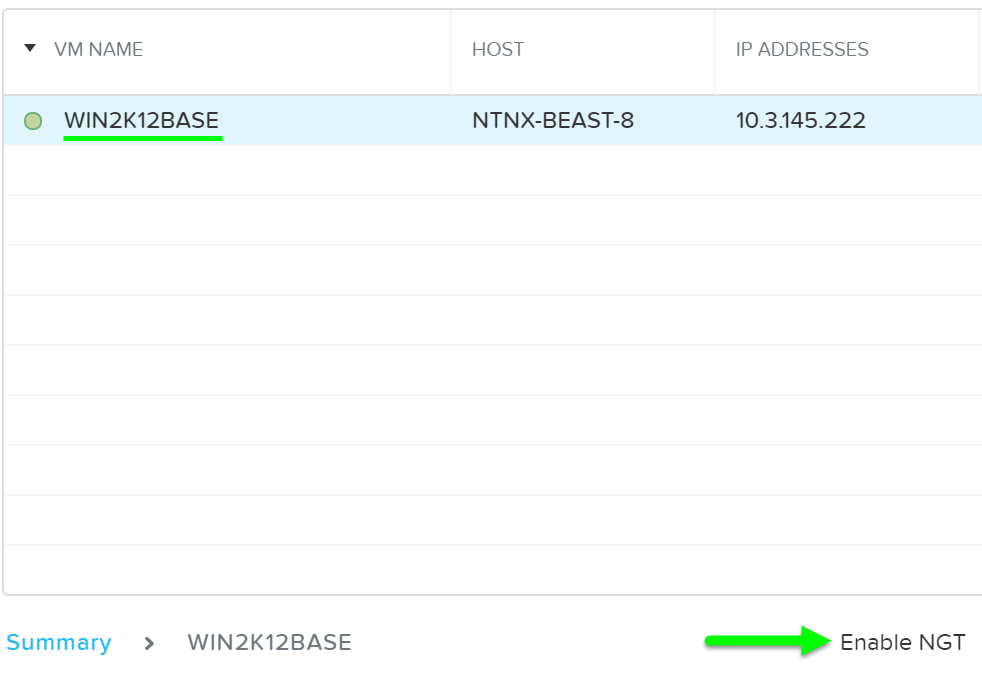
Нажмите 'Yes' для начала инсталляции NGT:
ВМ должна иметь CD-ROM, куда может быть подключен сгенерированный инсталлятором ISO образ, содержащий уникальные сертификаты:
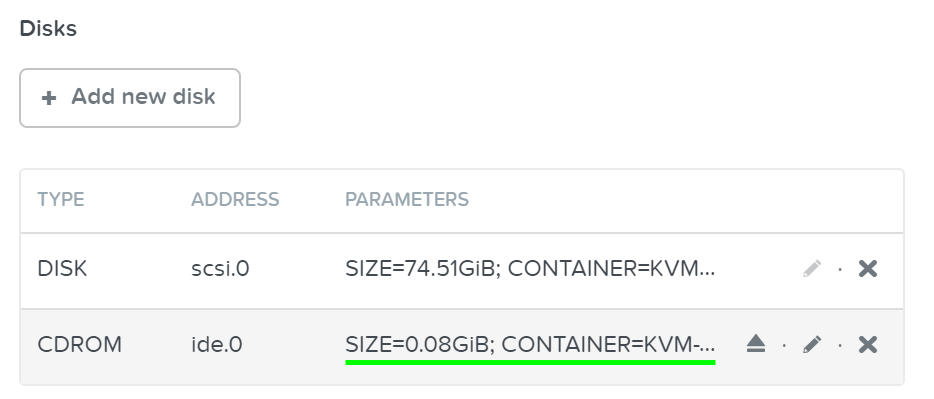
Данный ISO будет виден на уровне гостевой ОС:

Нажмите дважды на CD, чтобы начать установку ПО.
Примечание
Фоновая инсталляция
Вы можете выполнить фоновую инсталляцию запустив следующую команду (из точки монтирования CD-ROM):
NutanixGuestTools.exe /quiet /l log.txt ACCEPTEULA=yes
Следуйте по шагам мастера инсталляции и примите лицензионное соглашение:
Как часть ПО будут так же установлены Python, PyWin и драйверы Nutanix Mobility.
После завершения установки требуется выполнить перезагрузку.
После успешной установки и перезагрузки, вы увидите следующие элементы в 'Programs and Features':
Сервис отвечающий за NGT-агента и VSS Hardware Provider будут так же запущены:
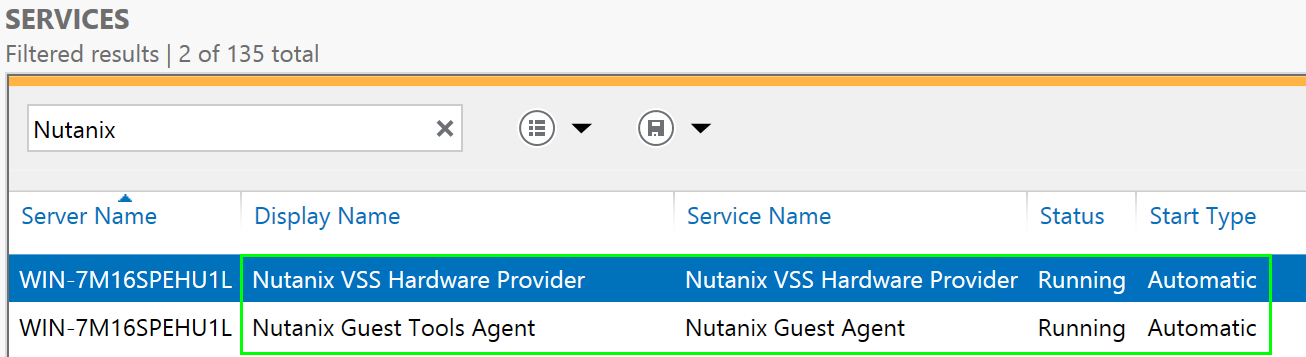
NGT установлен и может быть использован.
Примечание
Массовая установка NGT
Вместо установки NGT для каждой машины отдельно, можно выполнить интеграцию ПО прямо в базовый образ ВМ.
Выполните следующие действия для установки NGT в базовый образ ВМ:
- Установите NGT в базовую ВМ и обеспечьте связь
- Склонируйте новую ВМ из базовой ВМ
-
Смонтируйте ISO образ NGT к каждому клону (требуется для генерации пар сертификатов)
- Например: ncli ngt mount vm-id=<CLONE_ID> или через Prism
- Скоро мы предоставим автоматизированный способ инсталляции :)
- Включите клоны ВМ
Когда склонированная виртуальная машина будет загружена, она найдет ISO NGT и скопирует соответствующие файлы конфигурации и новые сертификаты, а затем начнет взаимодействовать с Сервисом взаимодействия с Гостевыми агентами.
Настройка параметров OS
Nutanix поддерживает настройку параметров ОС через утилиты CloudInit и Sysprep. CloudInit используется для первичной настройки серверов с Linux при старте ВМ. Sysprep используется для первоначальной настройки ОС Windows.
Некоторые типичные области применения:
- Настройка имени узла
- Установка пакетов
- Добавление пользователей / управление ключами
- Запуск пользовательских скриптов автоматизации
Поддерживаемые конфигурации
Решение применимо к гостевым ОС семейства Linux , включая версии перечисленные ниже:
-
Гипервизоры:
- AHV
-
Операционные системы:
- Linux - Большинство современных дистрибутивов
- Windows - Большинство современных дистрибутивов
Пререквизиты
Для использования CloudInit необходимо:
- Пакет CloudInit должен быть установлен в гостевую ОС
Sysprep доступен в Windows по умолчанию
Установка пакета
CloudInit может быть установлен следующим образом:
Для ОС на базе Red Hat (CentOS, RHEL)
yum -y install CloudInit
Для ОС на базе Debian (Ubuntu)
apt-get -y update; apt-get -y install CloudInit
Sysprep является частью базовой инсталляции ОС Windows.
Настройка образа
Добавление пользовательского скрипта настройки ОС может быть выполнено через Prism или REST API. Эта опция становится доступной при создании или клонировании ВМ:
Путь к пользовательскому скрипту может быть указан несколькими способами:
-
Путь на хранилище ADSF
- Использование ранее загруженного файла
-
Загрузка файла
- Загрузка файла, который будет выполнен
-
Набор или вставка текста скрипта
- Скрипт CloudInit или содержимое Unattend.xml
Nutanix передает пользовательский скрипт в CloudInit или Sysprep, он будет выполнен при первом старте ВМ. Для этого формируется ISO с данным скриптом, которой в последующем подключается в гостевой ОС. После выполнения скрипта данный ISO будет отключен.
Форматирование ввода
Платформа поддерживает широкий перечень форматов для пользовательских сценариев автоматизации. Давайте перечислим некоторые варианты.
Пользовательский скрипт (CloudInit - Linux)
Пользовательский скрипт который будет выполняться в конце процесса загрузки ОС (а-ля "rc.local-like").
Скрипт будет начинаться как любой сценарий bash: "#!".
Ниже приведен пример простого скрипта:
#!/bin/bash touch /tmp/fooTest mkdir /tmp/barFolder
Подключаемый файл (CloudInit - Linux)
Подключаемый файл содержит URL адреса файлов. Каждый доступный файл будет выполнен так же, как это делается для Пользовательских скриптов.
Скрипт будет начинаться с: "#include".
Ниже показан пример такого скрипта:
#include http://s3.amazonaws.com/path/to/script/1 http://s3.amazonaws.com/path/to/script/2
Сценарий cloud-config (CloudInit - Linux)
Сценарии cloud-config наиболее распространенный тип сценариев, специфичный для утилиты CloudInit.
Скрипт должен начинаться с: "#cloud-config"
Ниже показан пример такого скрипта:
#cloud-config # Установить имя ВМ hostname: foobar # Добавить пользователей users: - name: nutanix sudo: ['ALL=(ALL) NOPASSWD:ALL'] ssh-authorized-keys: - ssh-rsa: <PUB KEY> lock-passwd: false passwd: <PASSWORD> # Автоматически обновить все пакеты package_upgrade: true package_reboot_if_required: true # Инсталляция LAMP packages: - httpd - mariadb-server - php - php-pear - php-mysql # Затем выполнить команду runcmd: - systemctl enable httpd
Примечание
Проверка выполнения CloudInit
Журнал CloudInit находится тут /var/log/cloud-init.log and cloud-init-output.log.
Unattend.xml (Sysprep - Windows)
Файл unattend.xml который использует Sysprep для настройки образа при первом старте, подробнее можно почитать : тут
Скрипт будет начинаться с: "<?xml version="1.0" ?>".
Пример содержания файла unattend.xml:
<?xml version="1.0" ?> <unattend xmlns="urn:schemas-microsoft-com:unattend"> <settings pass="windowsPE"> <component name="Microsoft-Windows-Setup" publicKeyToken="31bf3856ad364e35" language="neutral" versionScope="nonSxS" processorArchitecture="x86"> <WindowsDeploymentServices> <Login> <WillShowUI>OnError</WillShowUI> <Credentials> <Username>username</Username> <Domain>Fabrikam.com</Domain> <Password>my_password</Password> </Credentials> </Login> <ImageSelection> <WillShowUI>OnError</WillShowUI> <InstallImage> <ImageName>Windows Vista with Office</ImageName> <ImageGroup>ImageGroup1</ImageGroup> <Filename>Install.wim</Filename> </InstallImage> <InstallTo> <DiskID>0</DiskID> <PartitionID>1</PartitionID> </InstallTo> </ImageSelection> </WindowsDeploymentServices> <DiskConfiguration> <WillShowUI>OnError</WillShowUI> <Disk> <DiskID>0</DiskID> <WillWipeDisk>false</WillWipeDisk> <ModifyPartitions> <ModifyPartition> <Order>1</Order> <PartitionID>1</PartitionID> <Letter>C</Letter> <Label>TestOS</Label> <Format>NTFS</Format> <Active>true</Active> <Extend>false</Extend> </ModifyPartition> </ModifyPartitions> </Disk> </DiskConfiguration> </component> <component name="Microsoft-Windows-International-Core-WinPE" publicKeyToken="31bf3856ad364e35" language="neutral" versionScope="nonSxS" processorArchitecture="x86"> <SetupUILanguage> <WillShowUI>OnError</WillShowUI> <UILanguage>en-US</UILanguage> </SetupUILanguage> <UILanguage>en-US</UILanguage> </component> </settings> </unattend>
Блочные сервисы
Функция платформы - Acropolis Block Services (ABS) предоставляет хранилище внешним клиентам (гостевым ОС, физическим узлам, контейнерам, и так далее.) через iSCSI.
Это позволяет любой ОС получить доступ к хранилищу и воспользоваться его преимуществами. При таком использовании хранилища взаимодействие с ним происходит напрямую, без использования гипервизора.
Основные варианты использования ABS:
- Общие разделы
- Oracle RAC, Microsoft Failover Clustering и т.д.
- Диски как таковые
- Когда данные являются критичными, а контекст (ВМ/контейнер) не является постоянными
- Контейнеры, OpenStack, и так далее.
- Предоставление iSCSI
- Аппаратные узлы
- Развернутый на vSphere продукт Exchange (для поддержки компанией Microsoft)
Поддерживаемые ОС
Решение соответствует спецификации iSCSI, поддерживаемыми являются те ОС, которые были проверены QA.
- Microsoft Windows Server 2008 R2, 2012 R2
- Redhat Enterprise Linux 6.0+
Компоненты Блочных сервисов
Следующие компоненты представляют собой Acropolis Block Services:
- Data Services IP:IP-адрес используемый для подключения iSCSI (Начиная с версии 4.7)
- Volume Group: Группа томов для которых может выполняться централизованное управление, создание снимков, и применение политик
- Disk(s): Устройства собираемые в группы (видны как LUN для iSCSI-таргета)
- Attachment: Обеспечивает привязку и доступ для конкретного IQN к группе томов
- Secret(s): Используется для аутентификации CHAP/Mutual CHAP
Примечание: Группы томов - не что иное как обычный vDisk на РХД.
Пререквизиты
Прежде чем заниматься конфигурацией мы должны настроить IP-адрес, через который будет осуществляться подключение томов и аутентификация iSCSI-таргета.
Данный адрес настраивается на странице 'Cluster Details' (Иконка с шестеренкой -> Cluster Details):
Так же это можно настроить и через NCLI / API:
ncli cluster edit-params external-data- services-ip-address=<DATA SERVICES IP ADDRESS>
Создание iSCSI-таргета
Для использования Блочных сервисов, первое, что мы сделаем, это создадим "группу томов", которая является iSCSI-таргетом.
На странице 'Storage' нажмите на кнопку '+ Volume Group' в правом углу:
Откроется меню для детальной настройки группы томов:
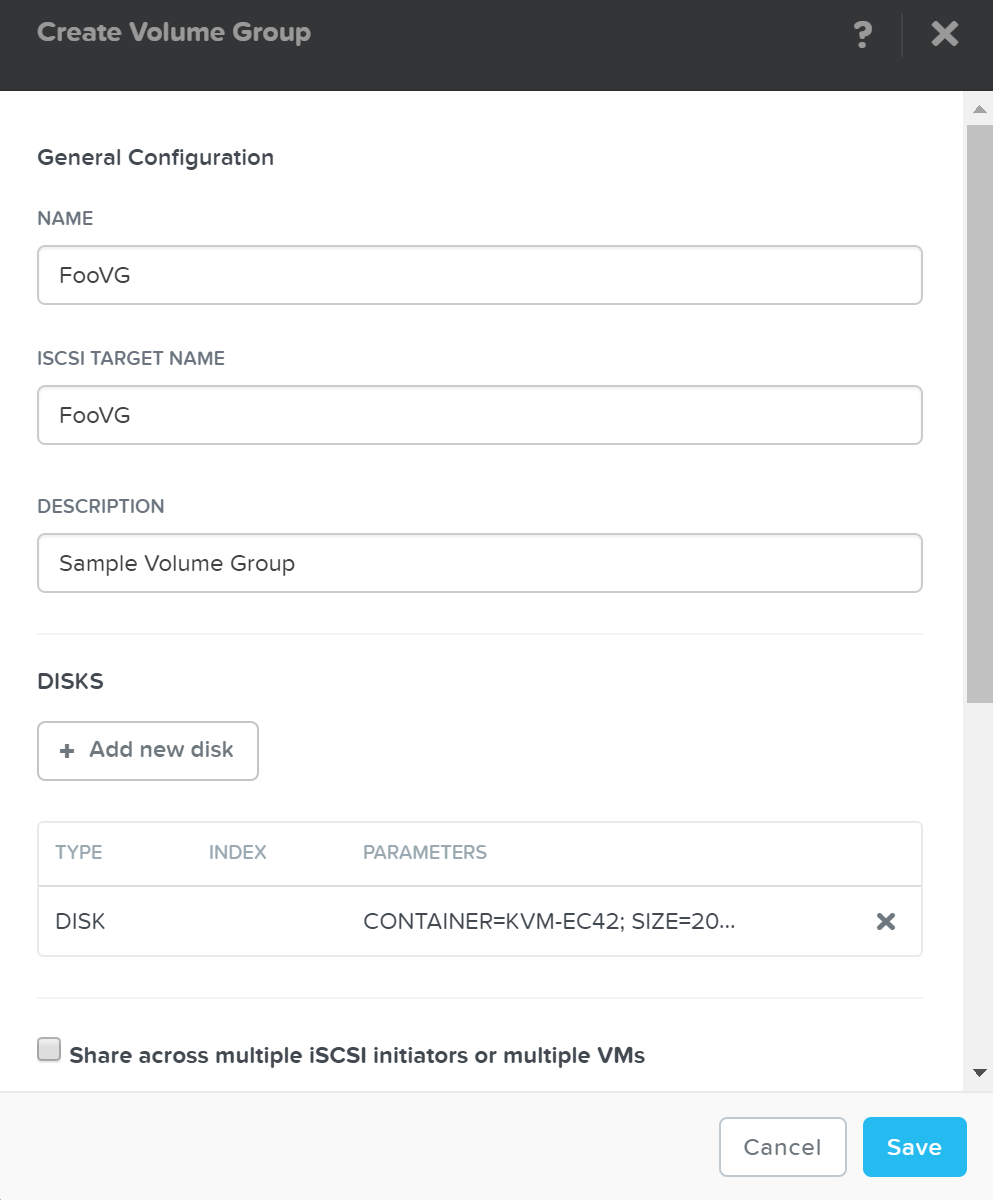
Далее нужно нажать на кнопку '+ Add new disk' для добавления дисков к iSCSI-таргету (будут видны как тома - LUN:
В появившемся меню нужно выбрать контейнер, где будет расположен создаваемый том и указать размер тома/диска:
Далее - нажать 'Add' и повторить действия столько раз, сколько дисков нужно создать.
После того, как мы указали детали и добавили диски, мы подключим группу томов к виртуальной машине или инициатору IQN. Это позволит дать ВМ доступ к iSCSI-таргету (запросы от неизвестных инициаторов будут отклонены):
Нажмите 'Save'. Настройка группы томов закончена!
Все эти действия могут быть выполнены через ACLI / API:
# Создание группы томов
vg.create <VG Name>
# Добавление дисков в группу томов
Vg.disk_create <VG Name> container=<CTR Name> create_size=<Disk size, e.g. 500G>
# Подключение IQN инициатора к группе томов
Vg.attach_external <VG Name> <Initiator IQN>
Высокая доступность (HA)
Как говорилось ранее, адрес сервиса iSCSI (Data Services IP) используется для обнаружения. Это позволяет использовать единственный адрес, вместо того, чтобы указывать адрес какой-то отдельной CVM.
IP адрес Блочных сервисов будет назначен текущему мастеру iSCSI. Это позволяет убедиться, что портал обнаружения всегда доступен.
При конфигурации iSCSI-инициатора указывается IP-адрес сервиса iSCSI (Data Services IP). По запросу на подключение платформа выполнит перенаправление запроса iSCSI на активный сервис Stargate.
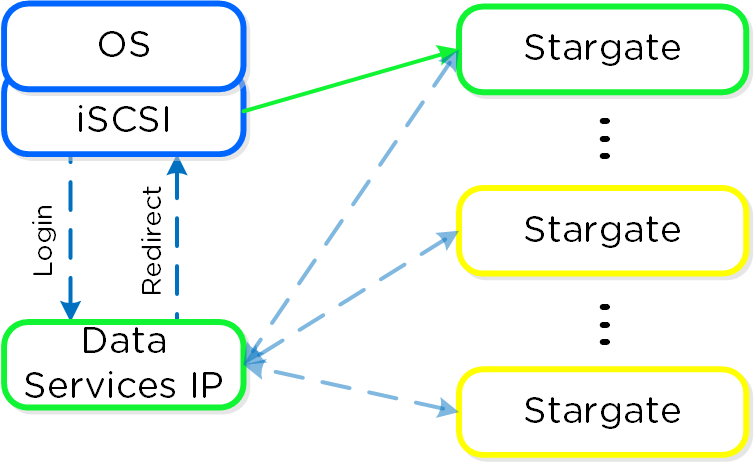
В случае, когда активный сервис Stargate падает, инициатор пытается снова осуществить подключение к iSCSI через Data Services IP, и его зарос будет перенаправлен к рабочей копии Stargate.
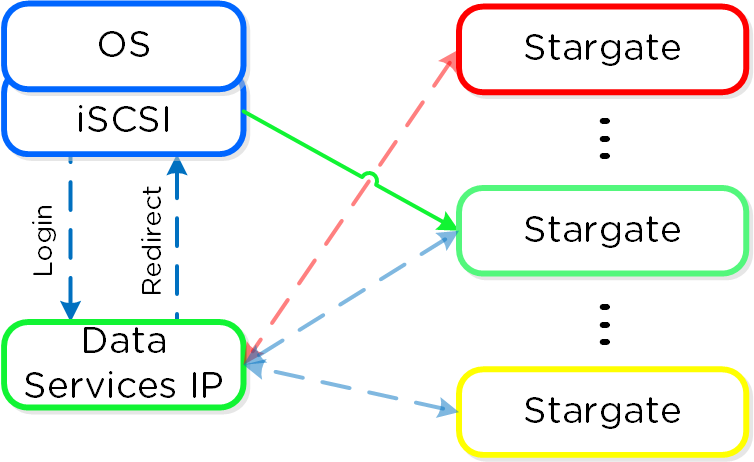
Если ранее упавший сервис Stargate восстанавливается, текущий активный Stargate заморозит I/O и сбросит активные сессии iSCSI. Когда инициатор снова попробует подключиться к iSCSI-таргету, запрос будет перенаправлен к восстановленному сервису Stargate.
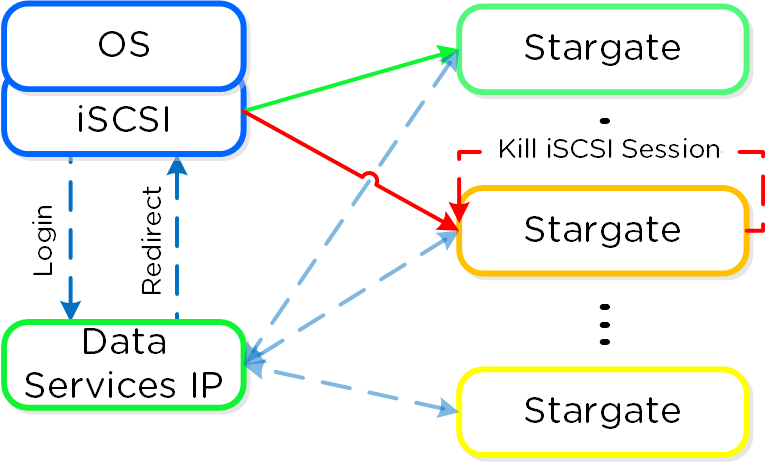
Примечание
Мониторинг работоспособности и значения по умолчанию
При работе с Блочными сервисами состояние Stargate определяется сервисом Zookeeper, т.е. по тому же механизму что и для РХД в целом.
Стандартный интервал для восстановления - 120 секунд. Это значит, что если восстановленный сервис Stargate проработает более 2х минут - платформа выполнит заморозку I/O и переключит клиентов iSCSI. Как это описано чуть выше.
Используя этот механизм можно исключить необходимость настраивать на клиенте MPIO для обеспечения HA. Когда инициатор подключается к iSCSI-таргету можно не ставить галку 'Enable multi-path':
Multi-Pathing
Протокол iSCSI подразумевает одну сессию iSCSI между iSCSI-инициатором и iSCSI-таргетом. Это значит, что мы имеем отношения один-к-одному между iSCSI-таргетом и Stargate.
Начиная с версии ПО 4.7, по умолчанию 32 виртуальных iSCSI-таргета будут автоматически созданы для каждого инициатора и присвоены для каждого диска добавленного в группу томов. Таким образом обеспечивается iSCSI-таргетом на каждый диск. Ранее создавалось несколько групп томов с одним диском каждая.
Если посмотреть в детальные настройки группы томов через ACLI/API можно увидеть параметр определяющий 32 виртуальных таргета для каждого подключения:
attachment_list { external_initiator_name: "iqn.1991-05.com.microsoft:desktop-foo" target_params { num_virtual_targets: 32 } }
Для примера создадим группу томов содержащую в себе три диска. При выполнении обнаружения на стороне клиента видно отдельного таргета для каждого диска (суффикс в формате '-tgt[int]'):
Так для каждого диска создается собственная сессия iSCSI и появляется возможность распределять сессии iSCSI между разными сервисами Stargates, увеличивая масштабируемость и производительность:
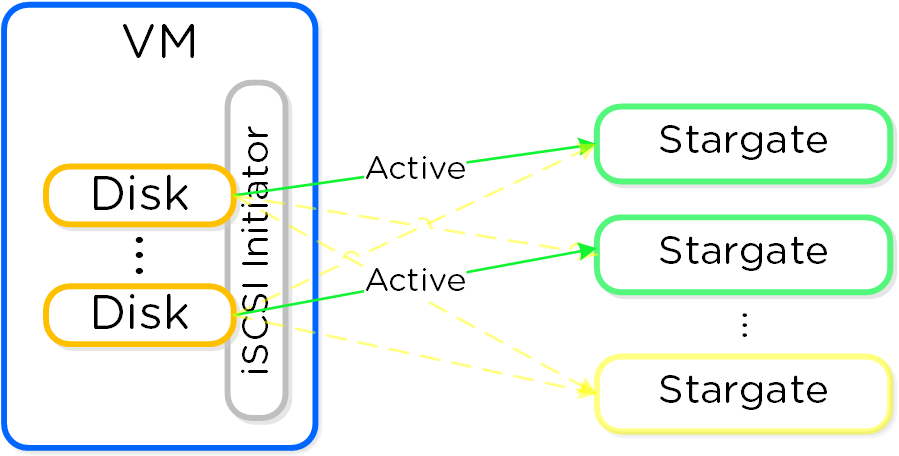
Балансировка нагрузки происходит во время установки сеанса iSCSI (вход в систему iSCSI) для каждого таргета.
Примечание
Активные пути
Вы можете посмотреть активные сервисы Stargate на которых находятся виртуальные iSCSI-таргеты выполнив команду:
# Windows
Get-NetTCPConnection -State Established -RemotePort 3205
# Linux
iscsiadm -m session -P 1
С версии 4.7 используется простая хэш-функция для распределения таргетов между узлами кластера. В версии 5.0 эта функция интергирована в Acropolis Dynamic Scheduler, который выполняет ребалансировку сессий, если это необходимо. Мы продолжим поиски алгоритмов, которые позволят нам добиться больше оптимизации процессов. Также можно установить предпочтительный узел, который будет использоваться, пока он находится в работоспособном состоянии.
Примечание
SCSI UNMAP (TRIM)
ABS поддерживает команды SCSI UNMAP (TRIM), согласно спецификации T10. Эта команда используется для освобождения емкости, при удалении блоков.
Файловые сервисы
Файловые сервисы позволяют пользователю использовать платформу Nutanix в качестве отказоустойчивого файлового сервера. Предоставляется доступ в единое пространство имен, где пользователи могут размещать свои домашние каталоги и файлы.
Поддерживаемые конфигурации
Данные сервисы могут работать на платформах следующим конфигурациям:
-
Гипервизоры:
- AHV
- ESXi (Asterix и далее)
-
Файловые протоколы:
- CIFS 2.1
-
Совместимые функции:
- Async-DR
Компоненты файловых сервисов
Функция состоит из следующих высокоуровневых компонент:
-
Файловый сервер
- Высокоуровневое пространство имен. Каждый файловый сервер будем иметь свой набор File Services VMs (FSVM)
-
Общая папка
- Общая папка доступна пользователям. Каждый файловый сервер может иметь по несколько таких папок (e.g. например - общая папка отдела)
-
Папка
- Папка для хранения файлов. Папки являются общими для FSVM
На рисунке показана высокоуровневая схема данного сервиса:
Файловые сервисы следуют такой же методологии распределенности как и вся платформа Nutanix, для обеспечения отказоуствойчивости и масштабирования. Минимум 3 FSVM будут запущены как часть файловых сервисов.
На рисунке показана подробная схема компонентов данного сервиса:
Примечание
Поддерживаемые протоколы
С версии 4.6, SMB (до версии 2.1) единственный поддерживаемый протокол для взаимодействия клиентов и сервера.
ВМ обеспечивающие файловые сервисы запускаются в процессе конфигурации сервисов.
На рисунке показана схема размещения FSVMs на платформе:
Аутентификация и авторизация
Файловые сервисы полностью интегрированы с Microsoft Active Directory (AD) и DNS. Это позволяет использовать все возможности по аутентификации и авторизации присущие AD. Все настройки разрешений на файлы, управление пользователями или группами выполняется с использованием Windows MMC.
Следующие объекты AD/DNS будут созданы в процессе инсталляции:
- Аккаунт компьютера для AD для файлового сервера
- AD SPN для файлового сервера и каждой FSVM
- DNS запись для файлового сервера указывающая на все FSVM
- DNS записи для каждой FSVM
Примечание
Разрешения AD на создание файлового сервиса
Пользовательский аккаунт с правами администратора домена или эквивалентными должен использоваться для создания файлового сервиса и объектов AD и DNS.
Высокая доступность (HA)
Каждая FSVM использует API платформы для работы с дисками, для работы с хранилищем через iSCSI на уровне гостевой ОС. Это позволяет каждой FSVM подключаться к любому iSCSI-таргету, что полезно при отказе FSVM.
На рисунке показана схема работы FSVM с хранилищем:
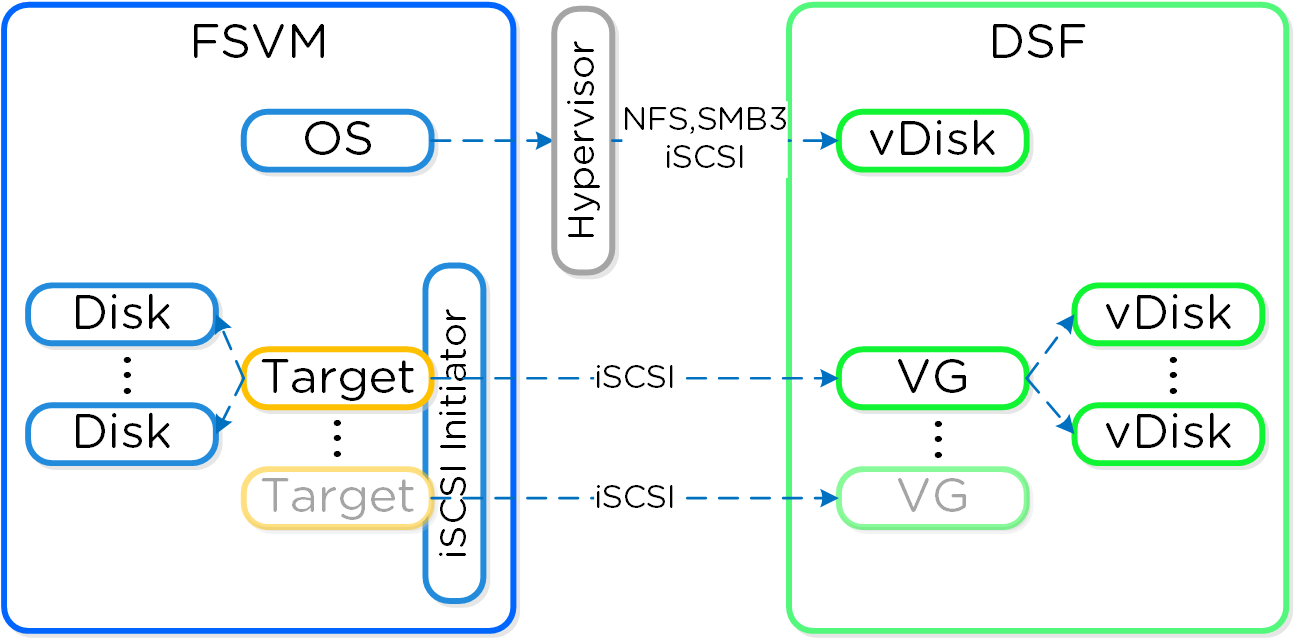
Для обеспечения доступности путей используется DM-MPIO. При этом активный путь - локальный:
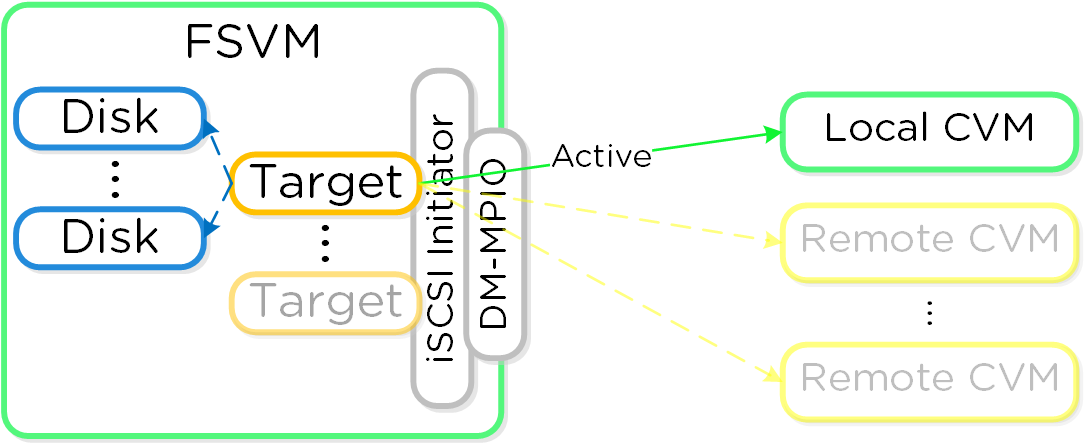
В случае отказа локальной CVM, DM-MPIO активирует один из путей к удаленной CVM, которая обеспечит дальнейшие IO.
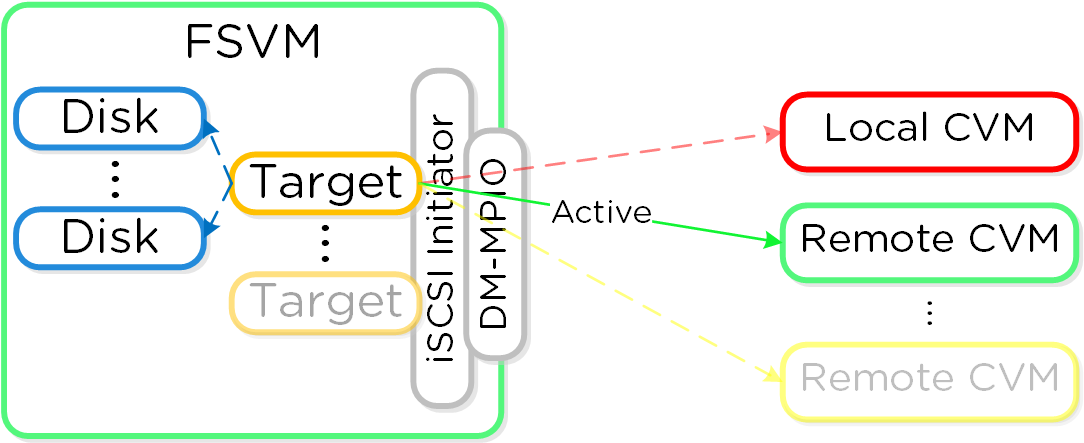
Когда локальная CVM восстанавливается, локальный путь снова активируется и операции ввода-вывода становятся локальными.
При нормальной работе, каждая FSVM будет взаимодействовать с ее собственной группой томов для хранения данных и держать пассивное подключение к другим группам. Каждая FSVM будет иметь IP к которому будут подключаться клиенты. Клиентам не нужно знать конкретный адрес каждой FSVM, DFS перенаправит их подключение к нужной FSVM, которая обслуживает их папки.
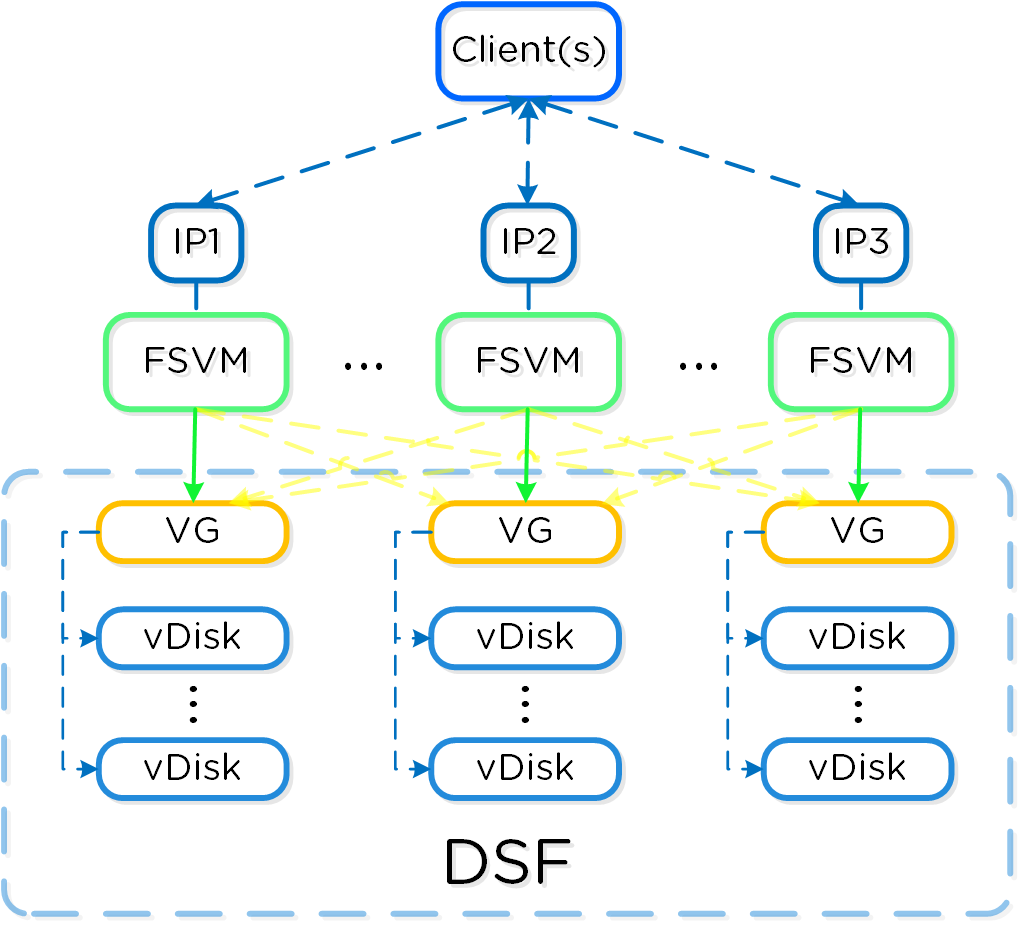
В случае отказа FSVM группа томов и ее IP будут временно переданы работоспособный FSVM для бесперебойной работы сервиса.
На рисунке показана схема передачи IP адреса FSVM и группы томов:
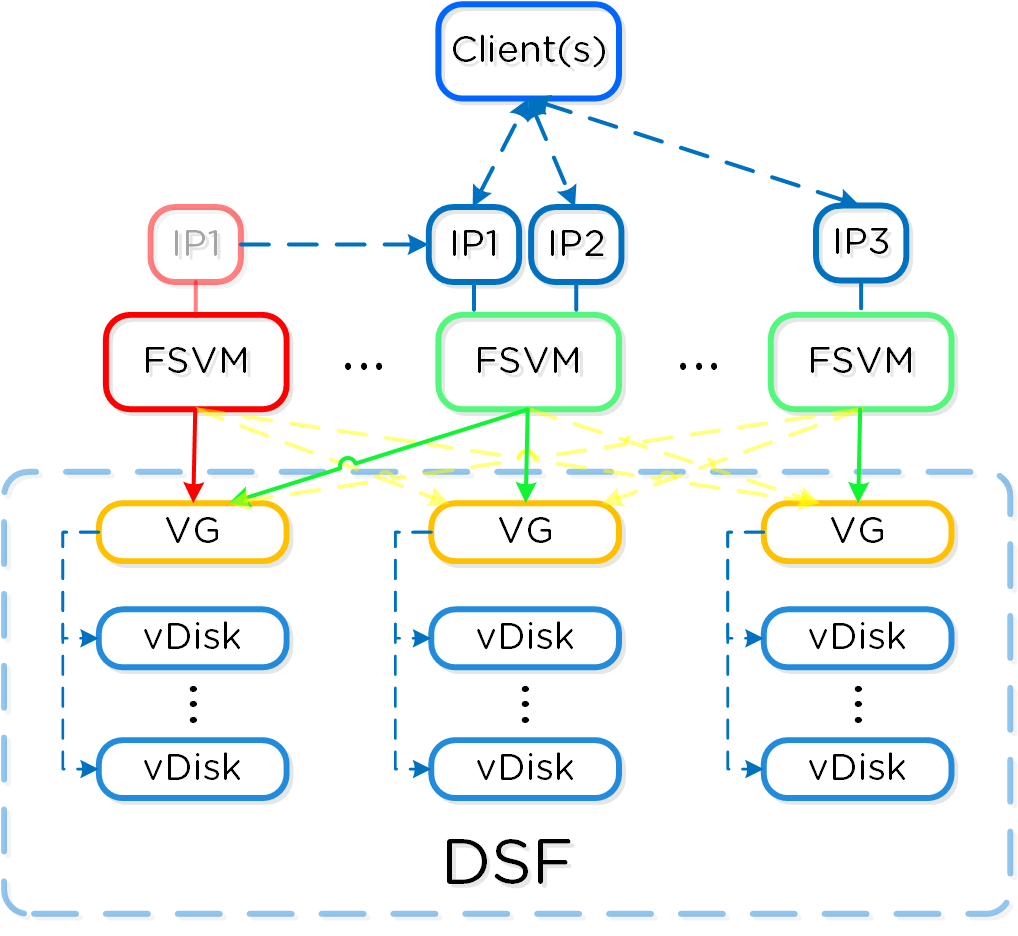
Когда отказавшая FSVM вернется в рабочее состояние она снова получит свой IP адрес и папки, начнет обрабатывать запросы клиента.
Служба Контейнеров
Платформа Nutanix предоставляет возможность управления персистентными контейнерами на базе Docker. Ранее имелась возможность запуска Docker на платформе Nutanix, однако персистентность данных была проблемой, учитывая эфемерную природу контейнеров.
Контейнерные технологии, такие как Docker-это другой подход к виртуализации оборудования. При традиционной виртуализации каждая виртуальная машина имеет собственную операционную систему (ОС), но использует общее оборудование. Контейнеры, которые включают в себя приложения и их зависимости, запускаются как изолированные процессы которые используют одно и то же ядро ОС.
В следующей таблице показано простое сравнение виртуальных машин и контейнеров:
| Метрики | ВМ | Контейнеры |
|---|---|---|
| Тип виртуализации | Виртуализация аппаратного обеспечения | Виртуализация ядра ОС |
| Перерасход | Тяжелый | Легкий |
| Скорость подготовки | Медленнее (секунды или минуты) | Быстрее / в реальном времени (мкс или мс) |
| Накладные расходы | Ограниченная производительность | Нативная производительность |
| Безопасность | Полностью изолированные (более безопасно) | Изолированны на уровне процессов (менее безопасно) |
Поддерживаемая конфигурация
Решение применимо к следующим конфигурациям:
-
Гипервизор:
- AHV
-
Система контейнеризации*:
- Docker 1.13
*начиная с версии 4.7, решение поддерживает интеграцию хранилища только с контейнерами Docker. Однако вы можете разместить любую другую систему контейнеризации в рамках ВМ на платформе.
Конструкции службы Контейнеров
Следующие элементы составляют службы контейнеров Acropolis:
- Nutanix Docker Machine Driver: Управляет созданием узлов через Docker Machine и Сервис образов Acropolis.
- Nutanix Docker Volume Plugin: Отвечает за взаимодействие Блочного сервиса для создания, монтирования, форматирования и подключения томов к контейнерам.
Следующие элементы составляют Docker (Примечание: не обязательно использовать все):
- Docker Image: Образ контейнера
- Docker Registry: Хранилище образов контейнеров
- Docker Hub: Публичное хранилище образов контейнеров
- Docker File: Текстовый файл, описывающий структуру и состав образа контейнера
- Docker Container: Запущенный экземпляр контейнера из образа
- Docker Engine: Создает, доставляет и запускает контейнеры
- Docker Swarm: Подсистема кластеризации и планирования
- Docker Daemon: Управляет запросами от клиента Docker, выполняет сборку и запуска контейнеров
- Docker Store: Магазин приложений, для доверенных контейнеров готовых к продуктивным нагрузкам
Архитектура
Nutanix на текущий момент использует Docker Engine запущенный в ВМ, которые создаются при помощи сервиса Docker Machine. Эти машины могут работать в сочетании с обычными виртуальными машинами на платформе.
Nutanix предоставляет плагин для Docker по работе с томами, который занимается созданием, форматированием и подключением томов к контейнерам используя Блочные сервисы Acropolis. Это обеспечивает возможность подключения постоянных томов к контейнерам, и сохранность данных на них в случае перезагрузки / перемещения.
Персистентность данных достигается путем использования ПО Nutanix Volume Plugin, которое использует Блочные сервисы Acropolis, чтобы подключить том к узлу/контейнеру:
Пререквизиты
Чтобы воспользоваться Службой Контейнеров необходимо:
- Кластер Nutanix с ПО AOS 4.7 или более поздним
- Образ CentOS 7.0+ или Rhel 7.2+ OS с установленным пакетом iscsi-initiator-utils должен быть загружен на Платформу и доступен через Acropolis Image Service
- IP-адрес Службы данных должен быть сконфигурирован
- Docker Toolbox должен быть установлен на клиентской машине, для выполнения конфигурации
- Nutanix Docker Machine Driver должен быть добавлен к PATH на клиентской ВМ
Создание узла Docker
Если все способновуент пререквизитам, то можно перейти к первым шагам по развертыванию улов Docker используя Docker Machine:
docker-machine -D create -d nutanix \ --nutanix-username <PRISM_USER> --nutanix-password <PRISM_PASSWORD> \ --nutanix-endpoint <CLUSTER_IP>:9440 --nutanix-vm-image <DOCKER_IMAGE_NAME> \ --nutanix-vm-network <NETWORK_NAME> \ --nutanix-vm-cores <NUM_CPU> --nutanix-vm-mem <MEM_MB> \ <DOCKER_HOST_NAME>
Ниже представлена высокоуровневая схема рабочих процессов выполняемых на серверной части:
Следующие шаг - подключение по SSH к созданному узлу Docker:
docker-machine ssh <DOCKER_HOST_NAME>
Для инсталляции Nutanix Docker Volume Plugin выполните команду:
docker plugin install ntnx/nutanix_volume_plugin PRISM_IP=После выполнения команды вы увидите, что плагин установлен и запущен:
[root@DOCKER-NTNX-00 ~]# docker plugin ls ID Name Description Enabled 37fba568078d nutanix:latest Nutanix volume plugin for docker true
Создание контейнера Docker
Когда узел Docker готов и плагин установлен и работает, вы можете начинать создание контейнеров с персистентными дисками.
Том с использованием Блочной службы Acropolis могут быть созданы обычными командами Docker. Например:
docker volume create \ <VOLUME_NAME> --driver nutanix Например: docker volume create PGDataVol --driver nutanix
Следующая команда может быть использована для создания контейнера с персистентным томом:
docker run -d --name <CONTAINER_NAME> \ -p <START_PORT:END_PORT> --volume-driver nutanix \ -v <VOL_NAME:VOL_MOUNT_POINT> <DOCKER_IMAGE_NAME> Example: docker run -d --name postgresexample -p 5433:5433 --volume-driver nutanix -v PGDataVol:/var/lib/postgresql/data postgres:latest
Ниже представлена высокоуровневая схема рабочих процессов выполняемых на серверной части:
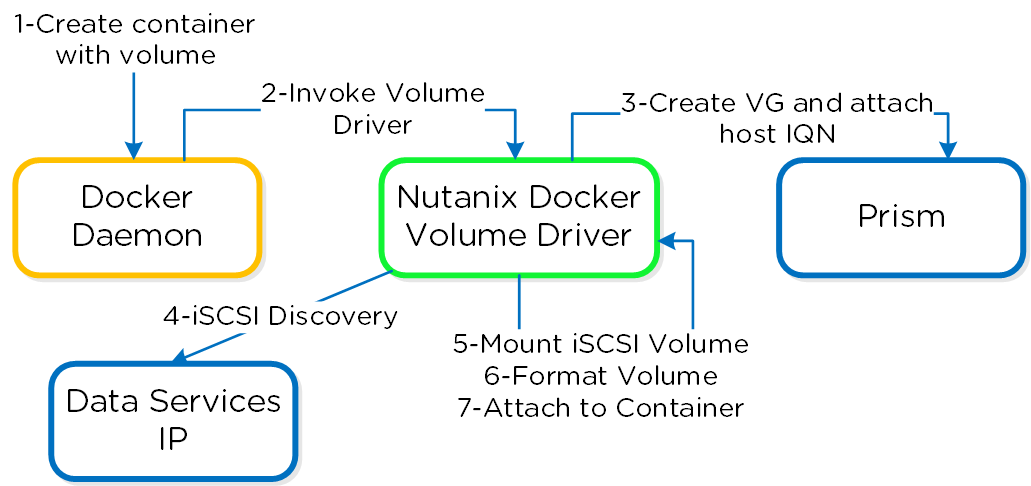
Теперь у вас есть контейнер с персистентным диском!
Резервное копирование и DR
Nutanix обеспечивает встроенные механизмы резервного копирования и катастрофоустойчивости (DR), которые могут быть использованы для резервного копирования и восстановления пользовательских ВМ и других данных на РХД.
Мы рассмотрим следующие пункты в следующих разделах:
- Объекты реализации
- Защищаемые объекты
- Резервное копирование и восстановление
- Репликации и катастрофоустойчивость
Примечание: Несмотря на то, что Nutanix имеет встроенные функции СРК и DR традиционные решения могут так же использоваться (например Commvault, Rubrik, и так далее), в своей работе данные решения используют встроенные механизмы Nutanix - VSS, snapshots).
Объекты реализации
Встроенные функции DR и СРК работают со следующими объектами:
Домен защиты (PD)
- Роль: Группа ВМ и/или файлов для защиты
- Описание: Группа ВМ и/или файлов для которых выполняется совместная репликация по расписанию. Домен защиты может защищать весь контейнер или же вы можете выбрать конкретные ВМ/файлы
Примечание
Совет от создателей
Создавайте разные Домены защиты для разные сервисов, согласно желаемому RPO/RTO. Для распространения файлов вы также можете использовать PD, добавив в него целевые файлы.
Группа консистентности (CG)
- Роль: Группа ВМ или файлов, собранные в группу, для обеспечения сквозной целостности
- Описание: ВМ и/или файлы собранные в логическую группу, для выполнения снимков, имеющих сквозную целостность между собой. Например, при восстановлении вся информационная система размещенная на разных ВМ собранных в группу консистентности сохранит целостность при восстановлении. Домен доступности может содержать несколько групп консистентности
Примечание
Совет от создателей
Группируйте ВМ в зависимости от сервисов развернутых на них, для обеспечения целостности всей ИС (например приложения и их БД)
Расписание создания снимков
- Роль: Расписание создания снимков и выполнения репликации
- Описание: Расписание выполнения репликации и создания снимков для ВМ в доменах защиты и группах консистентности
Примечание
Совет от создателей
Расписание должно соответствовать желаемому RPO
Политика хранения
- Роль: Количество локальных или удаленных снимков для хранения
- Описание: Политика определяет количество локальных или удаленных снимков для хранения. Примечание: Удаленная площадка должна быть настроена для настройки задач репликации и политик хранения.
Примечание
Совет от создателей
Политика хранения должна быть равна желаемому количеству точек восстановления ВМ/файлов
Удаленный сайт
- Роль: Удаленный кластер Nutanix
- Описание: Удаленный кластер Nutanix, который используется как цель для создания РК и снимков для выполнения восстановления в случае катастрофы.
Примечание
Совет от создателей
Убедитесь, что удаленный кластер имеет нужное количество вычислительных ресурсов и ресурсов хранения для восстановления ВМ. В некоторых случаях репликация/DR между серверными стойками так же имеет смысл.
Ниже представлена высокоуровневая схема отношений между перечисленными компонентами:
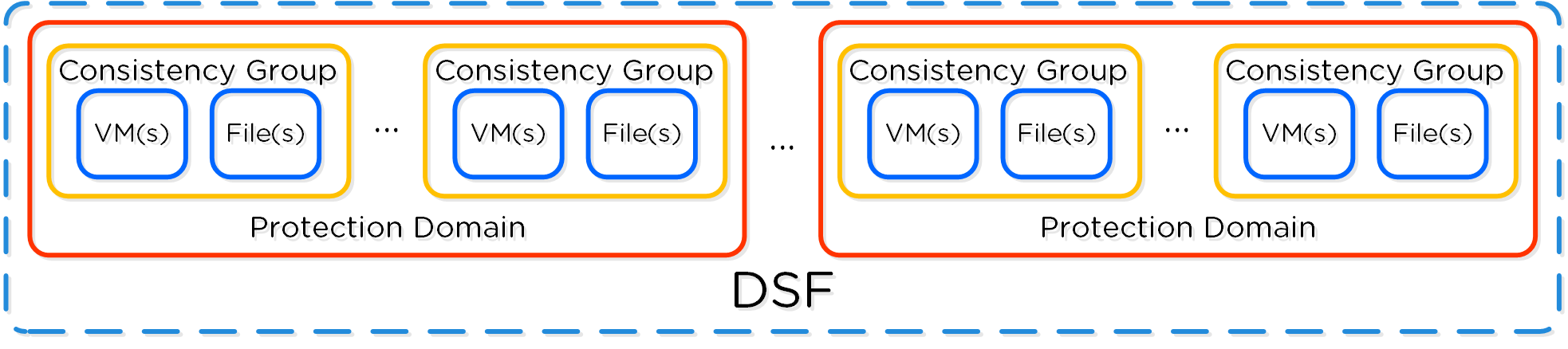
Объекты защиты
Вы можете защищать объекты такие как виртуальные машины, группы машин или файлы:
На странице Data Protection нужно выбрать вкладку + Protection Domain -> Async DR:

Укажите имя домена защиты и нажмите 'Create'
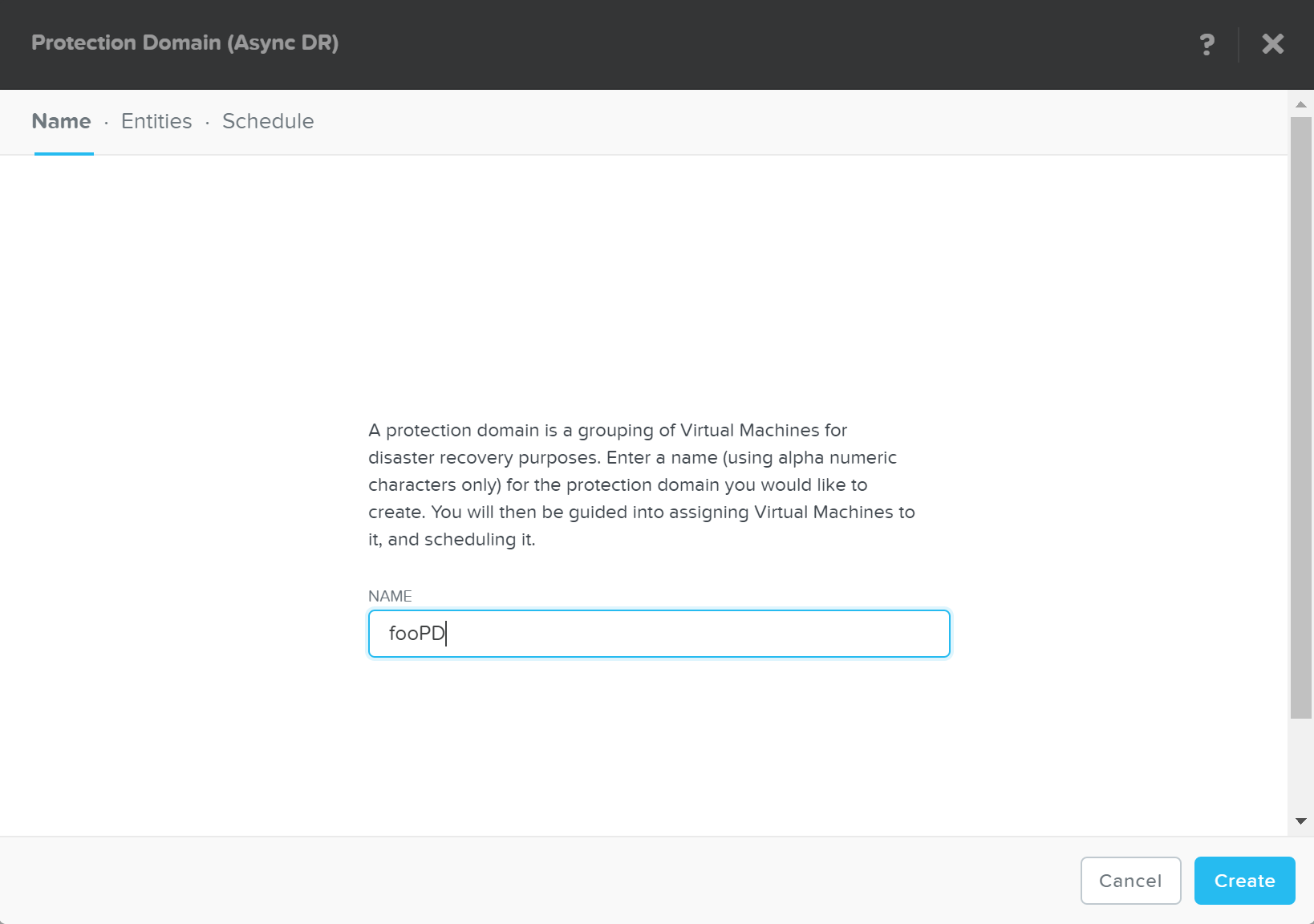
Теперь укажите объекты для защиты:
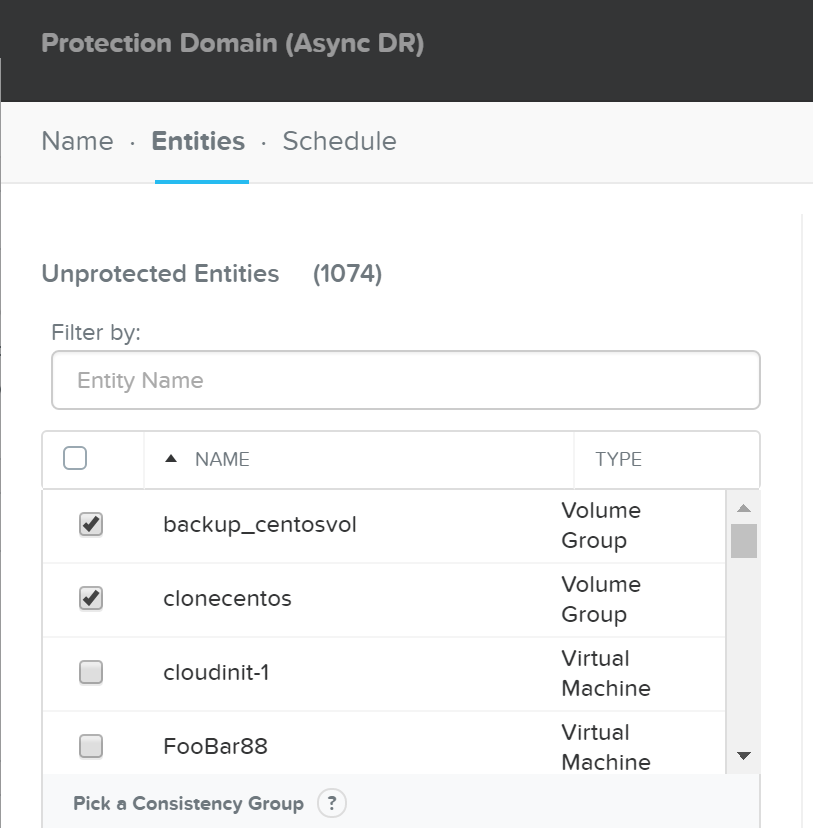
Нажмите 'Protect Selected Entities'
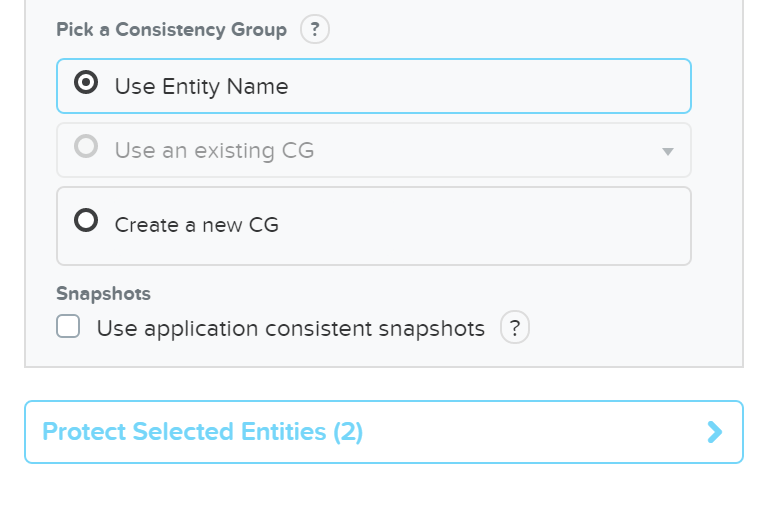
Защищенные объекты отображаются в секции 'Protected Entities'
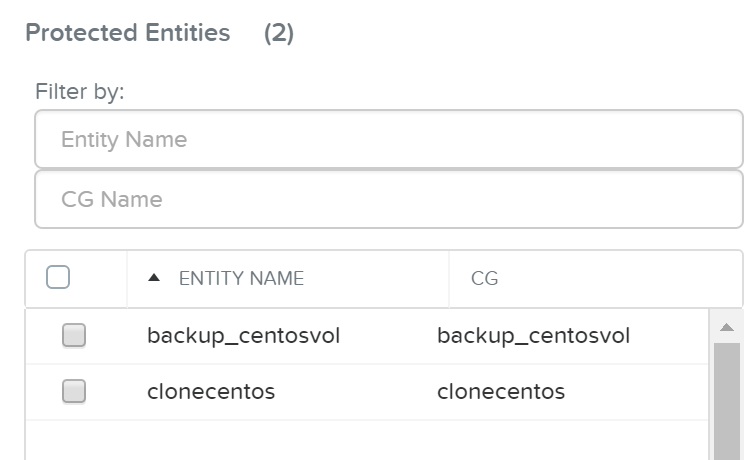
Нажмите 'Next', затем click 'Next Schedule' для настройки расписания создания снимков и выполнения репликации
Настройте требуемую частоту выполнения снимков и глубину их хранения, а так же удаленные кластеры для передачи копий
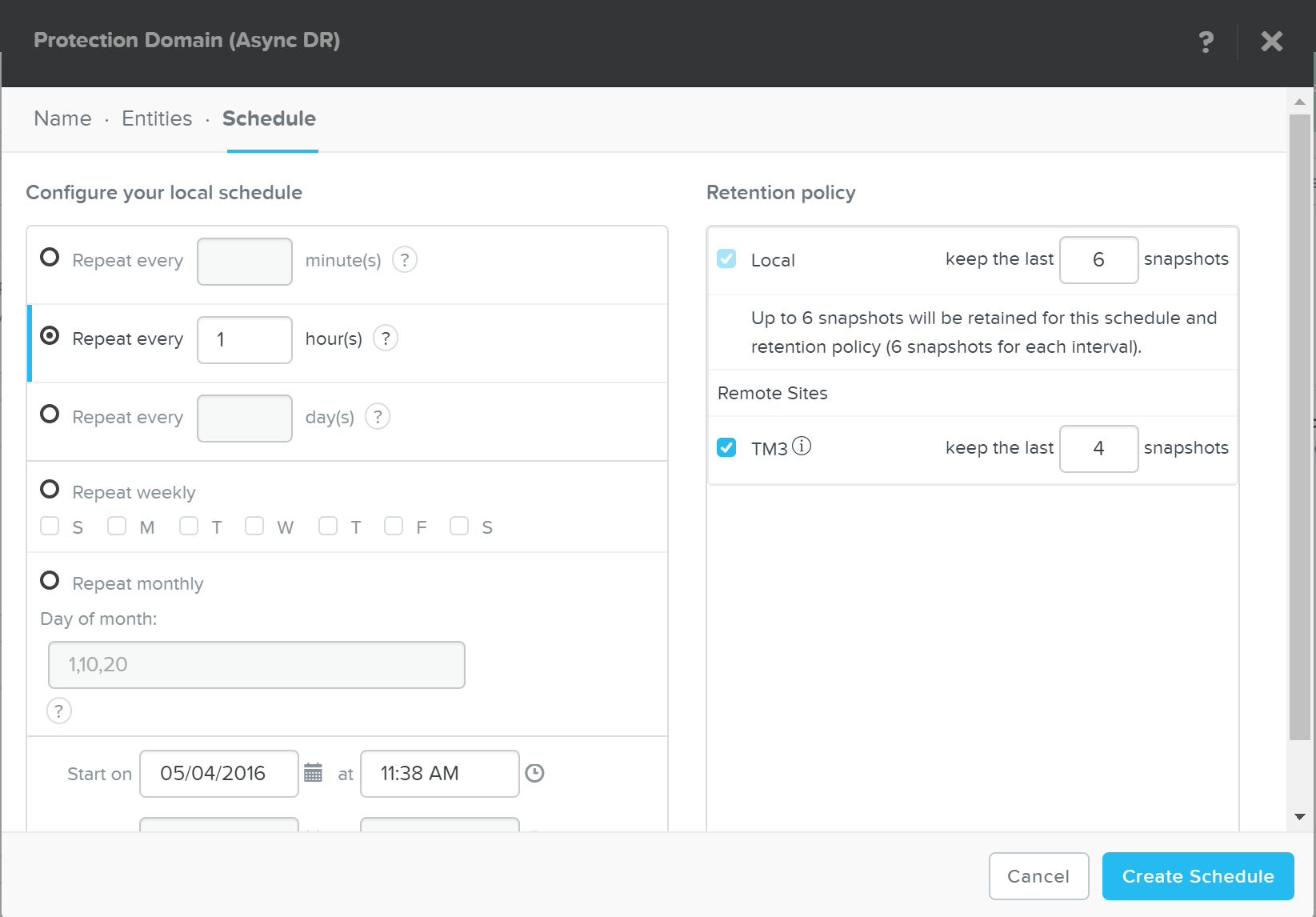
Нажмите 'Create Schedule' для завершения настройки расписания.
Примечание
Множественные задачи расписания
Существует также возможность создания множественных снимков и задач репликации. Например, если вы хотите иметь отдельную политику создания локальных снимков раз в час и копирования на удаленную площадку раз в день.
Важно отметить, что весь контейнер может быть защищен разом. Однако, платформа предлагает возможнсть гранулярной настройки репликации - на уровне ВМ и файлов.
Работа с резервными копиями
Для создания снимков Платформа использует встроенные функции РХД по работе со снимками и встроенные сервисы Cerebro и Stargate. Эти снимки так же имеют свои собственные карты блоков, для большей эффективности использования хранилища и сокращения перерасхода ресурсов. Более подробно об этом можно прочитать в разделе "Снимки и клоны".
Стандартные операции РК и восстановления включают:
- Snapshot: Создание снимка и репликация
- Restore: Восстановление ВМ / Файлов из снимков (заменяет оригинальный объект)
- Clone: Процедура похожая на восстановление, однако в результате создается новый объект, оригинал при этом не затрагивается
На странице Data Protection, в разделе 'Protecting Entities', можно увидеть созданные ранее домены защиты.

Выбрав один из доменов защиты вы получите перечень действий, который можно с ним осуществить:

Если вы нажмете 'Take Snapshot' то будет сделан дополнительный снимок, который может быть передан на удаленную площадку:
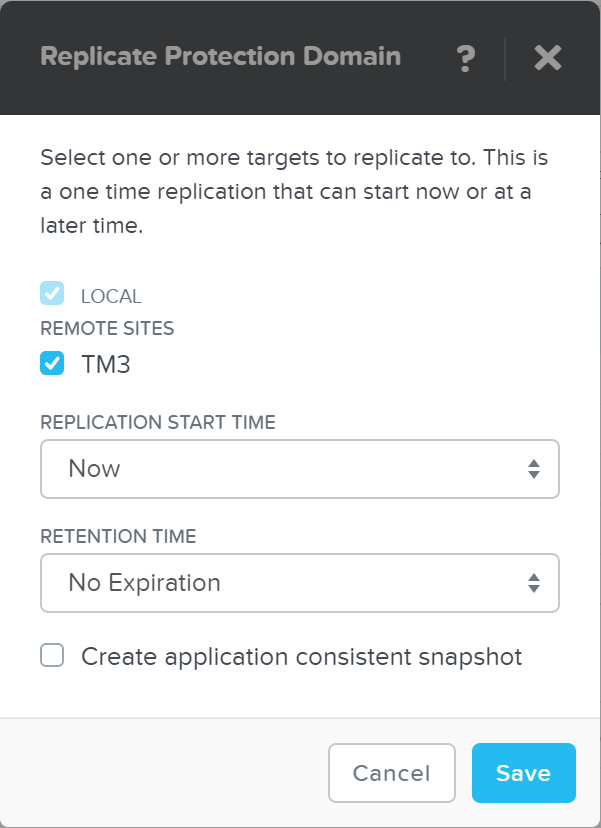
Так же вы можете выполнить операцию 'Migrate', которая выполнит восстановление домена защиты на удаленной площадке:
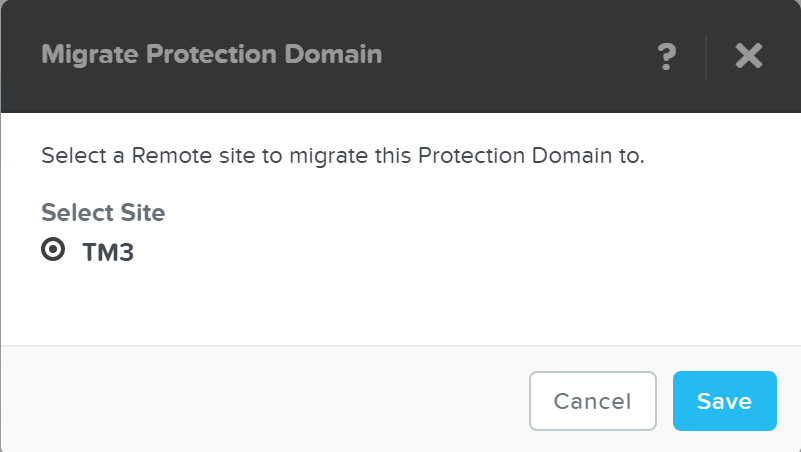
В случае выполнения ручной миграции система сделает новый снимок и затем передаст его на удаленную площадку.
Примечание
Совет от создателей
Начиная с Asterix и далее вы можете использовать репликацию данных одного узла для защиты данных.
Так же на таблице ниже вы можете посмотреть все существующие снимки домена защиты:
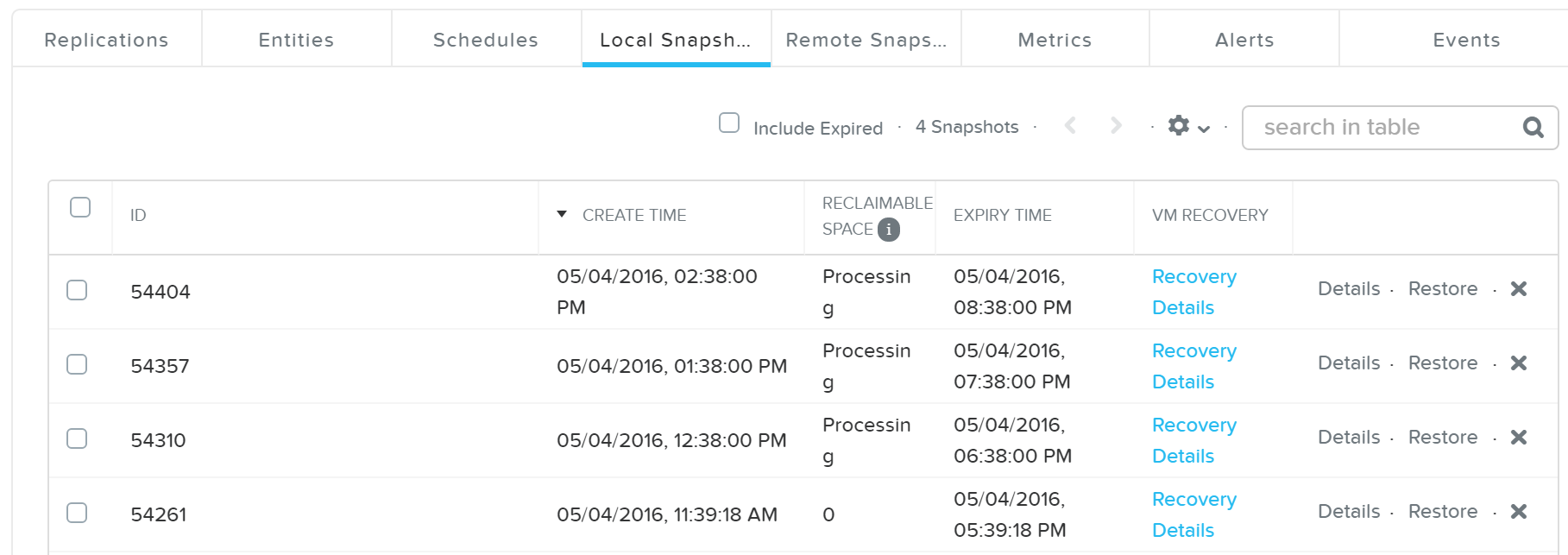
Тут вы можете восстановить снимок или создать клон:
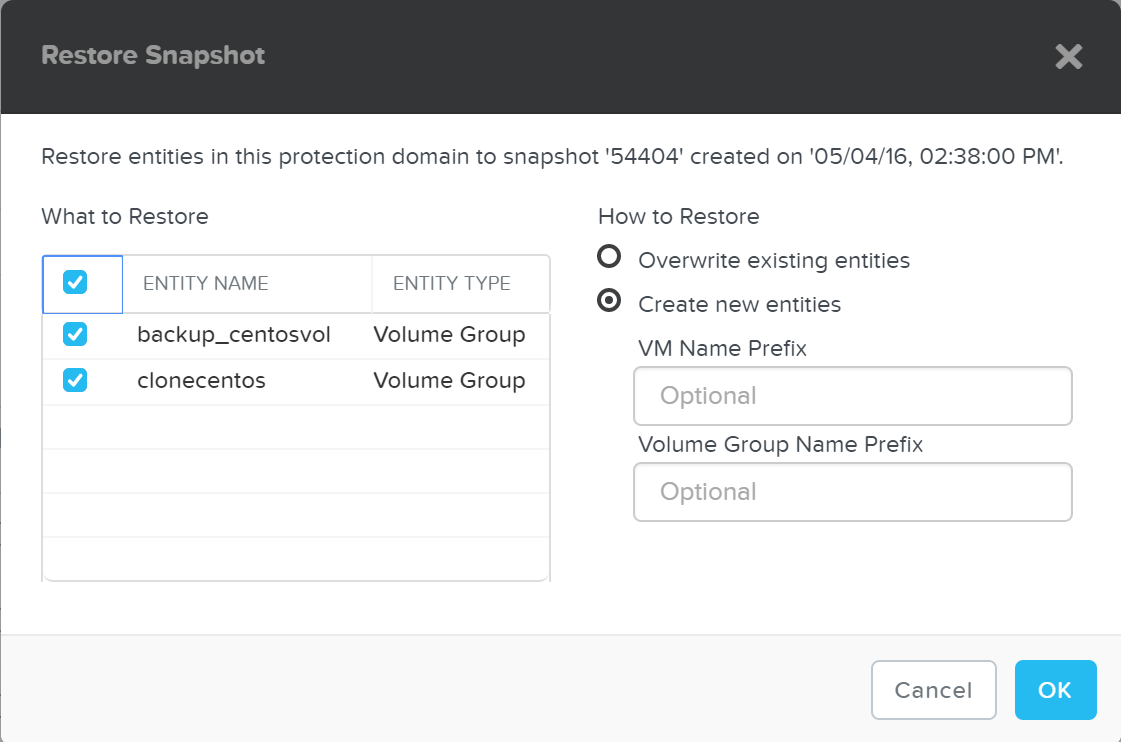
Если вы выбрали 'Create new entities' будет выполнено клонирование снимков в домене защиты, и созданы новые объекты с указанным при восстановлении префиксом. Если будет выбрана опция 'Overwrite existing entities' восстанавливаемые копии заменят текущие объекты.
Примечание
Хранение копий на локальном хранилище / Storage only backup target
Для хранения резервных или архивных копий можно использовать удаленный кластер Nutanix, который состоит из узлов "storage only".
Целостные снимки на уровне приложений
Nutanix предоставляет встроенный механизм VmQueisced Snapshot Service для выполнения снимков обеспечивающих целостность на уровне пользовательских приложений, разворачиваемых в гостевых ОС.
Примечание
Служба создания снимков VmQueisced(VSS)
VSS обычно является типичным сервисом в ОС Windows - Volume Shadow Copy Service. Однако, наше решение решение работает как с Windows, так и с Linux и мы решили назвать его VmQueisced Snapshot Service.
Поддерживаемые конфигурации
Данное решение применимо к гостевым ОС на базе Windows и Linux, включая версии перечисленные ниже:
-
Гипервизоры:
- ESX
- AHV
-
Windows
- 2008R2, 2012, 2012R2
-
Linux
- CentOS 6.5/7.0
- RHEL 6.5/7.0
- OEL 6.5/7.0
- Ubuntu 14.04+
- SLES11SP3+
Пререквизиты
Для использования функции создания снимков Nutanix VSS требуется:
-
Платформа Nutanix
- VIP-адрес кластера должен быть сконфигурирован
-
Гостевая ОС / ВМ
- ПО NGT должно быть установлено
- VIP-адрес CVM должен быть доступен по порту 2074
-
Конфигурация катастрофоустойчивости
- Пользовательская ВМ должна быть в Домене защиты, опция 'Use application consistent snapshots' должна быть включена
Архитектура
Начиная с версии 4.6 данная функция доступна посредством ПО Nutanix Hardware VSS которое устанавливается в гостевые ОС вместе с Гостевыми утилитами. Более подробно о Гостевых утилитах Nutanix можно прочитать в соответствующей секции.
Ниже показана верхнеуровневая архитектура сервиса VSS:
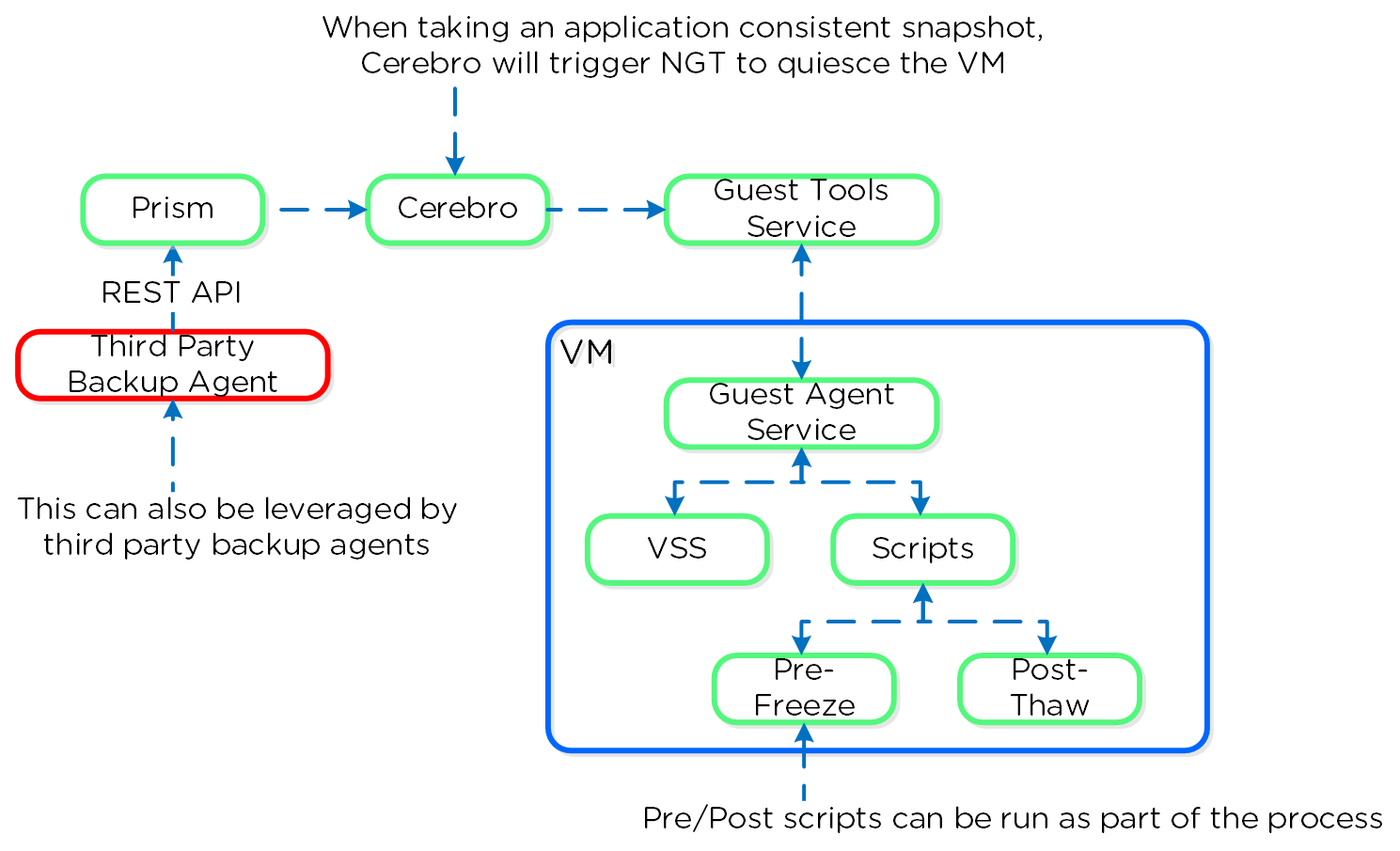
Вы можете вручную выполнить создание целостного снимка, следуя стандартному пути создания снимка, но отметив опцию 'Use application consistent snapshots', когда выбираете ВМ для защиты.
Примечание
Включение/Выключение Nutanix VSS
Когда для пользовательских ВМ включены Гостевые утилиты Nutanix NGT функция VSS становится доступной по умолчанию. Однако, вы можете выключить эту функцию, выполнив команду:
ncli ngt disable-applications application-names=vss_snapshot vm_id=<VM_ID>
Архитектура Windows VSS
Решение VSS Nutanix интегрируется с встроенной функцией VSS ОС Windows VSS. Ниже показана верхнеуровневая схема связи функций:
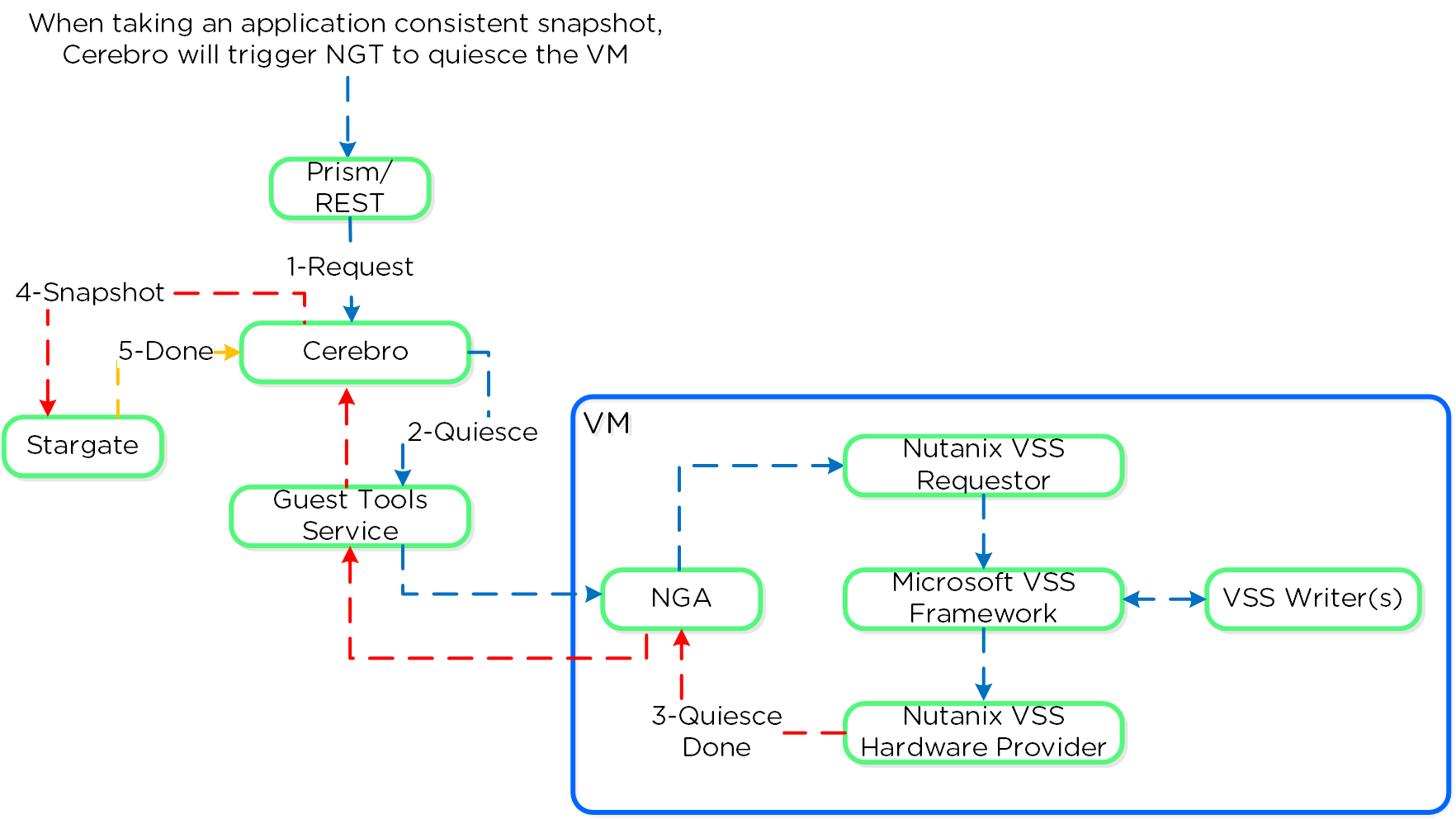
Как только NGT установлены вы можете увидеть статус агента NGT и сервиса VSS Hardware Provider:
Архитектура Linux VSS
Решение для Linux похоже на решение для Windows, однако вместо MS VSS используются скрипты.
Ниже показана архитектура и схема взаимодействия компонент:
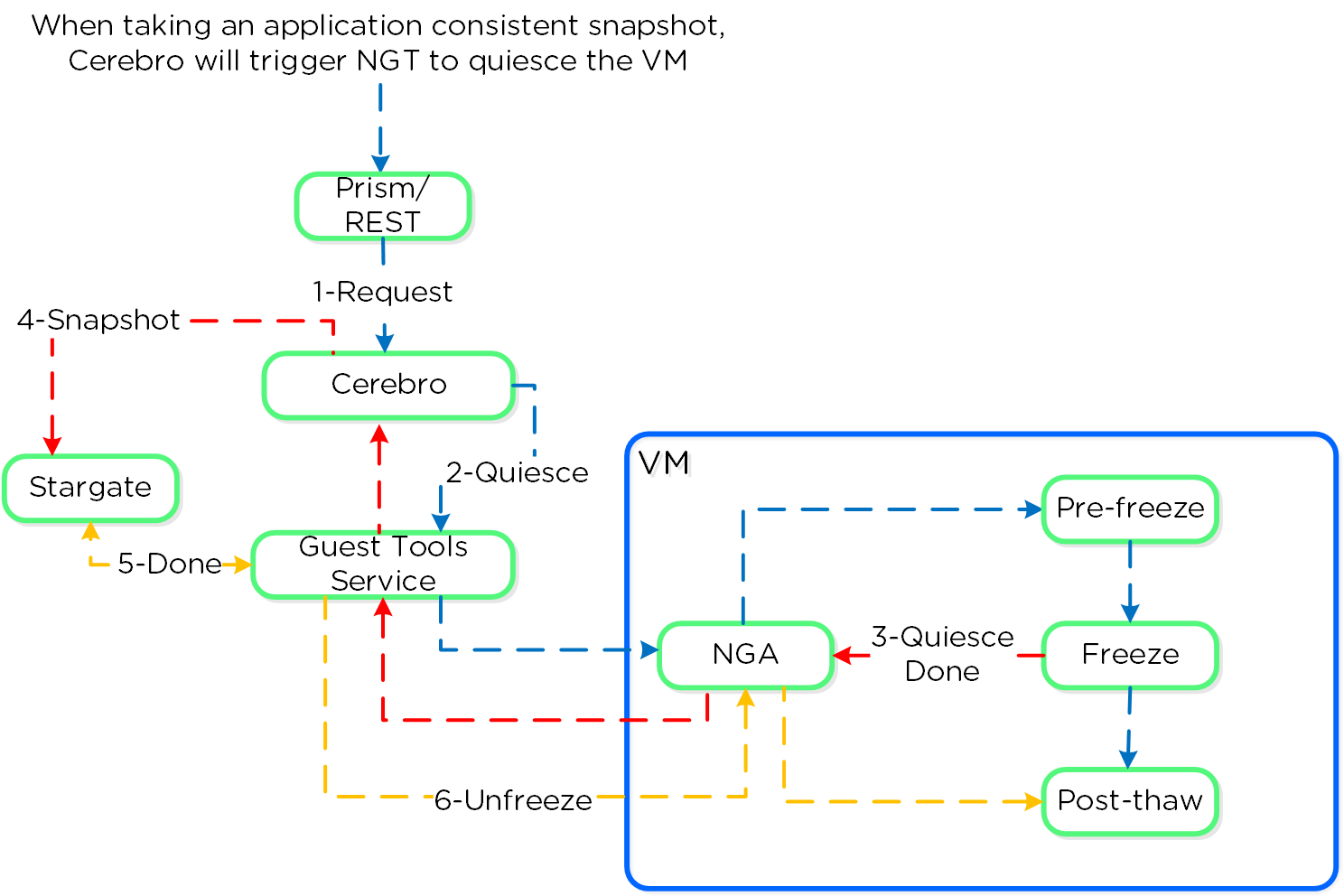
Скрипты выполняющие временную заморозку и последующий возврат к рабочему состоянию расположены тут:
- Пре-скрипт: /sbin/pre_freeze
- Пост-скрипт: /sbin/post-thaw
Примечание
Eliminating ESXi Stun
ESXi имеет встроенную возможность создания целостных снимков на уровне гостевых приложений используя ПО VMware Guest Tools. Однако, в процессе создания таких снимков создаются дельта-диски и ESXi подвисает на момент изменения маппинга виртуальных дисков к новым дельта-дискам, которые начнут обрабатывать IO. То же самое происходит, когда снимки удаляются.
В момент подвисания - гостевая ОС не может выполнять никакие операции и по факту находится в зависшем состоянии - не проходят ping пакеты, операции IO остановлены. Длительность подвисания зависит от количества vmdks и скорости операций на хранилище данных.
С Nutanix VSS мы позволяем полностью обойти создание снимков VMware, а значит полностью исключаем такое поведение системы и ВМ. Предоставляя большую стабильность и скорость работы для ВМ.
Репликация и катастрофоустойчивость (DR)
Краткий рассказ на английском языке доступен по ссылке
Nutanix предоставляет встроенные механизмы для выполнения репликации данных между кластерами и подсистему обеспечения катастрофоустойчивости. Эта функциональность реализуется на базе встроенного механизма создания снимков. Данный механизм описан в разделе Снимки и клоны. Компонент платформы Cerebro отвечает за управление DR и репликацией, компонент запускается на всех узлах кластера, и осуществляет выбор мастера, который управляет задачами репликации. В случае если текущий мастер Cerebro выйдет из строя, другой экземпляр сервиса будет выбран для этой роли. Страница Cerebro - <CVM IP>:2020. DR может быть разбит на несколько основных объектов:
- Топология репликации
- Жизненный цикл репликации
- Глобальная дедупликация
Топология репликации
Существует несколько топологий репликации: Один к одному, один ко многим, все ко всем. В отличие от традиционных решений, которые в основном предлагают репликацию один к одному или один ко многим, Nutanix обеспечивает гибкую топологию многие ко многим.
Естественно, вы можете выбрать ту топологию, которая наиболее полно отвечает запросам вашей компании.
Жизненный цикл репликации
Механизм репликации Nutanix использует сервис Cerebro упомянутый выше. Сервис Cerebro состоит из “Cerebro Master” который размещается на одной из функционирующих CVM, и Cerebro Slaves которые работают на всех остальных CVM. В случае выхода из строя текущего мастера, новый мастер будет выбран автоматически.
Cerebro Master отвечает за управление задачами и передачи их сервисам Cerebro Slaves, а так же за координацию задач Cerebro Master, при выполнении репликации.
В процессе репликации Cerebro Master поймет какие данные должны быть отреплицированны, и передаст задачу Cerebro Slaves который в свою очередь сообщит сервису Stargate какие данные реплицировать и куда.
Реплицируемые данные защищаются на разных уровнях в процессе. Экстенты считываются на кластере источнике, с них снимаются контрольные суммы, чтобы убедиться что данные целостные. Затем с переданных экстентов на кластере назначения так же снимаются контрольные суммы и осуществляется проверка целостности. Протокол TCP используемый для передачи снимков обеспечивает конститентность на уровне сети.
На следующем рисунке показано представление этой архитектуры:
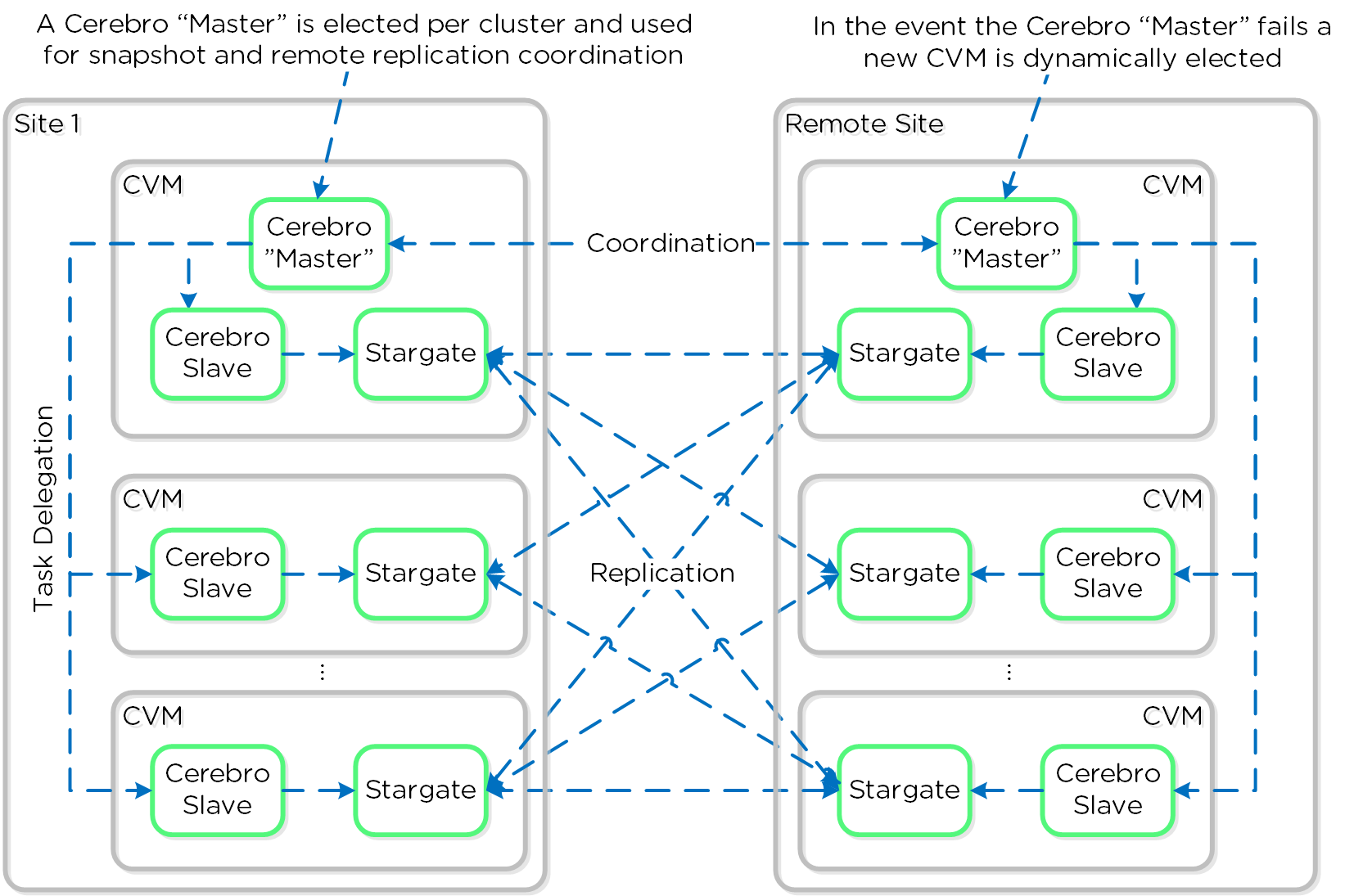
Кроме того можно настроить доступ к удаленному кластеру через прокси, который будет использоваться как входная точка для всего трафика репликации и DR от кластера.
Примечание
Совет от создателей
Когда используется конфигурация с прокси - всегда используйте VIP адрес целевого кластера, он будет доступным даже в случае выхода из строя CVM
Ниже показана схема репликации при использовании прокси:
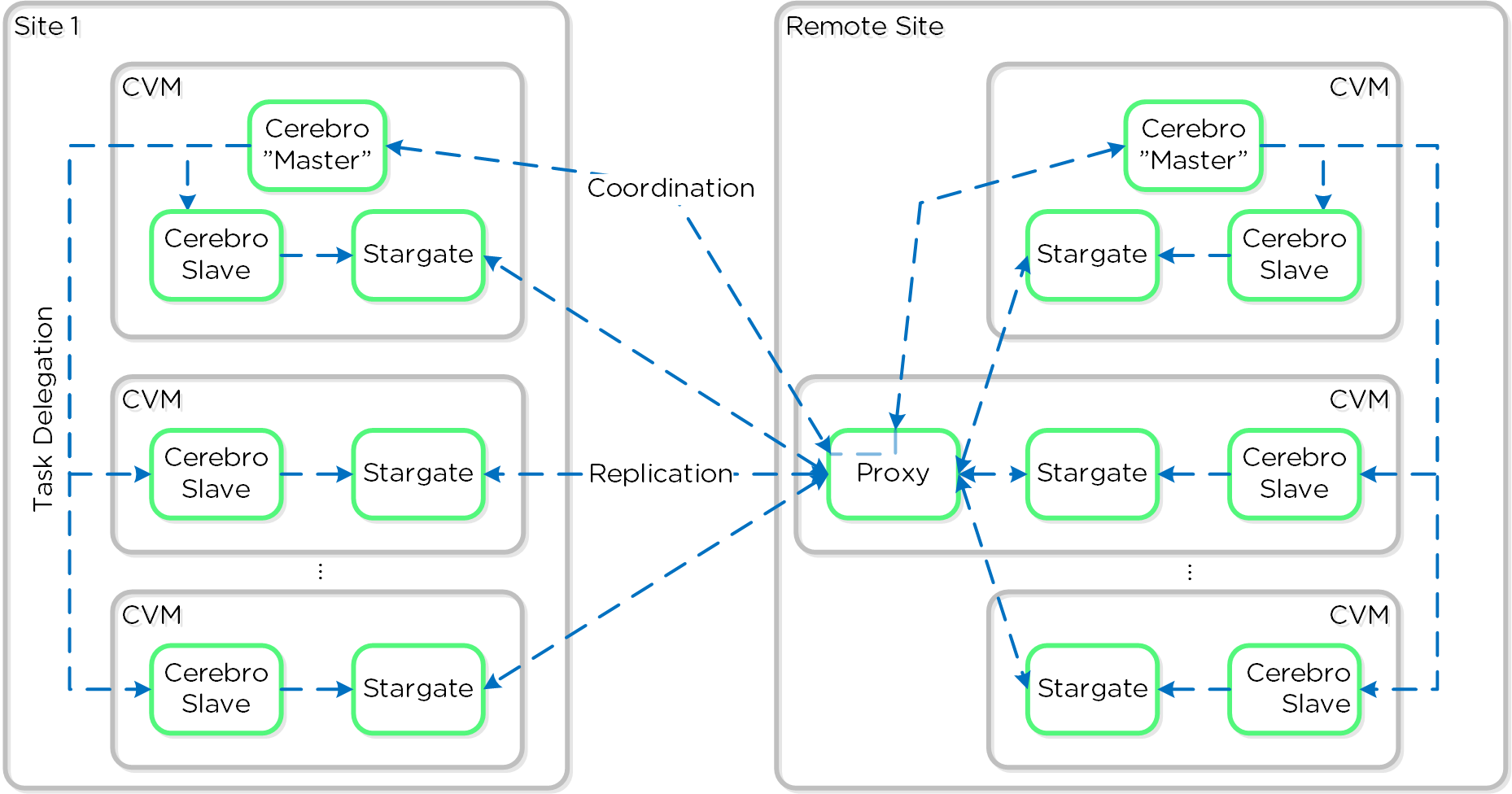
В некоторых случаях можно настроить доступ на удаленный кластер через SSH тоннель, через него будет проходить вест трафик репликации.
Примечание
Примечание
Такая конфигурация не должна использоваться для продуктивных инсталляций. Кластерные VIP-адреса должны использоваться для обеспечения доступности.Ниже показана схема репликации при использовании SSH тоннеля:
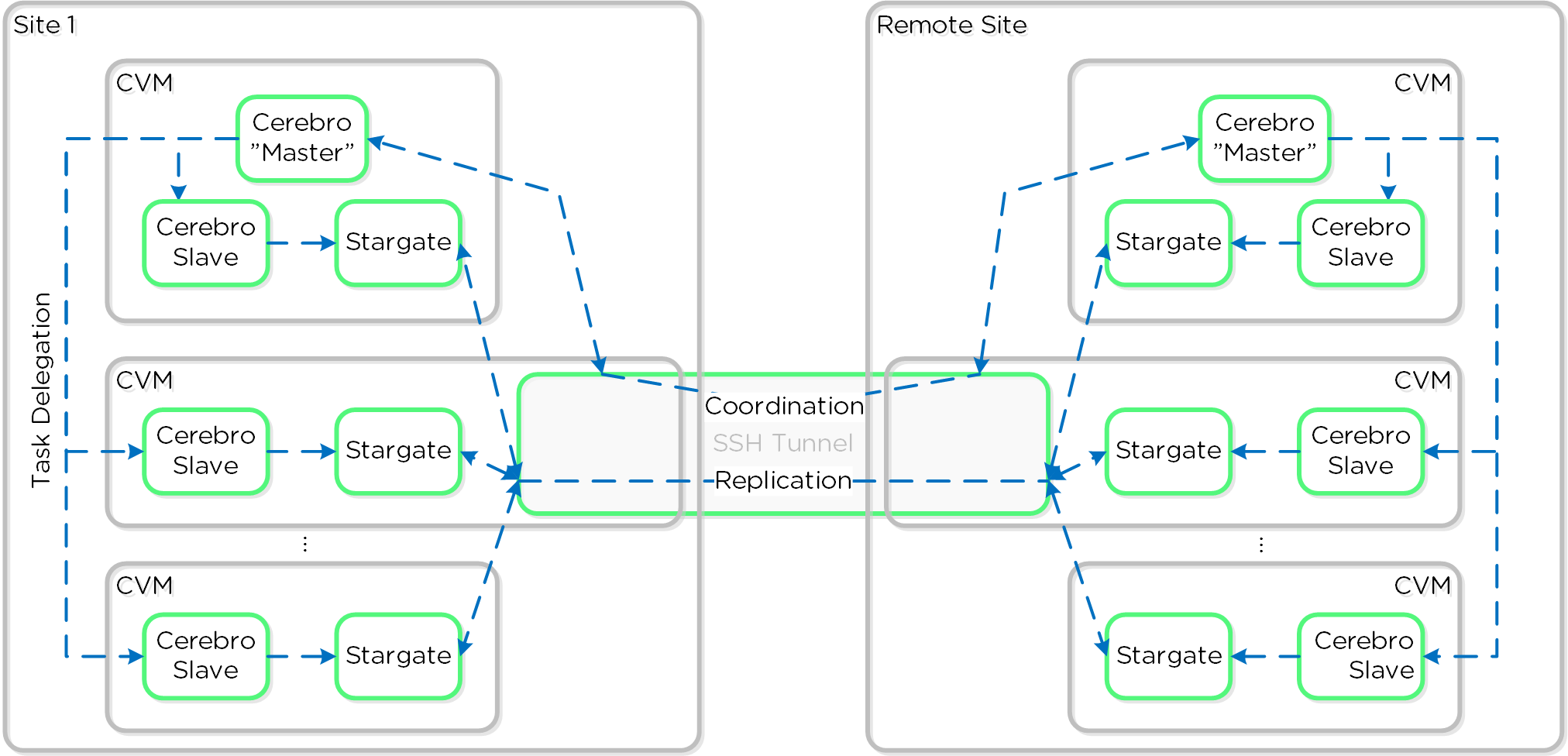
Глобальная дедупликация
Как говорилось ранее в разделе Elastic Deduplication Engine, Платформа имеет встроенные функции обеспечивающие дедупликацию данных, простым обновлением указателей в метаданных. Тот же концепт применяется к функции репликации и DR. Перед отправкой данных с кластера на кластер Платформа осуществить запрос на кластер назначения, и проверит есть ли там хэш. Наличие хэша подразумевает наличие данных, это значит что данные передавать не надо. Будет выполнено лишь обновление хэшей. Если же данных нет - такие данные будут сжаты и отправлены на кластер назначения. После передачи - данные существуют на обоих кластерах и могут использоваться для дедупликации
На следующем рисунке показан пример развертывания трех кластеров, где каждый кластер содержит один из нескольких доменов защиты (PD):
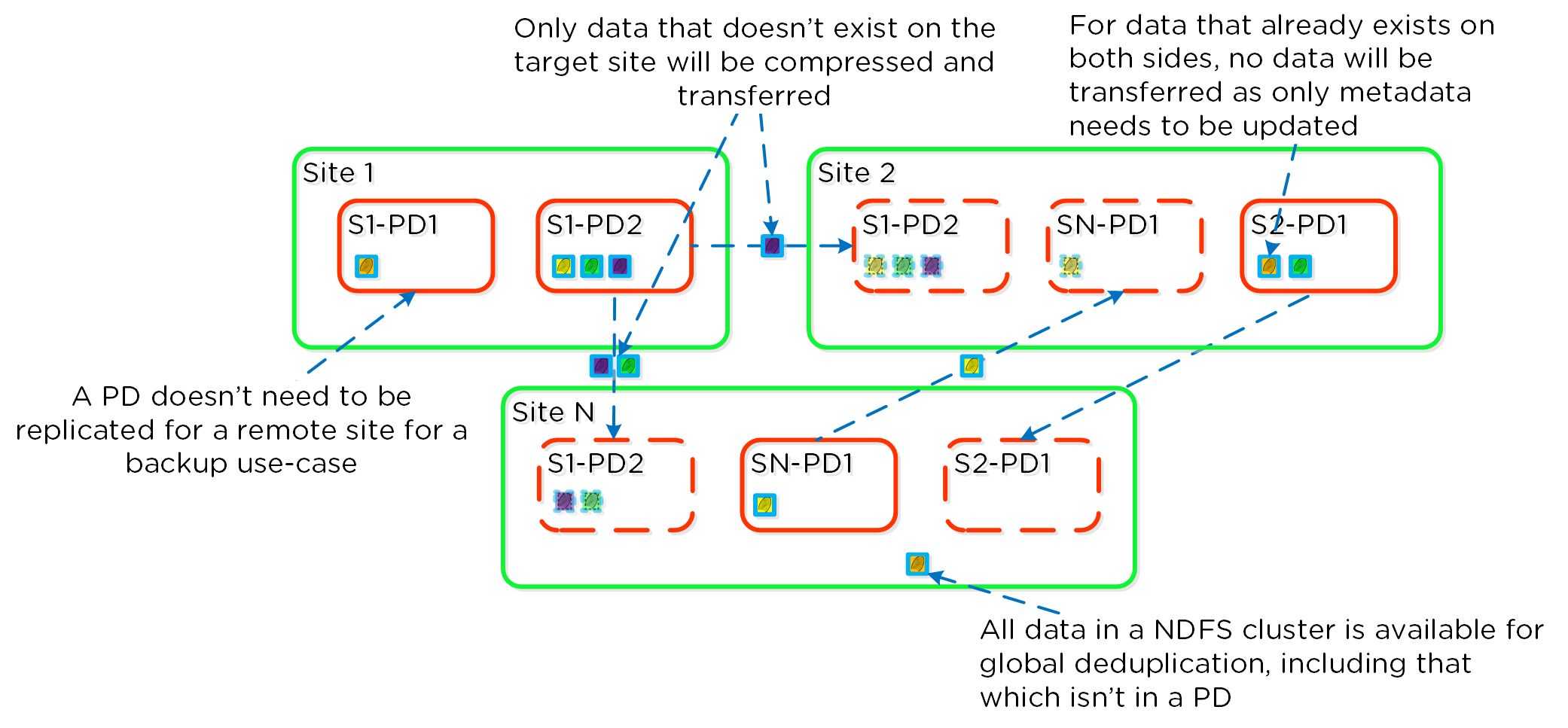
Примечание
Примечание
Дедупликация должна быть включена для контейнера кластера источника и для кластера назначения.
Синхронизация NearSync
Используя традиционные возможности асинхронной репликации Nutanix предоставил поддержку почти синхронной репликации (NearSync).
NearSync обеспечивает - минимальное влияние на задержку I/O (как при асинхронной репликации) и обеспечивает очень низкий RPO (как при синхронной репликации). Т.е. пользователи могут иметь очень низкий RPO без перерасхода ресурсов, как при синхронной репликации.
Эта функция использует новую технологию создания снимков - LWS (light-weight snapshot). В отличие от традиционных снимков vDisk которые используются для асинхронной репликации, данная технология использует маркеры и полностью реализована на базе OpLog (в отличие от классических снимков на базе Хранилища экстентов).
Мы добавили новый сервис Mesos для управления снимками и абстрагирования от сложности полных/инкрементальных снимков. Cerebro при этом все так же используется для управления политиками и высокоуровневыми компонентами. Mesos при этом отвечает за взаимодействие с Stargate и контроль за жизненным циклом LWS.
Ниже представлена высокоуровневая архитектура компонентов NearSync:
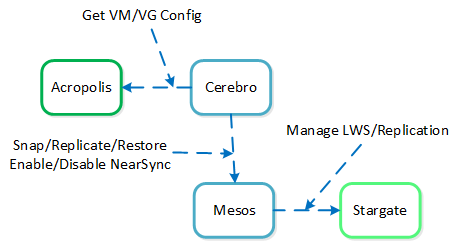
Когда пользователь настраивает частоту выполнении снимка меньшую или равную 15 минутам, NearSync будет использоваться автоматически. В этот момент, будет сделан инициализационный снимок и передан на кластер/кластеры назначения. Если данная задача будет выполнена менее чем за 60 минут, следующий снимок будет сразу же сделан и скопирован в дополнение к запуску репликации моментальных снимков LWS. Как только второй снимок будет скопирован, все уже скопированные снимки LWS станут валидными и Платформа поймет, что NearSync может использоваться.
На следующем рисунке показан пример временной шкалы от включения NearSync для начала функционирования:
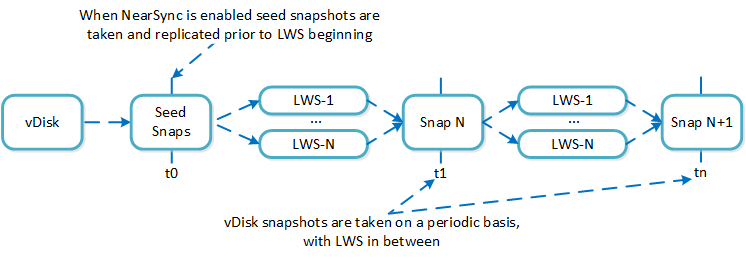
После того, как стало понятно, что NearSync может использовать - снимки vDisk будут выполняться каждый час. Вместо отправки полного снимка на удаленный сайт, удаленный сайт собирает снимок vDisk на базе базового снимка vDisk и изменений, передаваемых с помощью LWS.
В случае, если NearSync какое-то время не может выполняться, в связи с тем, что репликация LWS занимает более 60 минут, система автоматически переключится на выполнение классических снимков vDisk. Если один из снимков выполнился за менее чем 60 минут, система сразу же выполнит еще один снимок и начнет репликацию LWS. Как только полный снимок будет выполнен, снимок LWS будет признан валидным и система снова переключится на NearSync. Т.е. процесс похож на тот, который выполняется при первичном включении этой функции.
Когда снимок LWS восстанавливается, система выполнит клонирование последнего снимка vDisk и применит к нему все требуемые изменения из LWS.
Ниже показано, каким образом осуществляется восстановление снимков на базе LWS:
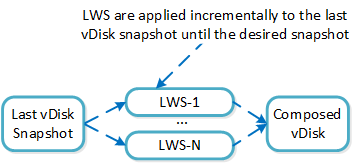
Метро-кластер
Платформа Nutanix обеспечивает встроенную возможность создания растянутого между ЦОД кластера. При такой инсталляции вычислительные ресурсы кластера делятся на две части между ЦОД и имеют общий ресурс хранения.
Такой подход обеспечивает расширение домена HA, с одного ЦОД на два. И позволяет обеспечить близкие к нулю показатели RTO и RPO.
При такой инсталляции каждый ЦОД имеет свой собственный кластер Nutanix, однако контейнеры логически "растянуты" между ними с использованием синхронной репликации.
Ниже показана высокоуровневая архитектура метро-кластера:
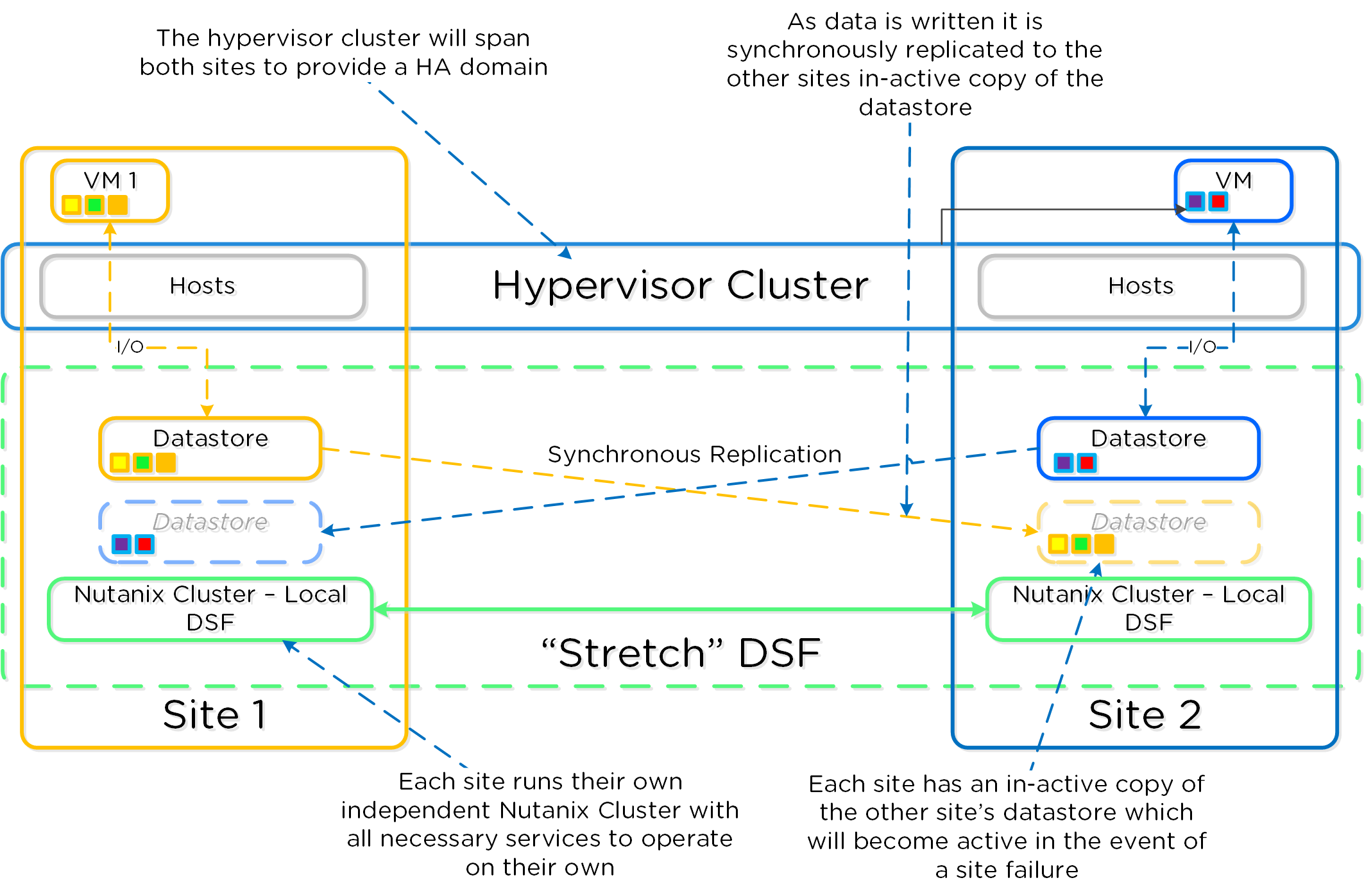
В случае выхода из строя одного кластера, будет обработано событие HA при котором все ВМ будут перезапущены на работоспособном кластере. Восстановление работоспособности кластера, вышедшего из строя обычно ручной процесс. Однако начиная с версии Asterix восстановление после сбоя может быть автоматизировано встроенными средствами и сконфигурировано через Prism.
Ниже показан пример отказа одного из кластеров:
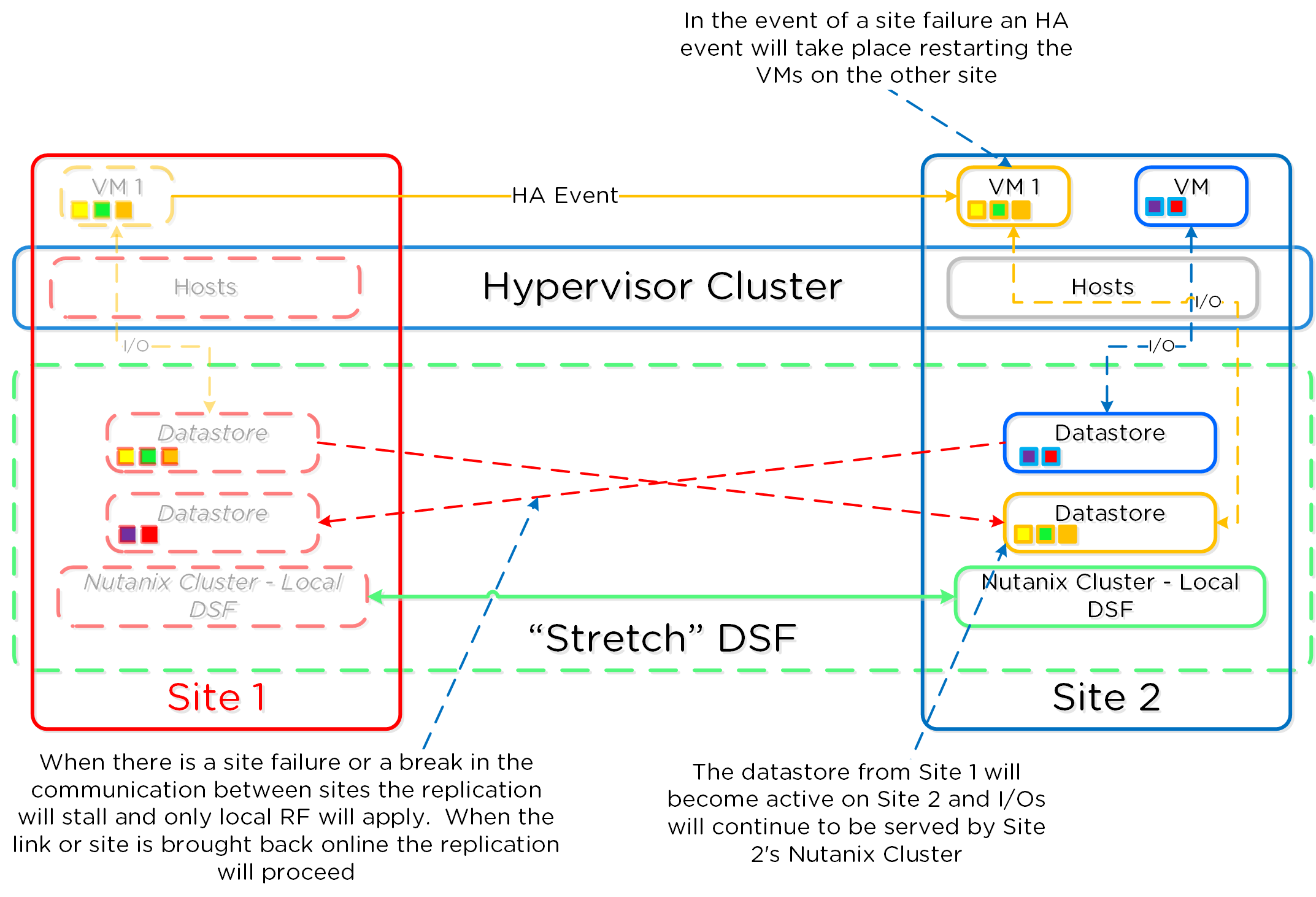
В случае проблем соединения между кластерами - каждый из них продолжит функционировать независимо друг от друга. Как только соединение будет восстановлено - кластеры выполнят синхронизацию накопившихся изменений и синхронная репликация будет снова восстановлена.
Ниже показан пример проблем соединения:
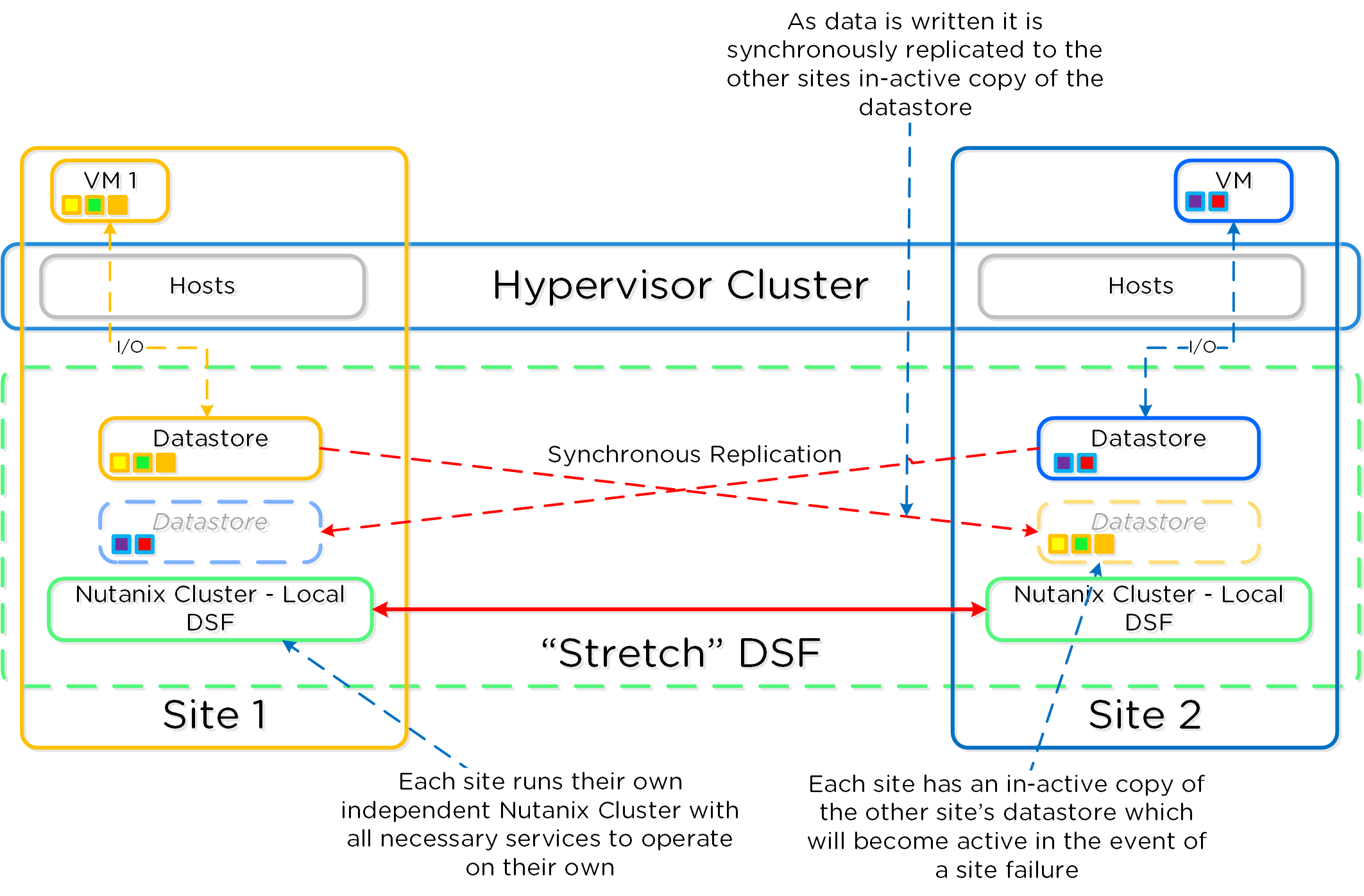
Функция Cloud Connect
Функция Cloud Connect построена на базе встроенных механизмов DR и репликации РХД. Данная функция расширяет возможности репликации до облачных провайдеров (Amazon Web Services, Microsoft Azure). Примечание: Сейчас возможно выполнение резервного копирования / репликации данных.
Облачная инфраструктура провайдера может быть добавлена как удаленный сайт, так же через Prism. Как только облачная платформа будет добавлена, Платформа автоматически развернет один узел кластера как ВМ в EC2 (сейчас используется m1.xlarge) или Azure (сейчас - D3). Эта ВМ будет использоваться как логическая точка входа.
ВМ в облачном сервисе представляет собой ПО работающее на основе Acropolis для локальных кластеров. Это значит, что будут использоваться все встроенные функции репликации (глобальная дедупликация, репликация изменений и так далее).
В случае, если несколько кластеров используют функцию Cloud Connect, они будут A) использовать одну и ту же ВМ, или B) поднимут по отдельной ВМ.
Хранилище для ВМ будет реализовано при помощи "cloud disk", который по сути является диском на S3 (AWS) или BlobStore (Azure). Данные при этом хранятся как обычные egroups, которые по сути являются файлами на объектном хранилище.
Ниже представлена схема, где в качестве удаленной площадки используется инфраструктура облачного провайдера:
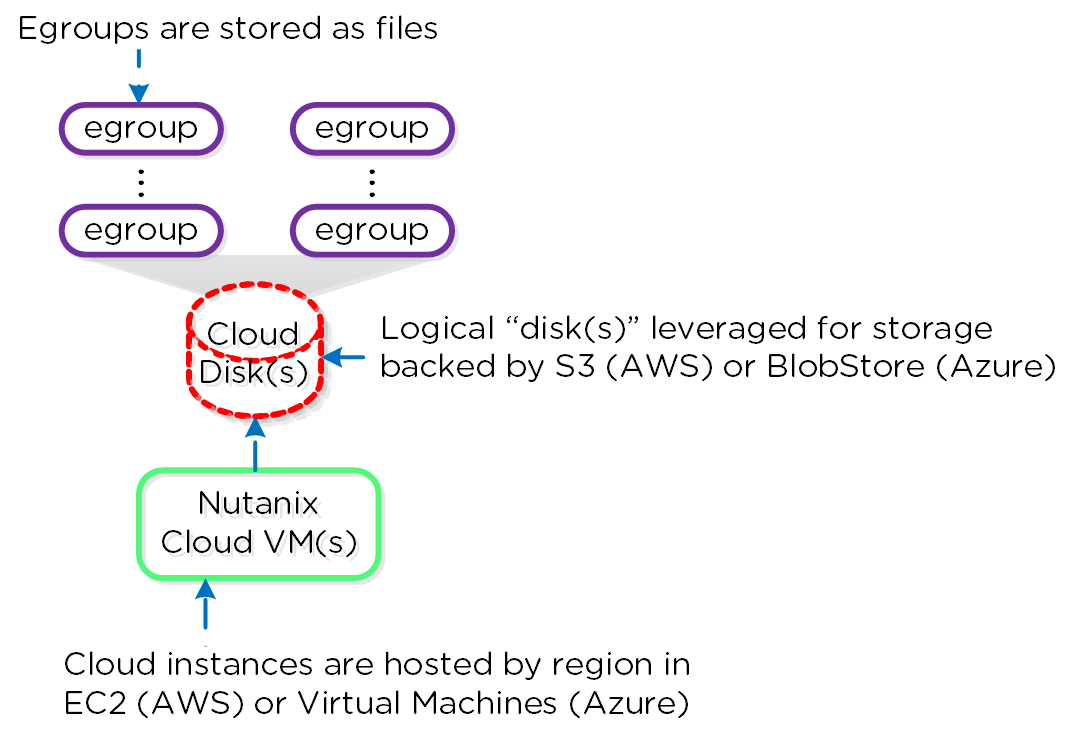
Поскольку облачный удаленный сайт похож на любой другой удаленный сайт Nutanix, кластер может реплицироваться в несколько регионов, если требуется более высокая доступность
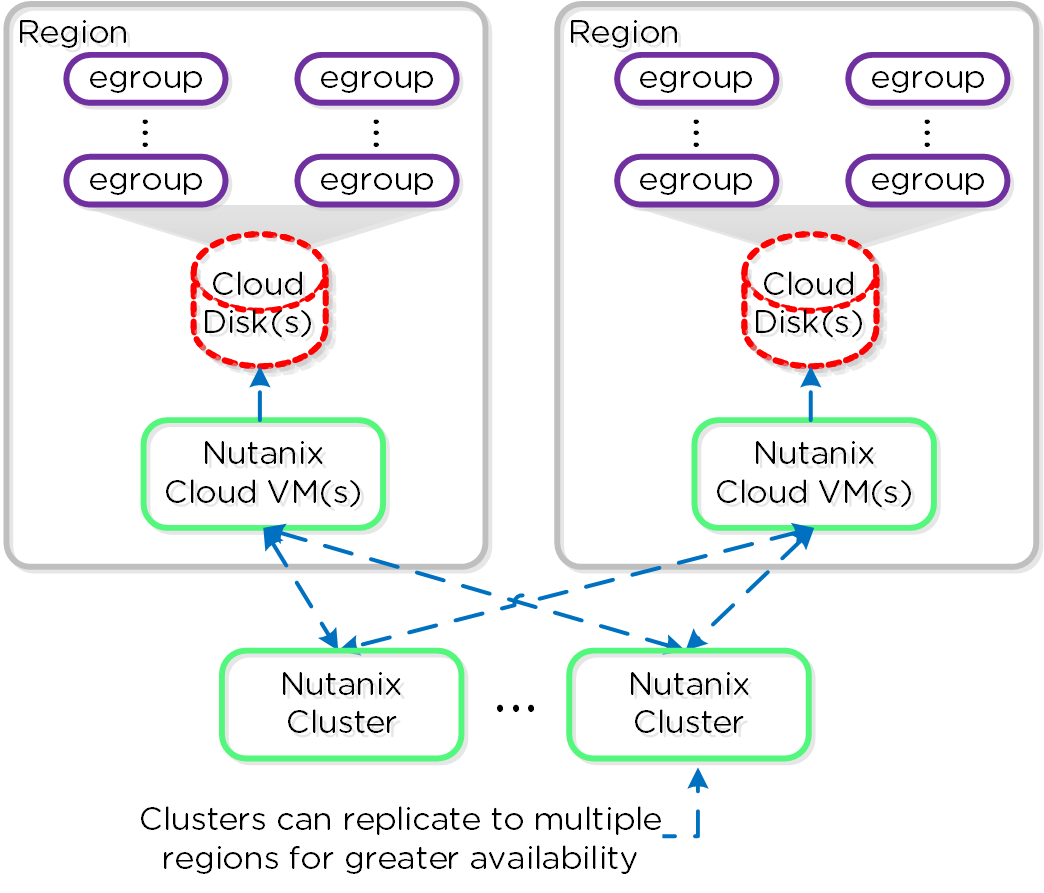
Те же политики репликации и хранения используются для репликации данных с помощью Cloud Connect. По мере устаревания или истечения срока действия данных / моментальных снимков облачный кластер будет очищать данные по мере необходимости.
Если репликация не происходит часто (например, ежедневно или еженедельно), платформа может быть сконфигурирована для включения облачных ВМ до запланированной репликации и выключать их после ее выполнения
Данные, реплицированные в любой облачный регион, также можно извлечь и восстановить в любой существующий или только что созданный кластер Nutanix с настроенными удаленными облачными узлами:
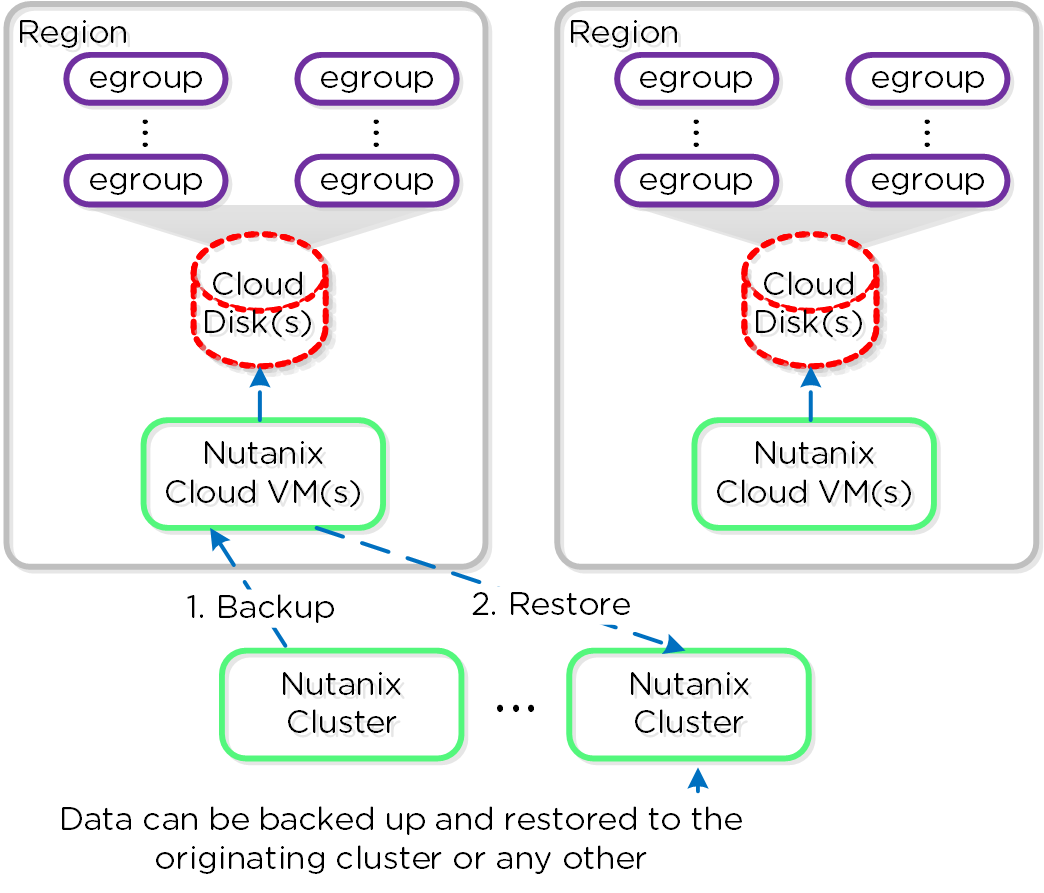
Подсистема мобильности приложений
В ближайшее время этот раздел будет обновлен!
Администрирование
Важные страницы
Ниже перечислены важные технологические страницы интерфейса Nutanix. Они позволяют получить детальную статистику по нагрузке и другую служебную информацию. Все URL формируются следующим образом: http://<Nutanix CVM IP/DNS>:<Port/path (mentioned below)> Например: http://MyCVM-A:2009 Примечание: если вы находитесь в другой подсети, IPtables должен быть отключен на CVM для доступа к страницам.
2009
Это служебная страница сервиса Stargate, которая позволяет получить данные о работе с данными, должна использоваться только опытными пользователями.
2009/latency
Это служебная страница сервиса Stargate, которая предоставляет данные по задержкам при работе с данными.
2009/vdisk_stats
Это служебная страница сервиса Stargate, которая предоставляет данные по работе с файлами, включая размер операций I/O, задержки, количество операций записи (e.g., OpLog, eStore), количество операций чтения (cache, SSD, HDD.) и так далее.
2009/h/traces
Это служебная страница сервиса Stargate, используемая для отслеживания операций.
2009/h/vars
Это служебная страница сервиса Stargate, используемая для мониторинга различных счетчиков.
2010
Это служебная страница сервиса Curator, используемая для мониторинга работы Curator.
2010/master/control
Это служебная страница сервиса Curator, используемая для ручного запуска заданий сервиса Curator.
2011
Это служебная страница сервиса Chronos, используемая для мониторинга задач назначенных сервисом Curator.
2020
Это служебная страница сервиса Cerebro, используемая для мониторинга статуса доменов защиты, операций репликаций и DR.
2020/h/traces
Это служебная страница сервиса Cerebro, используемая для мониторинга текущего статуса операций доменов защиты и репликаций.
2030
Это основная служебная страница Acropolis, отображает информацию о узлах, текущих задачах и сетевых настройках.
2030/sched
Информационная страница Acropolis, отображает информацию о ВМ, распределении нагрузки между узлами. Страница отображает информацию о доступных ресурсах узлов и ВМ запущенных на них.
2030/tasks
Информационная страница Acropolis, отображает информацию о статусах задач. Вы можете нажать на любой UUID задачи, для получения детальной информации в формате JSON.
2030/vms
Информационная страница Acropolis, отображает информацию о статусах ВМ. Вы можете нажать на имя ВМ для подключения к ее консоли.
Команды управления кластером
Проверка статуса кластера
Описание: Проверка статуса кластера из CLI
cluster status
Проверка статуса CVM
Описание: Проверка статуса CVM из CLI
genesis status
Проверка статуса обновления
upgrade_status
Проверка статуса обновления узлов
Проверка статуса обновления гипервизора
Описание: Проверка статуса обновления гипервизора из CLI на любой CVM
host_upgrade_status
Детальный журнальный файл (на каждой CVM)
~/data/logs/host_upgrade.out
Перезапуск сервисов кластера из CLI
Описание: Перезапуск сервисов кластера из CLI
Остановка сервисов
cluster stop <Service Name>
Запуск остановленных сервисов
cluster start #Примечание: Запустятся все остановленные сервисы
Запуск сервисов кластера из CLI
Описание: Start stopped cluster services from the CLI
Запуск остановленных сервисов
cluster start #Примечание: Все остановленные сервисы будут запущены
или
Запуск выделенного сервиса
Запуск конкретного сервиса: cluster start <Service Name>
Перезапуск локальных сервисов из CLI
Описание: Перезапуск одного из локальных сервисов кластера из CLI
Остановка сервиса
genesis stop <Service Name>
Запуск сервиса
cluster start
Запуск локальных сервисов из CLI
Описание: Запуск остановленных сервисов кластера из CLI
cluster start #Примечание: команда запустит все остановленные сервисы
Добавление узла через cmdline
Описание: добавление узла в кластер из CLI
ncli cluster discover-nodes | egrep "Uuid" | awk '{print $4}' | xargs -I UUID ncli cluster add-node node-uuid=UUID
Отображение id кластера
Описание: Показать ID текущего кластера
zeus_config_printer | grep cluster_id
Открытие порта
Описание: Открытие порта через IPtables
sudo vi /etc/sysconfig/iptables
-A INPUT -m state --state NEW -m tcp -p tcp --dport <PORT> -j ACCEPT
sudo service iptables restart
Проверка Теневых копий
Описание: Отображение Теневых копий в формате: name#id@svm_id
vdisk_config_printer | grep '#'
Сброс статистики по задержкам
Описание: Сброс данных о задержках (<CVM IP>:2009/latency)
allssh "wget 127.0.0.1:2009/latency/reset"
Отображение информации о vDisk
Описание: Отображение информации о vDisk, включая информацию о имени, id, размере, iqn и так далее
vdisk_config_printer
Отображение количества объектов на РХД (vDisks)
Описание: Отображения количество существующих на данный момент объектов на РХД
vdisk_config_printer | grep vdisk_id | wc -l
Получение детально информации о vDisk
Описание: Отображение ID egroup vDisks-ов, размер, преобразование данных и экономию пространства, размещение реплик и так далее
vdisk_usage_printer -vdisk_id=<VDISK_ID>
Запуск сканирования сервиса Curator через CLI
Описание: Запуск сканирования сервиса Curator через CLI
# Полное сканирование
allssh "wget -O - "http://localhost:2010/master/api/client/StartCuratorTasks?task_type=2";"
# Частичное сканирование
allssh "wget -O - "http://localhost:2010/master/api/client/StartCuratorTasks?task_type=3";"
# Обновление информации
allssh "wget -O - "http://localhost:2010/master/api/client/RefreshStats";"
Проверка реплицируемых данных через CLI
Описание: Проверка реплицируемых данных при помощи curator_cli
curator_cli get_under_replication_info summary=true
Сжатие кольца метаданных
Описание: Сжатие кольца метаданных
allssh "nodetool -h localhost compact"
Отображение версии NOS
Описание: Find the NOS version (Примечание: can also be done using NCLI)
allssh "cat /etc/nutanix/release_version"
Отображение версии CVM
Описание: Find the CVM image version
allssh "cat /etc/nutanix/svm-version"
Ручное снятие хэшей с объектов РХД (vDisk)
Описание: Ручное снятие хэшей с объектов РХД (для дедупликации) Примечание: функция дедупликации должна быть включена для контейнера
vdisk_manipulator –vdisk_id=<vDisk ID> --operation=add_fingerprints
Ручное снятие хэшей всех объектов РХД (vDisk)
Описание: Ручное снятие хэшей всех объектов РХД (для дедупликации) Примечание: функция дедупликации должна быть включена для контейнера
for vdisk in `vdisk_config_printer | grep vdisk_id | awk {'print $2'}`; do vdisk_manipulator -vdisk_id=$vdisk --operation=add_fingerprints; done
Вывод данных Factory_Config.json для всех узлов кластера
Описание: Выводит содержимое factory_config.jscon для всех узлов кластера
allssh "cat /etc/nutanix/factory_config.json"
Обновление версии NOS для конкретного узла кластера
Описание: Обновление версии NOS для конкретного узла кластера
~/cluster/bin/cluster -u <NEW_NODE_IP> upgrade_node
Список объектов (vDisk) на РХД
Описание: Список объектов РХД и информации по ним
Nfs_ls
Вывод справочной информации
Nfs_ls --help
Установка утилит Nutanix Cluster Check (NCC)
Описание: Установка утилиты Nutanix Cluster Check (NCC), которые выполняют тестирование состояния кластера
Загрузка NCC с портала поддержки Nutanix (portal.nutanix.com)
SCP .tar.gz в директорию /home/nutanix
Разархивация NCC .tar.gz
tar xzmf <ncc .tar.gz file name> --recursive-unlink
Запуск скрипта инсталляции
./ncc/bin/install.sh -f <ncc .tar.gz file name>
Создание ссылок
source ~/ncc/ncc_completion.bash
echo "source ~/ncc/ncc_completion.bash" >> ~/.bashrc
Запуск NCC
Описание: Запуск утилиты Nutanix Cluster Check (NCC), которые выполняют тестирование состояния кластера. Это действие должно быть первым этапом диагностики кластера / ПО / оборудования.
Убедитесь, что NCC установлены
Запустите проверки NCC
ncc health_checks run_all
Проверьте статус выполнения задач
progress_monitor_cli -fetchall
Вы можете удалить задачу используя эту же утилиту
progress_monitor_cli --entity_id=<ENTITY_ID> --operation=<OPERATION> --entity_type=<ENTITY_TYPE> --delete
# Примечание: все данные требуется вводить в нижнем регистре, символ k нужно удалить
Показатели и пороговые значения
В следующем разделе будут рассмотрены специфичные метрики и пороговые значения для серверной части Nutanix. Раздел скоро будет обновлен
Gflags
Раздел скоро будет обновлен!
Поиск и устранение неисправностей
Поиск журналов Acropolis
Описание: Поиск журналов Acropolis для кластера
allssh "cat ~/data/logs/Acropolis.log"
Поиск журналов ошибок для кластера
Описание: Поиск журналов ошибок уровня ERROR
allssh "cat ~/data/logs/<COMPONENT NAME or *>.ERROR"
Пример для Stargate
allssh "cat ~/data/logs/Stargate.ERROR"
Поиск журналов фатальных ошибок для кластера
Описание: Поиск журналов ошибок уровня FATAL
allssh "cat ~/data/logs/<COMPONENT NAME or *>.FATAL"
Пример для Stargate
allssh "cat ~/data/logs/Stargate.FATAL"
Using the 2009 Page (Stargate)
В большинстве случаев, Prism должен быть в состоянии дать вам всю необходимую информацию и данные. Однако, в определенных сценариях, или если вам нужны более подробные данные, вы можете использовать страницу Stargate - 2009. Для перехода на данную страницу используйте <IP-адрес CVM>:2009
Примечание
Доступ к внутренним страницам
Если вы находитесь в другом сегменте сети (подсеть L2), вам нужно добавить правило в IPtables для доступа к внутренним страницам.
В верхней части страницы находится общие сведения, которые показывают различные данные о кластере:

В этом разделе есть две ключевые области, на которые я обращаю внимание, первая - очереди ввода-вывода, тут показано количество выполненных/невыполненных операций.
На рисунке показана секция с общими данными:

Вторая часть-это сведения о едином кэше, которые показывают сведения о размерах кэша и частоте обращений.
На рисунке показана секция с данными о едином кэше:

Примечание
Совет от создателей
В идеальных случаях частота обращений должна быть выше 80-90%+, если рабочая нагрузка является большой так обеспечивается наилучшая производительность для чтения.
Примечание: значения указаны для каждого экземпляра Stargate / CVM
Следующий раздел 'Cluster State' - показывает подробные данные о различных Stargates в кластере и уровень использования ими дисков.
На рисунке показаны сервисы Stargates и информация по использованию дисков (доступно/всего):
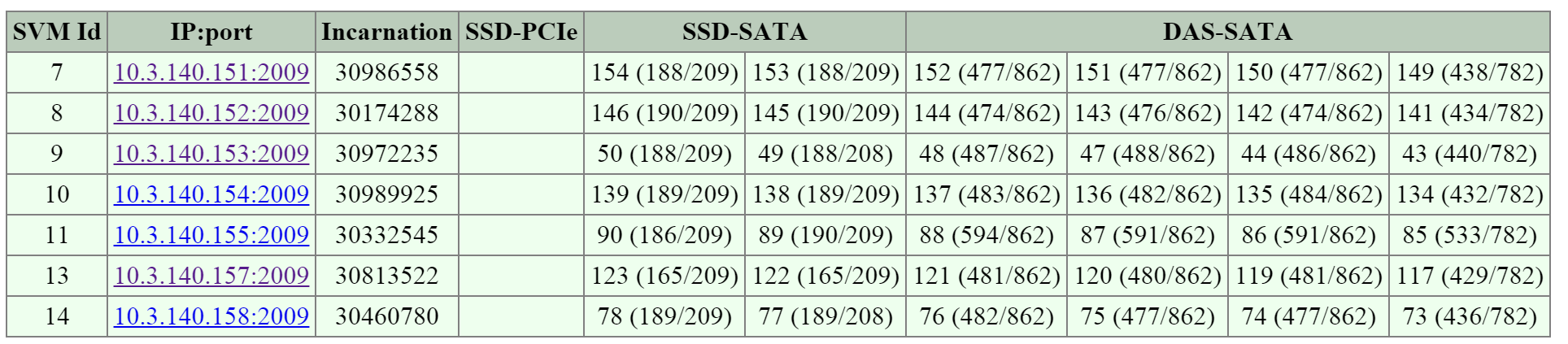
Следующий раздел 'NFS Slave' показывает различную статистику по vDisk.
На рисунке показаны объекты РХД - vDisk и информация по I/O:
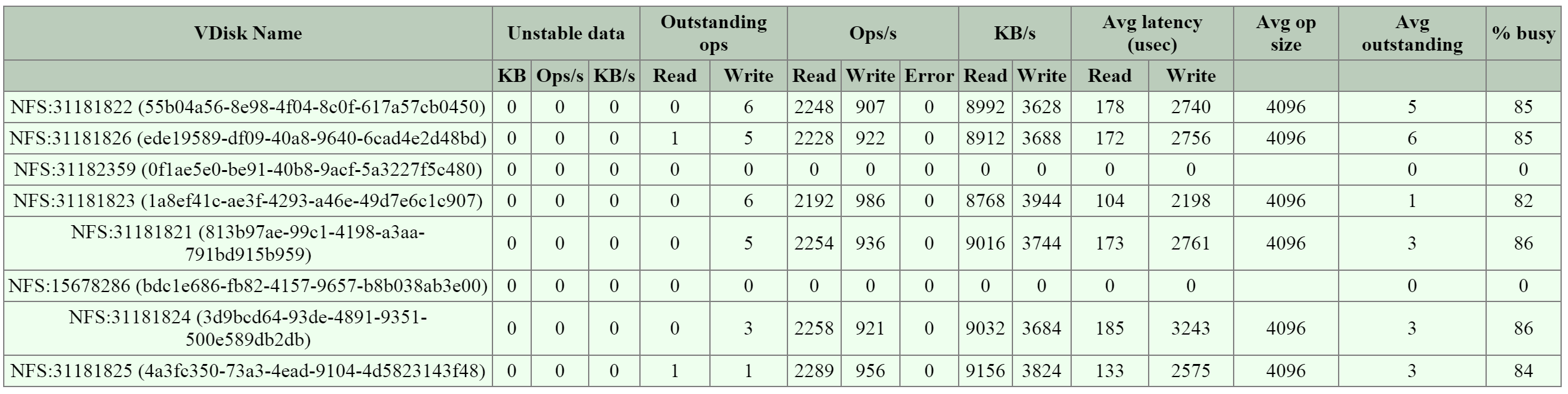
Примечание
Совет от создателей
При рассмотрении любых потенциальных проблем производительности я всегда смотрю на следующее:
- Avg. latency
- Avg. op size
- Avg. outstanding
Страница vdisk_stats содержит более детальную информацию.
Использование страницы 2009/vdisk_stats
Страница 2009 vdisk_stats -это подробная страница, которая предоставляет дополнительные данные для каждого vDisk. Эта страница включает в себя данные о задержках, размерах операций I/O и типах нагрузки.
Вы можете перейти на страницу vdisk_stats, нажав на "vDisk ID" в левом столбце.
На странице показан пример информации по vDisk:
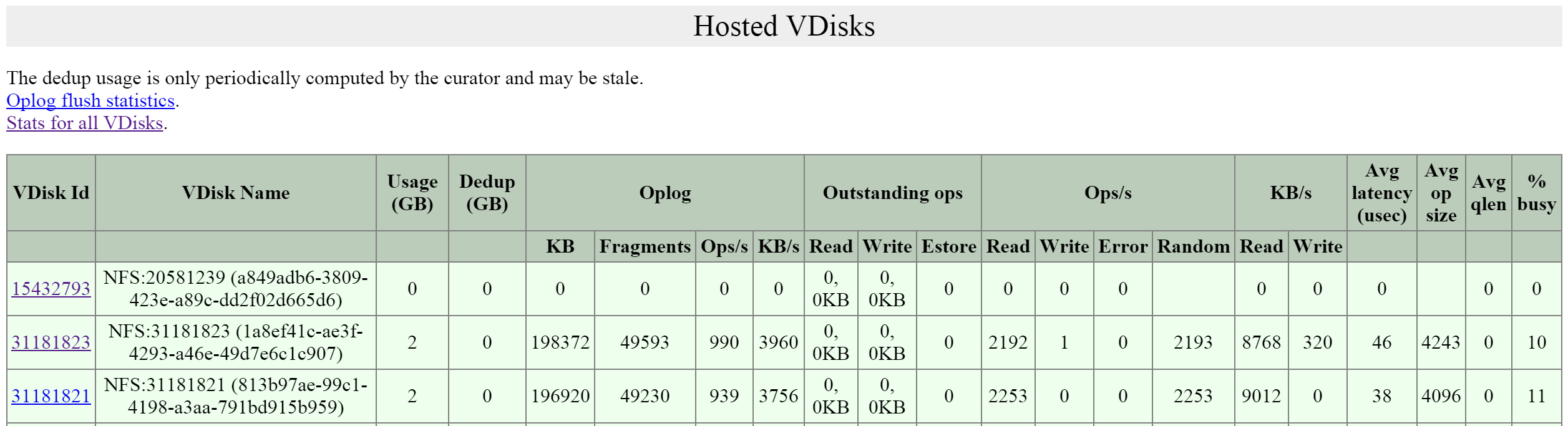
Перейдя на страницу vdisk_stats вы получите доступ ко всем данным статистики по vDisk. Примечание: Данные на странице обновляются в реальном времени, чтобы получить текущие данные - обновите страницу.
Основная секция страницы - 'Ops and Randomness', показывает шаблоны операций I/O - случайные или последовательные.
На рисунке показан пример секции 'Ops and Randomness':
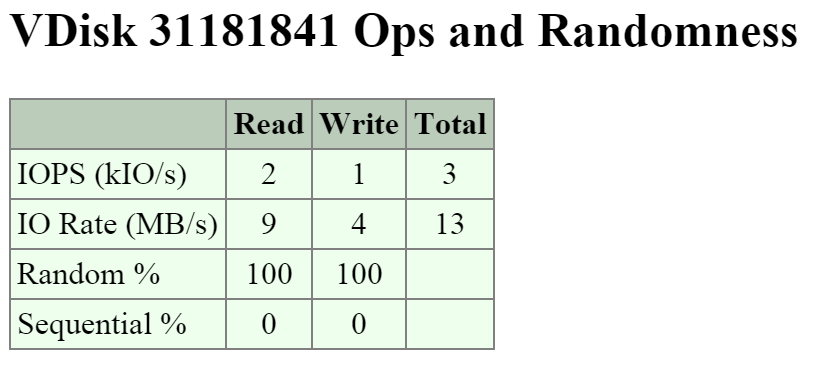
Следующая секция показывает информацию по задержкам при операции чтения и записи от ВМ
На рисунке показан пример секции 'Frontend Read Latency':

На рисунке показан пример секции 'Frontend Write Latency':
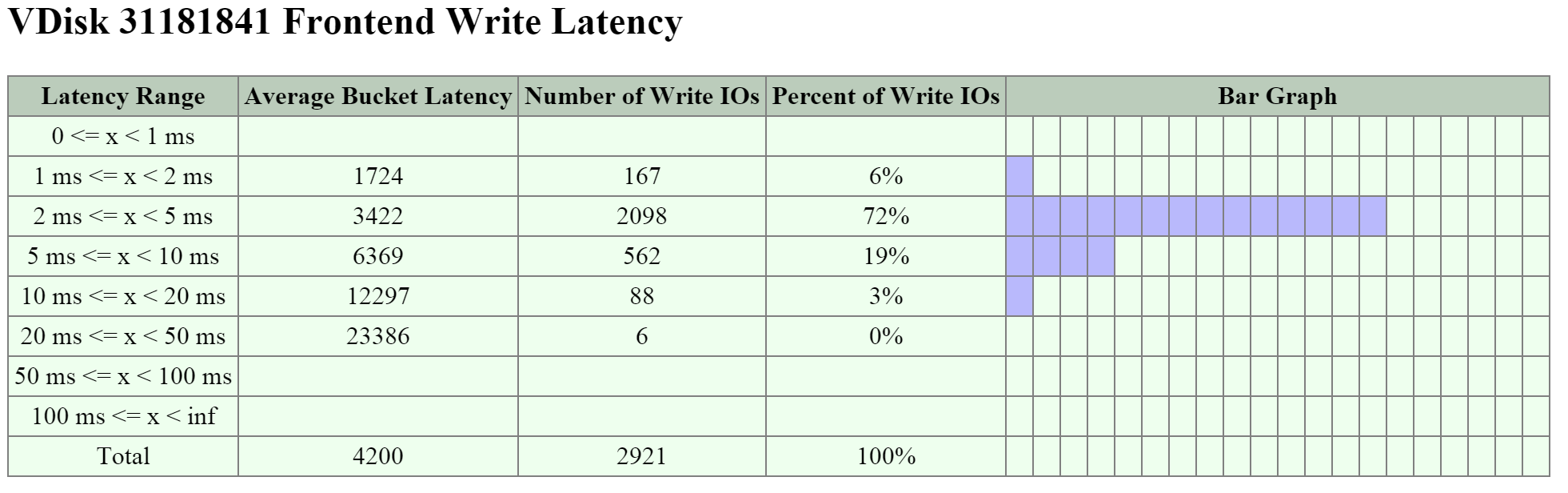
Следующая секция показывает размеры операций I/O.
На рисунке показан пример секции 'Read Size Distribution':
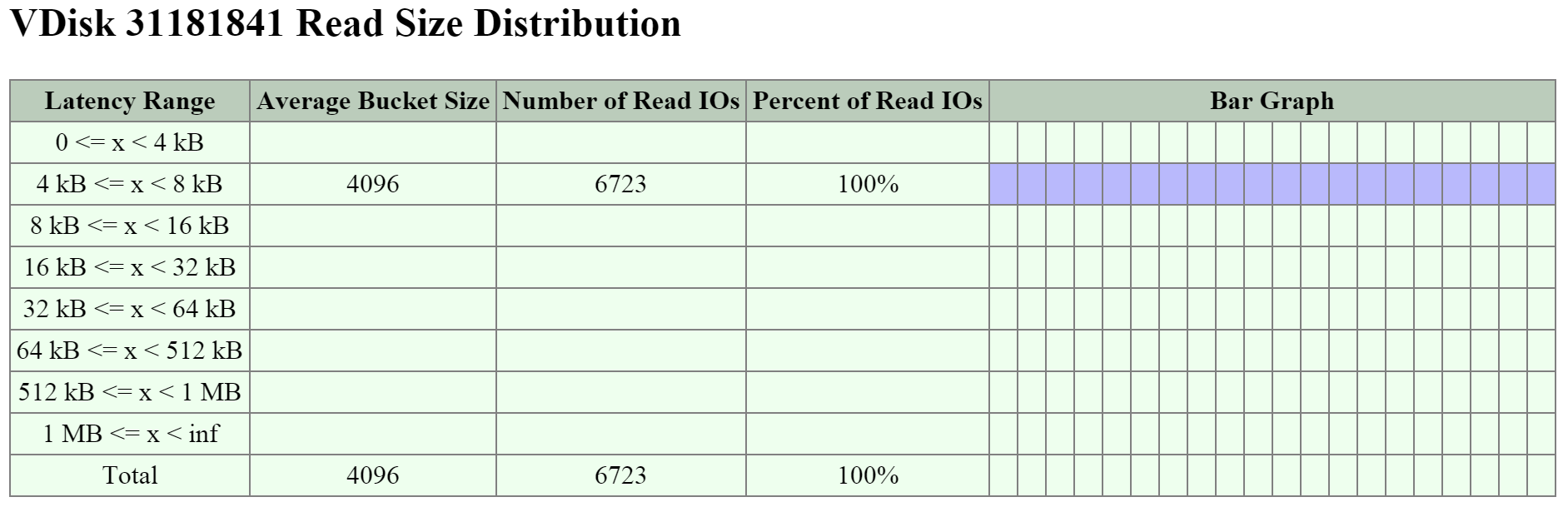
На рисунке показан пример секции 'Write Size Distribution':
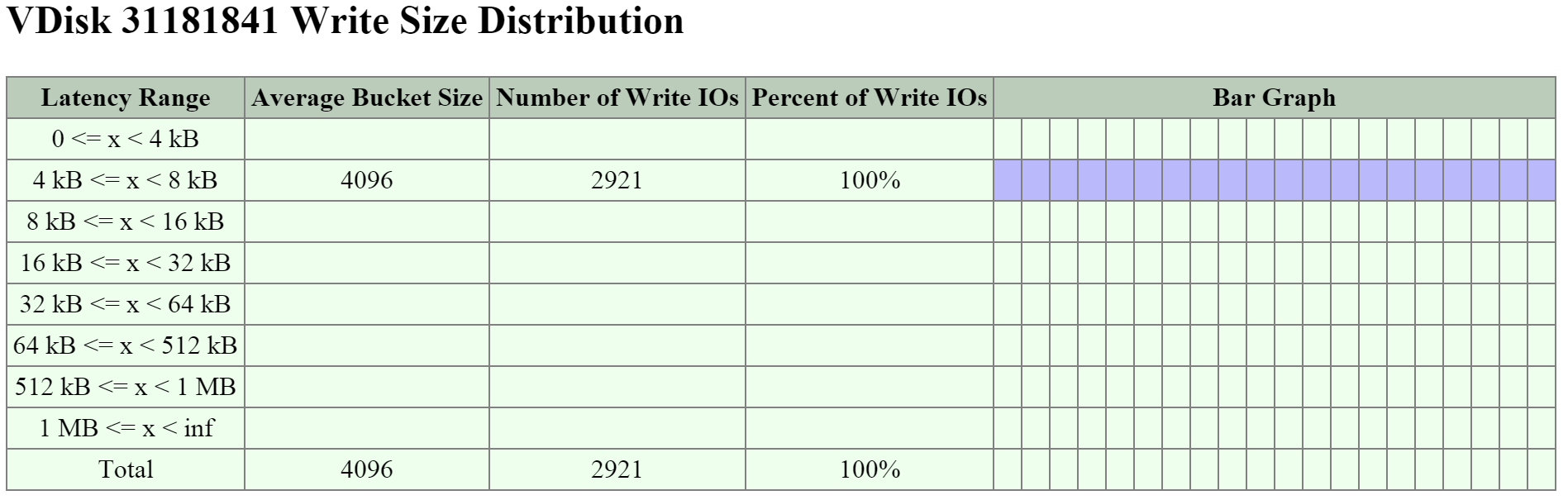
Секция 'Working Set Size' показывает размеры рабочих наборов за последние 2 минуты и 1 час. Информация делится на данные по операциям чтения и записи.
На рисунке показан пример секции 'Working Set Sizes':

Секция 'Read Source' показывает детальную информацию данные из какого уровня хранения исходят обслуживаемые операции I/O.
На рисунке показан пример секции 'Read Source':

Примечание
Совет от создателей
Если вы видите высокие задержки при операциях чтения - обратите внимания, что является источником и где обслуживается данный vDisk. В большинстве случаев, высокие задержки могут возникать при чтении с HDD.
В секции 'Write Destination' показано куда направлены операции записи.
На рисунке показан пример секции 'Write Destination':

Примечание
Совет от создателей
Случайные операции I/O будут записаны в Oplog, последовательные операции I/O будут выполняться напрямую на Хранилище экстентов.
Еще одна интересная точка наблюдения - данные, которые переносятся из HDD на SSD через ILM. Таблица 'Extent Group Up-Migration' показаны данные, которые были перенесены в последние 300, 3,600 и 86,400 секунд.
На рисунке показан пример секции 'Extent Group Up-Migration':
Использование страницы 2010 (Curator)
Страница 2010 предоставляет детальную информацию по работе сервиса Curator. Тут показаны детальные данные по задачам, сканированию и другие связанные задачи.
На страницу можно по пасть по адресу http://<IP-адрес CVM>:2010 Примечание: Если вы попали не на мастер сервис - нажмите ссылку 'Curator Master: '.
В верхней части страницы будет показывать различные подробности о мастер-сервисе Curator в том числе - время работы, версии ПО и т.д.
В секции 'Curator Nodes' показана информация о всех узлах кластера, ролях, состояниях. Это будут узлы Curator, по которым распределяются задачи от мастера.
На рисунке показан пример таблицы 'Curator Nodes':
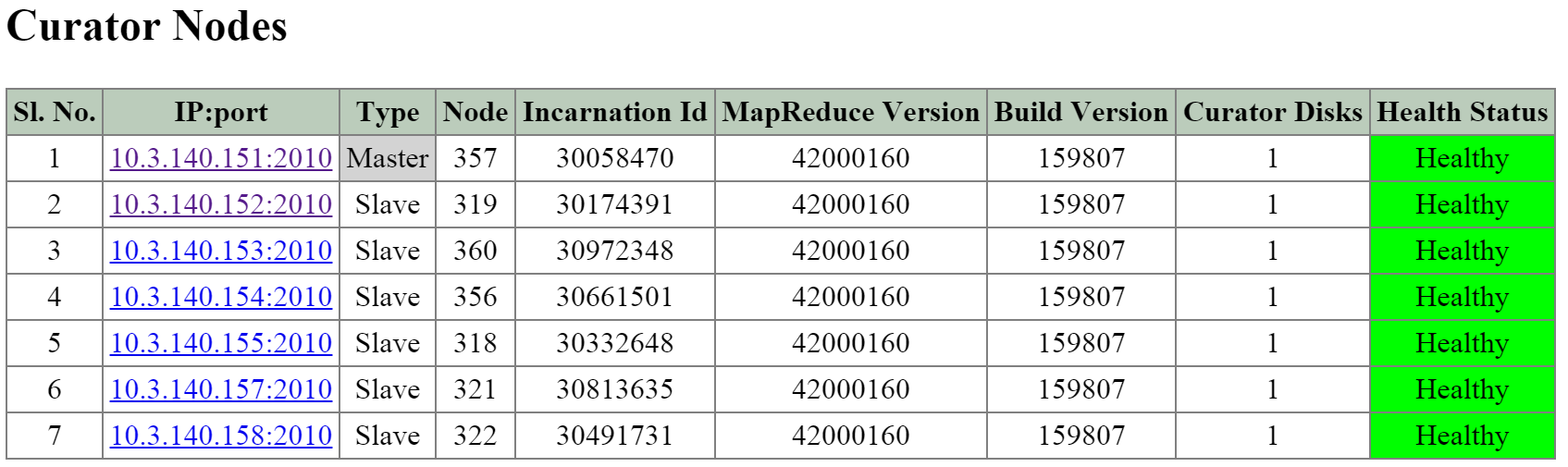
Следующая таблица 'Curator Jobs' покажет выполненные или текущие задачи сервиса.
Есть два основных типа заданий, которые включают частичное сканирование, которое может выполняться каждые 60 минут, и полное сканирование, которое может выполняться каждые 6 часов. Примечание: сроки будут варьироваться в зависимости от загруженности платформы и так далее.
Сканирование будет выполняться периодически по расписанию, но может быть вызвано и событием кластера.
Вот некоторые события, которые могут вызывать сканирование:
- Периодическое сканирование (обычное состояние)
- Сбой диска / узла / блока
- Дисбаланс ILM
- Дисбаланс дисков / уровней хранения
На рисунке показан пример таблицы 'Curator Jobs':
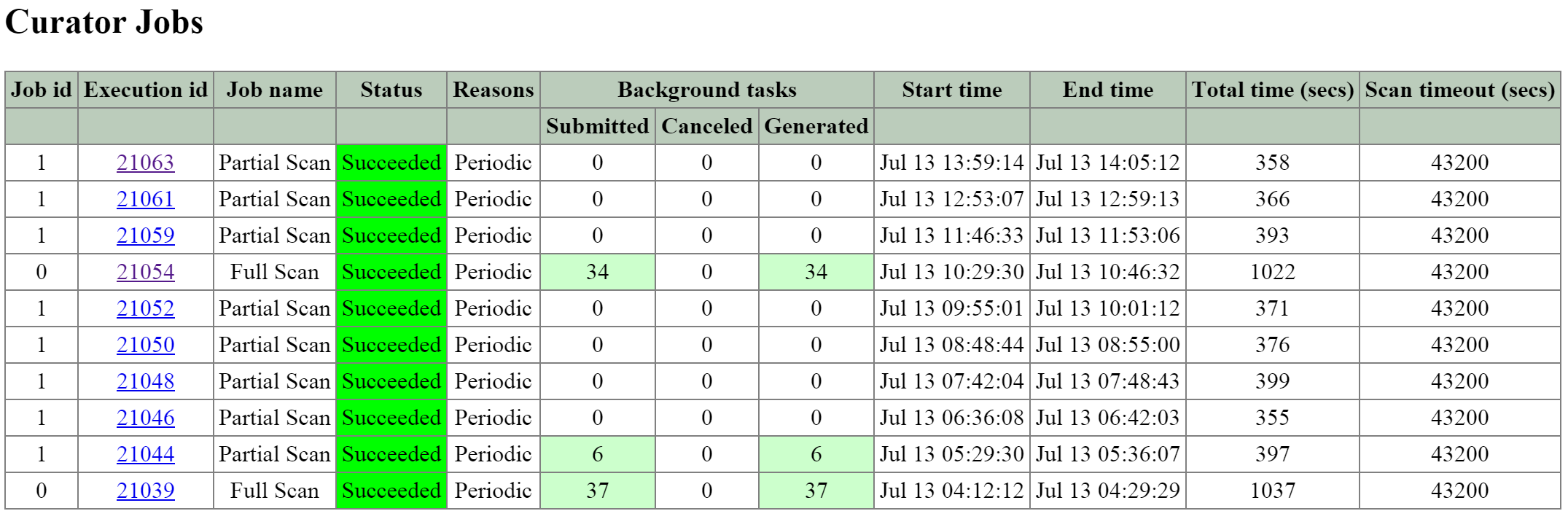
В таблице показаны некоторые высокоуровневые действия, выполняемые в рамках задач:
| Активность | Полное сканирование | Частичное сканирование |
|---|---|---|
| ILM | X | X |
| Disk Balancing | X | X |
| Компрессия | X | X |
| Дедупликация | X | |
| Избыточное кодирование | X | |
| Очистка мусора | X |
Нажимая на 'Execution id' вы можете попасть на страницу с детальными данными по задачам.
В верхней части страницы отображаются различные сведения о задании, включая тип и причину задачи, продолжительность выполнения.
В таблице "Background Task Stats" отображаются различные сведения о типе задач, их количестве и приоритете.
На рисунке показан пример таблицы:
На рисунке показан пример таблицы 'Background Task Stats':
В таблице 'MapReduce Jobs' показаны актуальные задачи MapReduce запущенные каждым сервисом Curator. Частичное сканирование - это одна задача MapReduce, полное сканирование запустит четыре задач MapReduce.
На рисунке показан пример таблицы 'MapReduce Jobs':
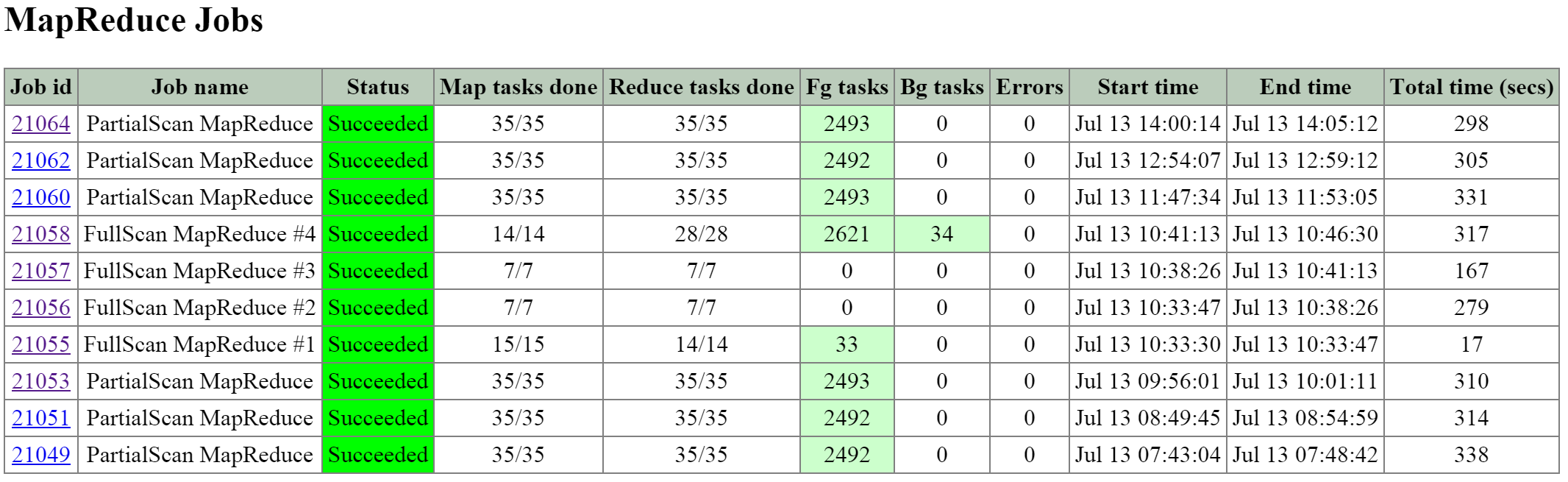
При нажатии на 'Job id' вы перейдете на страницу с детальной информацией о задачах MapReduce. Тут будет показан статус задач, различные счетчики и другие подробные данные.
На рисунке показан пример некоторых счетчиков:
Следующая часть страницы содержит секции 'Queued Curator Jobs' и 'Last Successful Curator Scans'. Таблицы показывают Эти таблицы показывают, когда задачи периодического сканирования будут запущены и информация по последнему успешному сканированию.
На рисунке показаны секции 'Queued Curator Jobs' и 'Last Successful Curator Scans':
Расширенная информация CLI
Интерфейс Prism обеспечивает всей необходимой информацией для устранения неполадок и мониторинга производительности. Однако, могут быть случаи, где вы хотите получить более подробную информацию, которая имеется на служебных страницах, упомянутых выше, или через CLI.
vdisk_config_printer
Команда vdisk_config_printer покажет информацию по всем vdisk в кластере.
Я выделил некоторые важные поля для вывода данной команды:
- Vdisk ID
- Vdisk name
- Parent vdisk ID (if clone or snapshot)
- Vdisk size (Bytes)
- Container id
- To remove bool (to be cleaned up by curator scan)
- Mutability state (mutable if active r/w vdisk, immutable if snapshot)
Ниже приведен пример вывода команды:
nutanix@NTNX-13SM35210012-A-CVM:~$ vdisk_config_printer | more ... vdisk_id: 1014400 vdisk_name: "NFS:1314152" parent_vdisk_id: 16445 vdisk_size: 40000000000 container_id: 988 to_remove: true creation_time_usecs: 1414104961926709 mutability_state: kImmutableSnapshot closest_named_ancestor: "NFS:852488" vdisk_creator_loc: 7 vdisk_creator_loc: 67426 vdisk_creator_loc: 4420541 nfs_file_name: "d12f5058-f4ef-4471-a196-c1ce8b722877" may_be_parent: true parent_nfs_file_name_hint: "d12f5058-f4ef-4471-a196-c1ce8b722877" last_modification_time_usecs: 1414241875647629 ...
vdisk_usage_printer -vdisk_id=<VDISK ID>
Команда vdisk_usage_printer предоставляет детальную информацию по vdisk, его экстентам extents и egroups.
Я выделил некоторые важные поля для вывода данной команды:
- Egroup ID
- Egroup extent count
- Untransformed egroup size
- Transformed egroup size
- Transform ratio
- Transformation type(s)
- Egroup replica locations (disk/cvm/rack)
Ниже приведен пример вывода команды:
nutanix@NTNX-13SM35210012-A-CVM:~$ vdisk_usage_printer -vdisk_id=99999 Egid # eids UT Size T Size ... T Type Replicas(disk/svm/rack) 1256878 64 1.03 MB 1.03 MB ... D,[73 /14/60][184108644 /184108632/60] 1256881 64 1.03 MB 1.03 MB ... D,[73 /14/60][152 /7/25] 1256883 64 1.00 MB 1.00 MB ... D,[73 /14/60][184108642 /184108632/60] 1055651 4 4.00 MB 4.00 MB ... none[76 /14/60][184108643 /184108632/60] 1056604 4 4.00 MB 4.00 MB ... none[74 /14/60][184108642 /184108632/60] 1056605 4 4.00 MB 4.00 MB ... none[73 /14/60][152 /7/25] ...
Примечание: Обратите внимание на размер egroup, дедупликация против ее отсутствия (1 против 4MB). Как упоминалось в разделе 'Data Structure' для дедуплицированных данных, размер 1MB для egroup используется для исключения проблем с фрагментацией, которые могут появляться в связи с дедупликацией данных.
curator_cli display_data_reduction_report
Команда curator_cli display_data_reduction_report возвращает детальную информацию о сокращении расхода емкости хранилища для каждого контейнера
Я выделил некоторые важные поля для вывода данной команды:
- Container ID
- Technique (transform applied)
- Pre reduction Size
- Post reduction size
- Saved space
- Savings ratio
Ниже приведен пример вывода команды:
nutanix@NTNX-13SM35210012-A-CVM:99.99.99.99:~$ curator_cli display_data_reduction_report Using curator master: 99.99.99.99:2010 E0404 13:26:11.534024 26791 rpc_client_v2.cc:676] RPC connection to 127.0.0.1:9161 was reset: Shutting down Using execution id 68188 of the last successful full scan +--------------------------------------------------------------------------------------+ | Container Id | Technique | Pre Reduction | Post Reduction | Saved | Ratio | +--------------------------------------------------------------------------------------+ | 988 | Clone | 4.88 TB | 2.86 TB | 2.02 TB | 1.70753 | | 988 | Snapshot | 2.86 TB | 2.22 TB | 656.92 GB | 1.28931 | | 988 | Dedup | 2.22 TB | 1.21 TB | 1.00 TB | 1.82518 | | 988 | Compression | 1.23 TB | 1.23 TB | 0.00 KB | 1 | | 988 | Erasure Coding | 1.23 TB | 1.23 TB | 0.00 KB | 1 | | 26768753 | Clone | 764.26 GB | 626.25 GB | 138.01 GB | 1.22038 | | 26768753 | Snapshot | 380.87 GB | 380.87 GB | 0.00 KB | 1 | | 26768753 | Dedup | 380.87 GB | 380.87 GB | 0.00 KB | 1 | | 26768753 | Compression | 383.40 GB | 383.40 GB | 0.00 KB | 1 | | 26768753 | Erasure Coding | 383.40 GB | 245.38 GB | 138.01 GB | 1.56244 | | 84040 | Clone | 843.53 GB | 843.53 GB | 0.00 KB | 1 | | 84040 | Snapshot | 741.06 GB | 741.06 GB | 0.00 KB | 1 | | 84040 | Dedup | 741.06 GB | 741.06 GB | 0.00 KB | 1 | | 84040 | Compression | 810.44 GB | 102.47 GB | 707.97 GB | 7.9093 | ... +---------------------------------------------------------------------------------------------+ | Container Id | Compression Technique | Pre Reduction | Post Reduction | Saved | Ratio | +---------------------------------------------------------------------------------------------+ | 84040 | Snappy | 810.35 GB | 102.38 GB | 707.97 GB | 7.91496 | | 6853230 | Snappy | 3.15 TB | 1.09 TB | 2.06 TB | 2.88713 | | 12199346 | Snappy | 872.42 GB | 109.89 GB | 762.53 GB | 7.93892 | | 12736558 | Snappy | 9.00 TB | 1.13 TB | 7.87 TB | 7.94087 | | 15430780 | Snappy | 1.23 TB | 89.37 GB | 1.14 TB | 14.1043 | | 26768751 | Snappy | 339.00 MB | 45.02 MB | 293.98 MB | 7.53072 | | 27352219 | Snappy | 1013.88 MB | 90.32 MB | 923.55 MB | 11.2253 | +---------------------------------------------------------------------------------------------+
curator_cli get_vdisk_usage lookup_vdisk_ids=<COMMA SEPARATED VDISK ID(s)>
Команда curator_cli display_data_reduction_report возвращает детальную информацию о сокращении расхода емкости хранилища для vDisk
Я выделил некоторые важные поля для вывода данной команды:
- Vdisk ID
- Exclusive usage (Data referred to by only this vdisk)
- Logical uninherited (Data written to vdisk, may be inherited by a child in the event of clone)
- Logical dedup (Amount of vdisk data that has been deduplicated)
- Logical snapshot (Data not shared across vdisk chains)
- Logical clone (Data shared across vdisk chains)
Ниже приведен пример вывода команды:
Using curator master: 99.99.99.99:2010 VDisk usage stats: +------------------------------------------------------------------------------------------------------+ | VDisk Id | Exclusive usage | Logical Uninherited | Logical Dedup | Logical Snapshot | Logical Clone | +------------------------------------------------------------------------------------------------------+ | 254244142 | 596.06 MB | 529.75 MB | 6.70 GB | 11.55 MB | 214.69 MB | | 15995052 | 599.05 MB | 90.70 MB | 7.14 GB | 0.00 KB | 4.81 MB | | 203739387 | 31.97 GB | 31.86 GB | 243.09 MB | 0.00 KB | 4.72 GB | | 22841153 | 147.51 GB | 147.18 GB | 0.00 KB | 0.00 KB | 0.00 KB | ...
curator_cli get_egroup_access_info
Команда curator_cli get_egroup_access_info используется для получения подробной информации о количестве egroups в каждом сегменте на основе последнего чтения / записи. Эта информация может быть использована для оценки количества групп, которые могут быть подходящими кандидатами для использования избыточного кодирования.
Я выделил некоторые важные поля для вывода данной команды:
- Container ID
- Access \ Modify (secs)
Ниже приведен пример вывода команды:
Using curator master: 99.99.99.99:2010 Container Id: 988 +----------------------------------------------------------------------------------------------------------------------------------------+ | Access \ Modify (secs) | [0,300) | [300,3600) | [3600,86400) | [86400,604800) | [604800,2592000) | [2592000,15552000) | [15552000,inf) | +----------------------------------------------------------------------------------------------------------------------------------------+ | [0,300) | 345 | 1 | 0 | 0 | 0 | 0 | 0 | | [300,3600) | 164 | 817 | 0 | 0 | 0 | 0 | 0 | | [3600,86400) | 4 | 7 | 3479 | 7 | 6 | 4 | 79 | | [86400,604800) | 0 | 0 | 81 | 7063 | 45 | 36 | 707 | | [604800,2592000) | 0 | 0 | 15 | 22 | 3670 | 83 | 2038 | | [2592000,15552000) | 1 | 0 | 0 | 10 | 7 | 35917 | 47166 | | [15552000,inf) | 0 | 0 | 0 | 1 | 1 | 3 | 144505 | +----------------------------------------------------------------------------------------------------------------------------------------+ ...